fork函数
在linux中fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);
返回值:
- 子进程中返回0
- 父进程返回子进程id
- 出错返回-1
那么为什么要这样设返回值呢?
- 将子进程id返回给父进程:原因很简单,一个父亲可以有多个儿子,所以儿子很容易就能找到父亲(调用getppid()),但父亲很难找到所有的儿子,没有一个函数使一个进程可以获得所有子进程的Id。
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程。
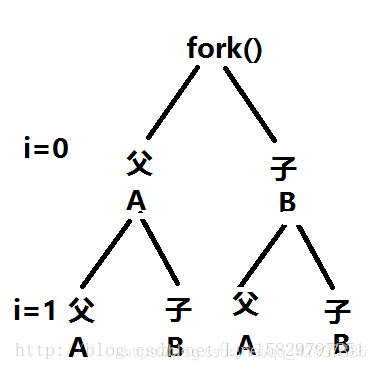
int main()
{
int i;
for(i=0;i<2;i++)
{
if(fork()==0)
{
printf("A\n");
}
else
{
printf("B\n");
}
}
}
fork 之后会产生父子进程,相当于父进程拷贝了一份给子进程,其中包括缓冲区中的数据。对于fork之后的代码会继续执行.。所以结果是三个A,三个B。
int main()
{
int i;
for(i=0;i<2;i++)
{
if(fork()==0)
{
printf("A");
}
else
{
printf("B");
}
}
}
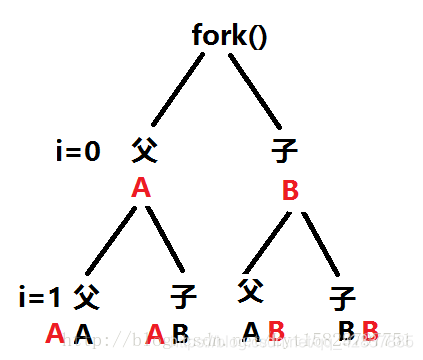
- fork之后,i=0,产生父子进程,没有遇到\n,程序也没有结束,那么父进程得到的A和子进程得到的B都会在缓冲区先呆着,i=1时,又fork一次,父子进程会把自己的在拷贝一份给他们各自的子进程,那么拷贝的时候就包含了呆在缓冲区里的东西,所以i=2,程序结束,输出缓冲区里的东西,就是4个A,4个B
- fork之后父子进程谁先执行完全由调度器来决定。
- 注意:
- 第二个代码中的printf 语句中没有了 \n,这涉及到printf输出缓冲区的问题,缓冲区中的数据只有在以下几种可能会输出:① 遇到\n ② fflush(stdout) 刷新缓冲区 ③程序结束(exit或return)④ 缓冲区满。( 注意:_exit 程序结束时不刷新缓冲区 )
写时拷贝
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自一份副本。(类似C++String类中的写时拷贝)
fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
- 一个进程要执行一个不同的程序。例如子进程从fork返回后,调用exec函数。
fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
