一、链表概述
- 链表是Linux内核中最简单、最普通的数据结构
- 链表是一种存放和操作可变数量元素(常称为节点)的数据结构。链表和静态数组的不同之处在于,它所包含的元素都是动态创建并插入链表的,在编译时不必知道具体需要创建多少个元素。另外也因为链表中每个元素的创建时间各不相同,所以它们在内存中无须占用连续内存区。正是因为元素不连续地存放,所以各元素需要通过某种方式被连接在一起。于是每个元素都包含一个指向下一个元素的指针,当有元素加入链表或从链表中删除元素时,简单调整指向下一个节点的指针就可以了
二、链表的种类
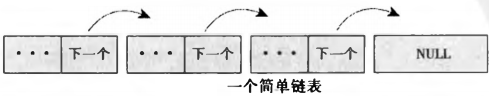
单向链表
/* 一个链表中的一个元素 */
struct list_element {
void *data; /* 有效数据 */
struct list_element *next; /* 指向下一个元素的指针 */
};
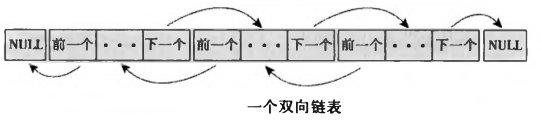
双向链表
/* 一个链表中的一个元素 */
struct list_element {
void *data; /* 有效数据 */
struct list_element *next; /* 指向下一个元素的指针 */
struct list_element *prev; /* 指向前一个元素的指针 */
};
环形链表

三、Linux内核链表的实现
- 相比普遍的链表实现方式,Linux内核的实现可以说独树一帜
- Linux内核方式与众不同,它不是将数据结构塞入链表 ,而是将链表节点塞入数据结构
Linux的链表数据结构(list_head)
- 在过去,内核中有许多链表的实现,该选一个既简单、又高效的链表来统一它们了。 在 2.1 内核开发系列中,首次引入了官方内核链表实现。从此内核中的所有链表现在都使用官方的链表实现了
- 链表代码定义于list.h头文件中,格式如下:
- next:指向下一个链表节点
- prev:指向前一个链表节点
//以下代码来自于Linux 2.6.22/include/linux/list.h
/*
* Simple doubly linked list implementation.
*
* Some of the internal functions ("__xxx") are useful when
* manipulating whole lists rather than single entries, as
* sometimes we already know the next/prev entries and we can
* generate better code by using them directly rather than
* using the generic single-entry routines.
*/
struct list_head {
struct list_head *next, *prev;
};
链表在内核中如何使用
- 如果我们普通的应用程序来表示一个链表中的节点,则其格式如下:
struct fox {
unsigned long tail_length;
unsigned long_weight;
bool is_fantastic;
struct fox *next; //指向后一个节点
struct fox *prev; //指向前一个节点
};
- 但是Linux表示一个节点,则用下面的格式:
- 其中list.next:指向下一个元素
- 其中list.prev:指向前一个元素
struct fox {
unsigned long tail_length;
unsigned long_weight;
bool is_fantastic;
struct list_head list; //所有fox结构体形成地链表
};
container_of()宏
- 使用宏container_of()可以很方便地从链表指针找到父结构中包含的任何变量。这是因为在C语言中,一个给定结构中的变置偏移在编译时地址就被ABI固定下来了

list_entry()宏
- 使用container_of()宏,我们定义一个简单的函数便可返回包含list_head的父类型结构体
- 依靠list_entry()方法,内核提供了创建、操作以及其他链表管理的各种例程——所有这些方法都不需要知道list_head所嵌入对象的数据结构
- 以下代码来自于Linux 2.6.22/include/linux/list.h
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
定义/创建一个链表(LIST_HEAD_INIT)
- 链表需要在使用前初始化。因为多数元素都是动态创建的(也许这就是需要链表的原因),因此最常见的方式是在运行时初始化链表,如下图所示

- 如果一个结构在编译期静态创建,而你需要在其中给出一个链表的直接引用,下面是最简方式:

- 以下代码来自于Linux 2.6.22/include/linux/list.h
#define LIST_HEAD_INIT(name) { &(name), &(name) }
链表头(LIST_HEAD宏)
- 内核链表最突出的特点就是:每一个链表节点中都包含一个list_head指针,于是我们可以从任何一个节点起遍历链表,直到我们看到所有节点
- 以上方式确实很优美,不过有时确实也需要一个特殊指针索引到整个链表,而不从一个链表节点触发。有趣的是,这个特殊的索引节点事实上也就是一个常规的list_head
- LIST_HEAD:该函数定义并初始化了一个链表例程,这些例程中的大多数都只接受一个或者两个参数:头节点或者头节点加上一个特殊链表节点(以下代码来自于Linux 2.6.22/include/linux/list.h)
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
- 例如下面定义并初始化了一个名为fox_list的链表例程,我们下面将介绍对这个例程进行操作的相关函数

四、操作链表(增加、删除、移动)
- 内核提供了一组函数来操作链表,这些函数都要使用一个或多个list_head结构体指针作参数。因为函数都是用C语言以内联函数形式实现的,所以它们的原型在文件<linux.list.h>中
- 下面介绍的函数复杂度都为O(1)。这意味着,无论这些函数操作的链表大小如何,无论它们得到的参数如何,它们都在恒定时间内完成
检查链表是否为空(list_empty)
- 检查指定的链表是否为空,为空的话返回非0值;不为空返回0
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
增加节点(list_add)
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
#else
extern void list_add(struct list_head *new, struct list_head *head);
#endif
- 功能:该函数向指定链表的head节点后插入new节点
- 因为链表是循环的,而且通常没有首尾节点的概念,所以你可以把任何一个节点当成head。如果把“最后”一个节点当做head的话,那么该函数可以用来现一个栈
- 例如:我们创建一个新的struct fox,并将它加入fox_list中:
list_add(&f->list,&fox_list);
增加尾节点(list_add_tail)
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
- 功能:该函数向指定链表的head令点前插入new节点
- 和list_add()函数类似,因为链表是环形的,所以可以把任何一个节点当做head。如果把“第一个”元素当做head的话,那么该函数可以用来实现一个队列
__list_add()函数
- 上面的函数都调用了__list_add,其原型如下
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
删除节点(list_del)
/**
* list_del - deletes entry from list.
* @entry: the element to delete from the list.
* Note: list_empty() on entry does not return true after this, the entry is
* in an undefined state.
*/
#ifndef CONFIG_DEBUG_LIST
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
#else
extern void list_del(struct list_head *entry);
#endif
- 功能:从链表中删除一个结点
- 注意:该函数从链表中删除entry元素。注意,该操作并不会释放entry或释放包含entry的数据结构构体所占用的内存;该函数仅仅将entry元素从链表中移走,所以该函数被调用后,通常还需要再撤销包含entry的数据结构体和其中的entry项
- 例如:删除将f节点从fox_list中删除(注意,该函数并没有接受fox_list作为输入参数。它只是接受一个特定的节点,并修改其前后节点的指针,这样给定的节点就从链表中删除,详情见下面的__list_del源码)
list_del(&f->list);
删除一个节点并重新初始化(list_del_init)
/**
* list_del_init - deletes entry from list and reinitialize it.
* @entry: the element to delete from the list.
*/
static inline void list_del_init(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
- 该函数除了还需要再次初始化entry以外,其他和list_del()函数类似。这样做是因为:虽然链表不再需要entry项,但是还可以再次使用包含entry的数据结构体
__list_del()函数
- 上面的函数都调用了__list_del函数,其源码如下
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
节点的移动(list_move)
- 从一个链表中移除list项,然后将其加入到另一个链表的head节点后面
/**
* list_move - delete from one list and add as another's head
* @list: the entry to move
* @head: the head that will precede our entry
*/
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}
节点的移动(list_move_tail)
- 从一个链表中移除list项,然后将其加入到另一个链表的head节点的前面
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}
链表的合并(list_splice)
- 该函数合并两个链表,将list所指的链表插入到指定链表的head元素后面
/**
* list_splice - join two lists
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head);
}
链表的合并(list_splice_init)
/**
* list_splice_init - join two lists and reinitialise the emptied list.
* @list: the new list to add.
* @head: the place to add it in the first list.
*
* The list at @list is reinitialised
*/
static inline void list_splice_init(struct list_head *list,
struct list_head *head)
{
if (!list_empty(list)) {
__list_splice(list, head);
INIT_LIST_HEAD(list);
}
}
__list_splice
- 上面的list_splice和list_splice_init都用到了此函数,其原型如下:
static inline void __list_splice(struct list_head *list,
struct list_head *head)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
struct list_head *at = head->next;
first->prev = head;
head->next = first;
last->next = at;
at->prev = last;
}
五、遍历链表
- 内核为我们提供了一组非常好的接口,可以用来遍历链表和引用链表中的数据结构体
- 和上面的链表操作函数不同,遍历链表的复杂度为O(n),n是链表所包含的元素数目
基本方法(list_for_each)
- 该宏使用2个参数:
- 参数1:一个临时变量,遍历时用来指向当前项
- 参数2:需要遍历的链表的以头节点形式存在的list_head
- 在遍历链表时,第一个参数在链表中不断移动指向下一个元素,直到链表中的所有元素都被访问为止
/**
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; prefetch(pos->next), pos != (head); \
pos = pos->next)
- 演示案例:例如我们遍历前面的fox_list链表,则可以定义以下的代码
struct list_head *p;
struct fox *f;
list_for_each(p,&fox_list){
//每次返回一个struct fox结构体
//list_entry见上面介绍
f=list_entry(p,struct fox,list);
}
list_for_each_entry()
- 前面的方法虽然确实展示了list_head节点的功效,但并不优美,而且也不够灵活。所以多数内核代码采用list_for_each_entry()宏遍历链表。该宏内部也使用list_entry()宏,但简化了遍历过程
- 参数:
- 参数1:指向包含list_head节点对象的指针,可将它看做是list_entry宏的返回值
- 参数2:head是一个指向头节点的指针,即遍历开始的位置
- 参数3:list_head在结构中的名称
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
- 演示案例:使用list_for_each_entry遍历所有fox节点

- 演示案例:内核文件系统的更新通知机制(来自inotify)
- 该函数遍历了inode->inotify_watched链表中的所有项,每个项的类型都是struct inotify_watch,list_head在结构体中被命名为i_list。循环中的每一次遍历,watc都指向链表的新节点。该函数的目的在于:在inode结构串联起来的inotify_watches链表中,搜寻inotify_handle与所提供的句柄相匹配的inotify_watch项

反向遍历链表(list_for_each_entry_reverse)
- 其和list_for_each_entry类似,不同点在于它是反向遍历链表的。也就是说,不再是沿着next指针向前遍历,而是沿着prev指针向后遍历
- 很多原因会需要反向遍历链表。其中一个是性能原因——如果你知道你要寻找的节点最可能在你搜索的起始点的前面,那么反向搜索岂不更快。第二个原因是如果顺序很重要,比如,如果你使用链表实现堆栈,那么你需要从尾部向前遍历才能达到先进/先 出(LIFO)原则。如果你没有确切的反向遍历的原因,就老实点,用list_for_each_entry()宏吧
/**
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member); \
prefetch(pos->member.prev), &pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
正向遍历的同时删除(list_for_each_entry_safe)
- 标准的链表遍历方法在你遍历链表的同时要想删除节点时是不行的。因为标准的链表方法建 立在你的操作不会改变链表项这一假设上,所以如果当前项在遍历循环中被刪除,那么接下来的遍历就无法获取next(或prev)指针了。这其实是循环处理中的一个常见范式,开发人员通过在潜在的删除操作之前存储next(或者previous)指针到一个临时变量中,以便能执行删除操作。好在Linux内核提供了例程处理这种情况:
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))
- 你可以按照list_for_each_entry()宏的方式使用上述例程,只是需要提供next指针,next指针和pos是同样的类型。list_for_each_entry_safe()启用next指针来将下一项存进表中,以使得能安全删除当前项
- 演示案例:再次看看inotify的例子
- 该函数遍历并删除inotify_watches链表中的所有项 。如果使用了标准的list_for_each_ entry(),那么上述代码会造成“使用一在一释放后”的错误,因为在移向链表中下一项时,需要访问watch,但这时它已经被撤销

反向遍历的同时删除(list_for_each_entry_safe_reverse)
- 该宏与list_for_each_entry_safe相反,是在反向遍历链表的同时删除它
/**
* list_for_each_entry_safe_reverse
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*
* Iterate backwards over list of given type, safe against removal
* of list entry.
*/
#define list_for_each_entry_safe_reverse(pos, n, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member), \
n = list_entry(pos->member.prev, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.prev, typeof(*n), member))
六、总结
- Linux还提供了很多链表操作的方法,可以在<include/linux/list.h>中找到
- 同步和锁:链表的操作有时会遇到并发的问题,同步和锁的概念我们会在后面文章介绍
