1.试述流数据的概念
流数据,即数据以大量、快速、时变的流形式持续到达。
2.试述流数据的特点
流数据具有如下特征:
- 数据快速持续到达,潜在大小也许是无穷无尽的
- 数据来源众多,格式复杂
- 数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储
- 注重数据的整体价值,不过分关注个别数据
- 数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序
4.试述流计算的需求
对于一个流计算系统来说,它应达到如下需求:
-
高性能:处理大数据的基本要求,如每秒处理几十万条数据
-
海量式:支持TB级甚至是PB级的数据规模
-
实时性:保证较低的延迟时间,达到秒级别,甚至是毫秒级别
-
分布式:支持大数据的基本架构,必须能够平滑扩展
-
易用性:能够快速进行开发和部署
-
可靠性:能可靠地处理流数据
7.列举几个常见的流计算框架
目前有三类常见的流计算框架和平台:商业级的流计算平台、开源流计算框架、公司为支持自身业务开发的流计算框架
1.商业级:IBM InfoSphere Streams和IBM StreamBase
2.较为常见的是开源流计算框架,代表如下:
Twitter Storm:免费、开源的分布式实时计算系统,可简单、高效、可靠地处理大量的流数据
Yahoo! S4(Simple Scalable Streaming System):开源流计算平台,是通用的、分布式的、可扩展的、分区容错的、可插拔的流式系统
3.公司为支持自身业务开发的流计算框架:
Facebook Puma
Dstream(百度)
银河流数据处理平台(淘宝)
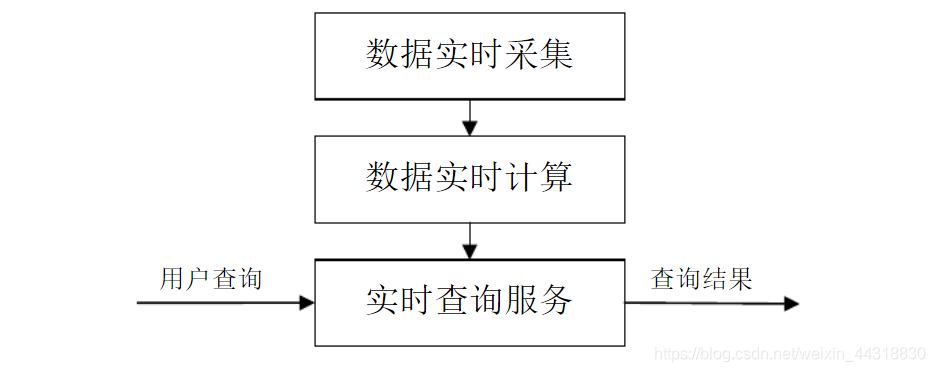
8.试述流计算的一般处理流程
流计算的处理流程一般包含三个阶段:数据实时采集、数据实时计算、实时查询服务
20.试列举几个Storm框架的应用领域
Storm框架可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统
Storm可用于许多领域中,如实时分析、在线机器学习、持续计算、远程RPC、数据提取加载转换等
21.Storm的主要术语包括Streams,Spouts、Bolts、Topology和Stream Groupings,请分别简要描述这几个术语
1.Streams:Storm将流数据Stream描述成一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行地创建和处理
2.Storm框架可以方便地与数据库系统进行整合,从而开发出强大的实时计算系统
3.Bolt:Storm将Streams的状态转换过程抽象为Bolt。Bolt即可以处理Tuple,也可以将处理后的Tuple作为新的Streams发送给其他Bolt
4.Topology:Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提交到Storm集群执行。Topology可视为流转换图,图中节点是一个Spout或Bolt,边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理
5.Topology:Storm将Spouts和Bolts组成的网络抽象成Topology,它可以被提交到Storm集群执行。Topology可视为流转换图,图中节点是一个Spout或Bolt,边则表示Bolt订阅了哪个Stream。当Spout或者Bolt发送元组时,它会把元组发送到每个订阅了该Stream的Bolt上进行处理
22.一个Topolog由哪些组件组成?
Topology里面的每个处理组件(Spout或Bolt)都包含处理逻辑, 而组件之间的连接则表示数据流动的方向。
27.Storm集群中的Master节点和Work节点各自运行什么后台进程?这些进程又分别负责什么工作?
Storm集群采用“Master—Worker”的节点方式:
Master节点运行名为“Nimbus”的后台程序(类似Hadoop中的“JobTracker”),负责在集群范围内分发代码、为Worker分配任务和监测故障
Worker节点运行名为“Supervisor”的后台程序,负责监听分配给它所在机器的工作,即根据Nimbus分配的任务来决定启动或停止Worker进程,一个Worker节点上同时运行若干个Worker进程
28.试述Zookeeper在Storm框架中的作用
Storm使用Zookeeper来作为分布式协调组件,负责Nimbus和多个Supervisor之间的所有协调工作。借助于Zookeeper,若Nimbus进程或Supervisor进程意外终止,重启时也能读取、恢复之前的状态并继续工作,使得Storm极其稳定。
31.试述Storm框架的工作流程
Storm的工作流程如下图所示:

- 所有Topology任务的提交必须在Storm客户端节点上进行,提交后,由Nimbus节点分配给其他Supervisor节点进行处理
- Nimbus节点首先将提交的Topology进行分片,分成一个个Task,分配给相应的Supervisor,并将Task和Supervisor相关的信息提交到Zookeeper集群上
- Supervisor会去Zookeeper集群上认领自己的Task,通知自己的Worker进程进行Task的处理
- 说明:在提交了一个Topology之后,Storm就会创建Spout/Bolt实例并进行序列化。之后,将序列化的组件发送给所有的任务所在的机器(即Supervisor节点),在每一个任务上反序列化组件
