四、Hbase分布式数据库
4.1 简介
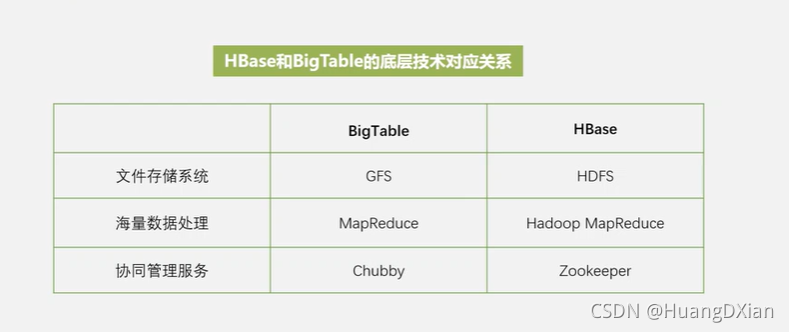
Hbase是bigtable的开源实现
性能好 广泛应用
非结构,半结构化数据库
为什么设计Hbase?
HDFS大规模数据库,关系数据库对于海量数据解决不够有力
关系型数据库更改麻烦
区别和联系
Hbase 数据类型少
Hbase 操作少
Hbase 基于列存储
Hbase访问接口

4.2 Hbase数据模型
稀疏多维度 排列映射表


支持动态扩展,保留旧版本,时间戳
采用四维坐标定位(列族),键值数据库
采用列存储,高效率压缩数据
4.3 Hbase实现原理
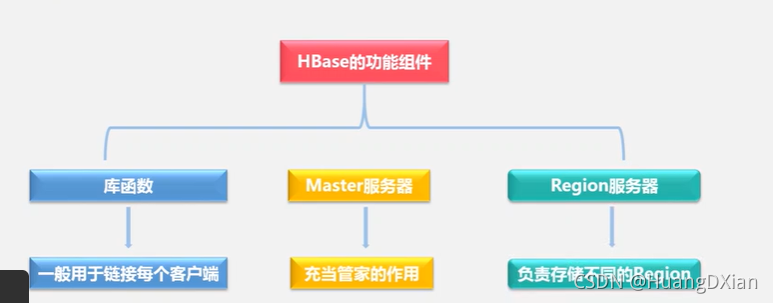

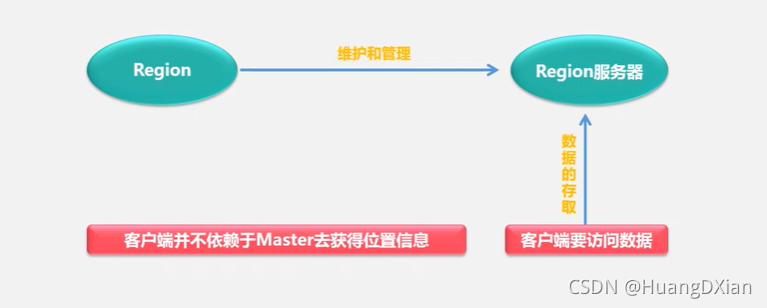
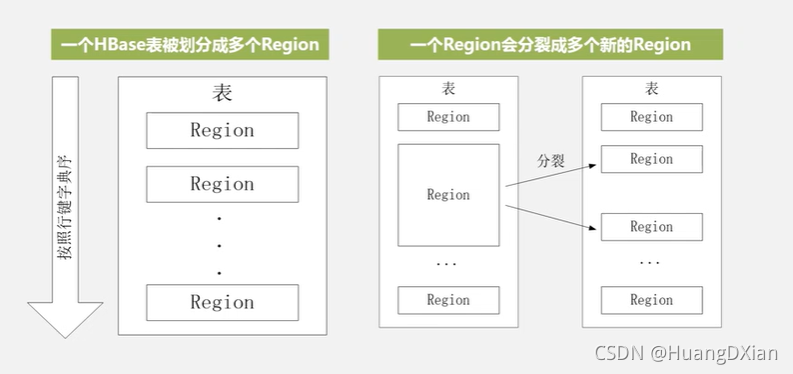
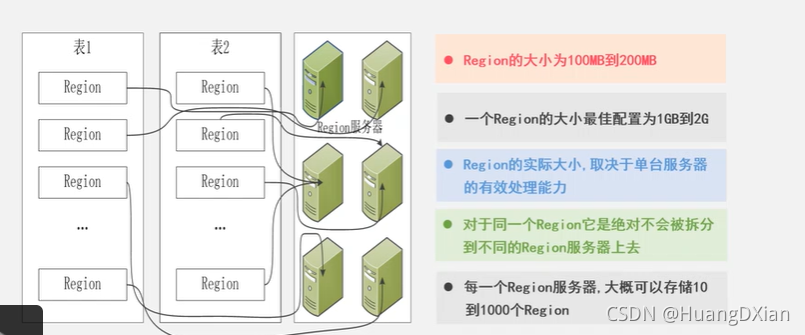
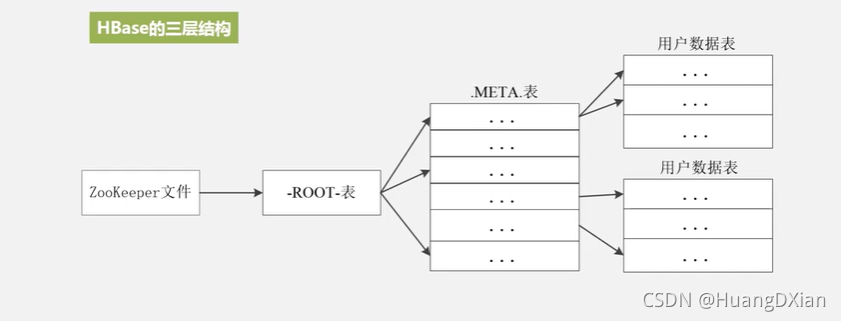
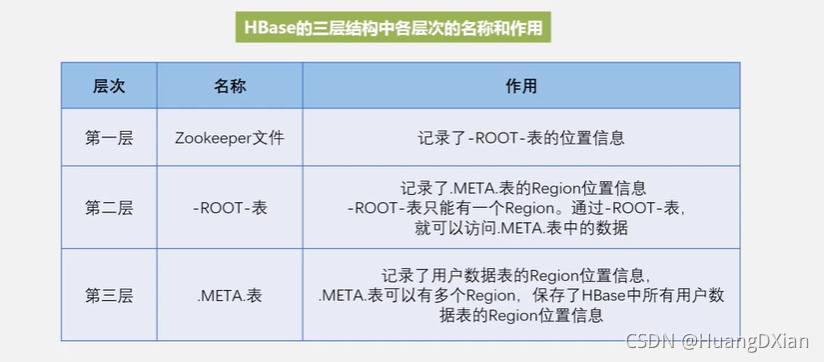

为了加速寻址,需要缓存一些位置信息,同时需要解决缓存失效的问题。
惰性解决失效问题,替换缓存表
4.4 Hbase运行机制

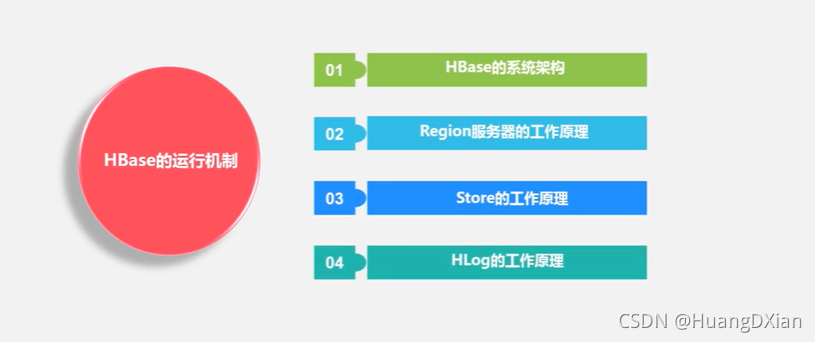
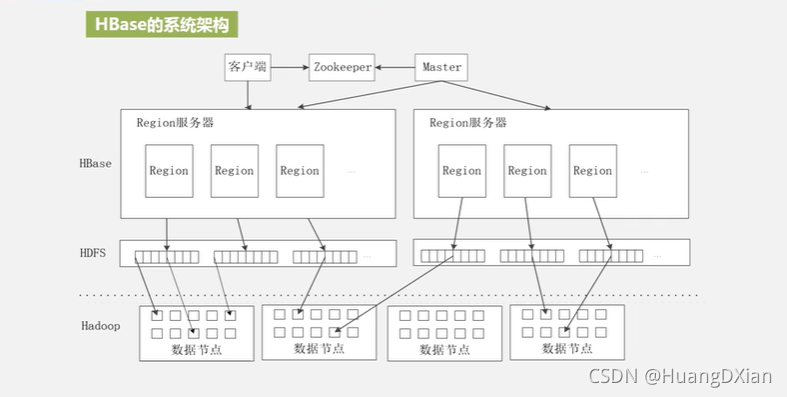

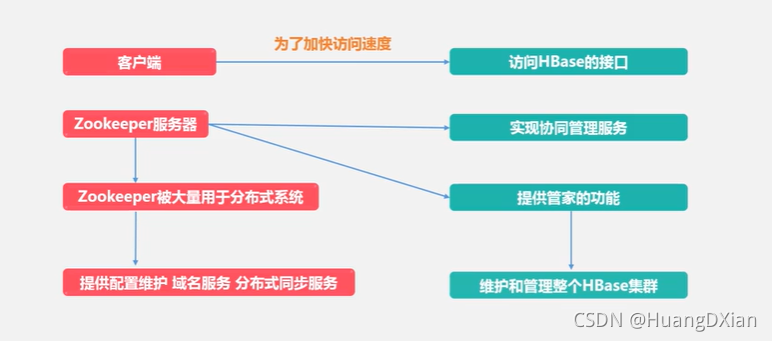
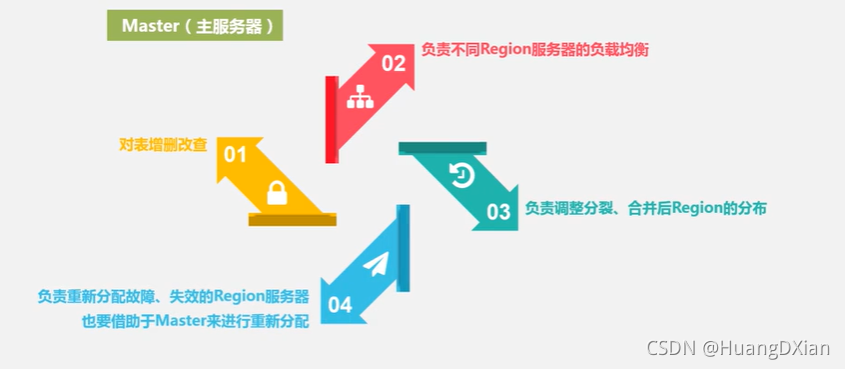

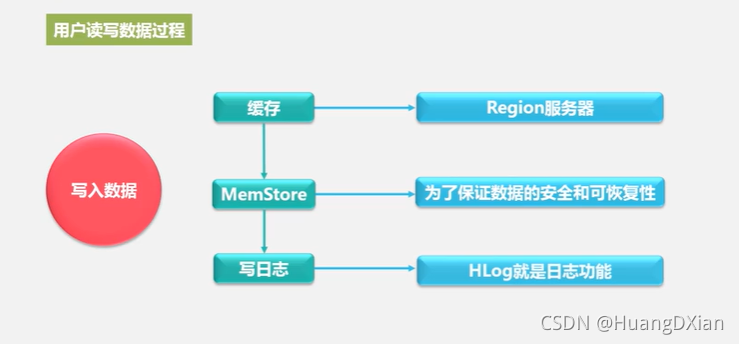

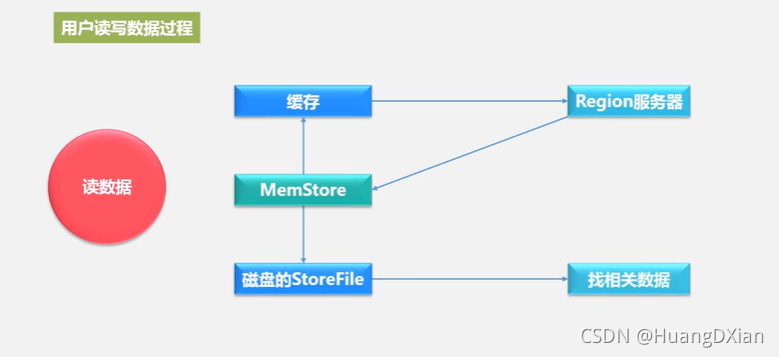
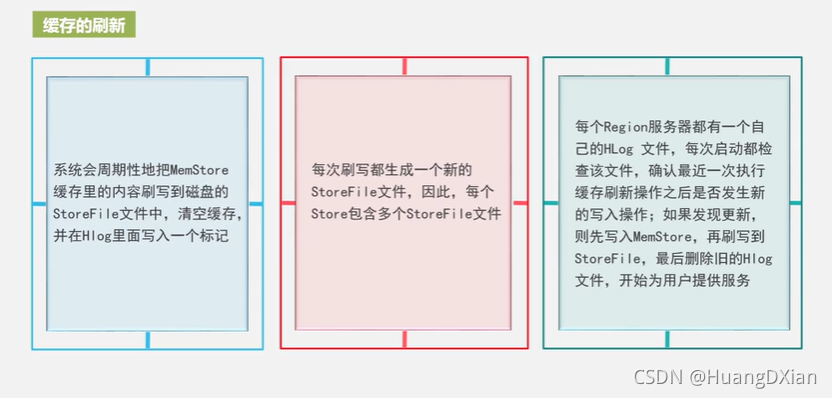
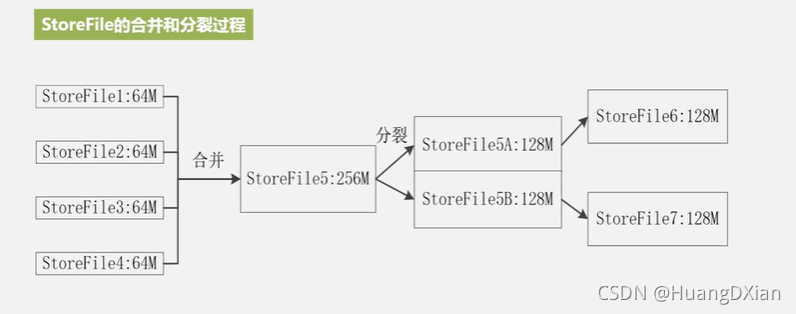
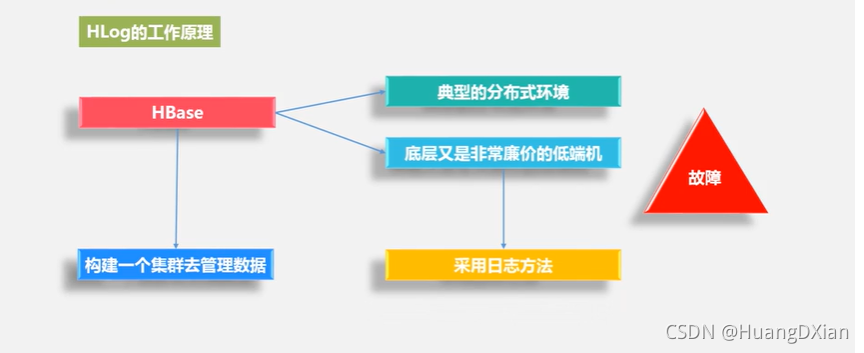

Hbase 应用方案
优化性能
- 从列族排列顺序
- 设置相关表于服务器缓存中
- 设置最大版本数 1-2-3版本
- 数据有效期 TimeToLive
如何检测性能
可视化工具 Master-status
Ganlia OpenTSDB Ambari
通过SQL查询Hbase
Hive 整理SQL接口
Phoenix
构建Hbase二级索引
原生Hbase不支持,只能行键索引
通过额为插件够用
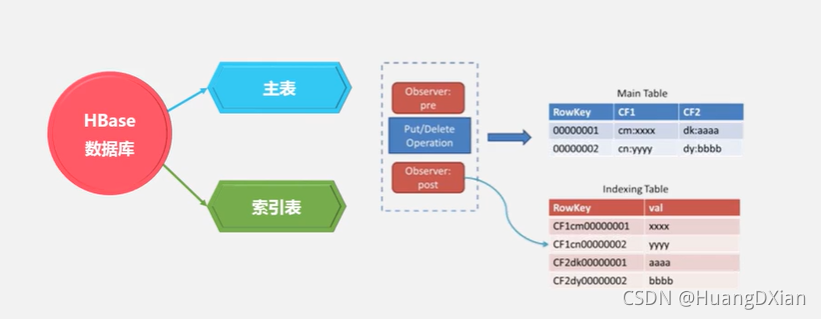
优点:不修改Hbase,构建其之上
缺点: 插数据插入索引表,对Hbase集训压力大
建立其他列与rowkey对应关系
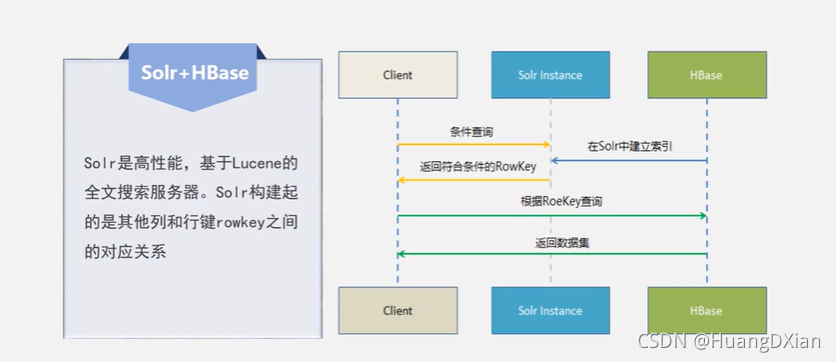
插入数据插入索引
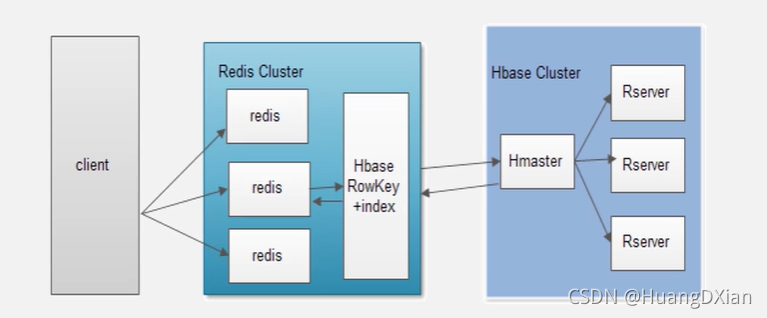
4.6Hbase的安装
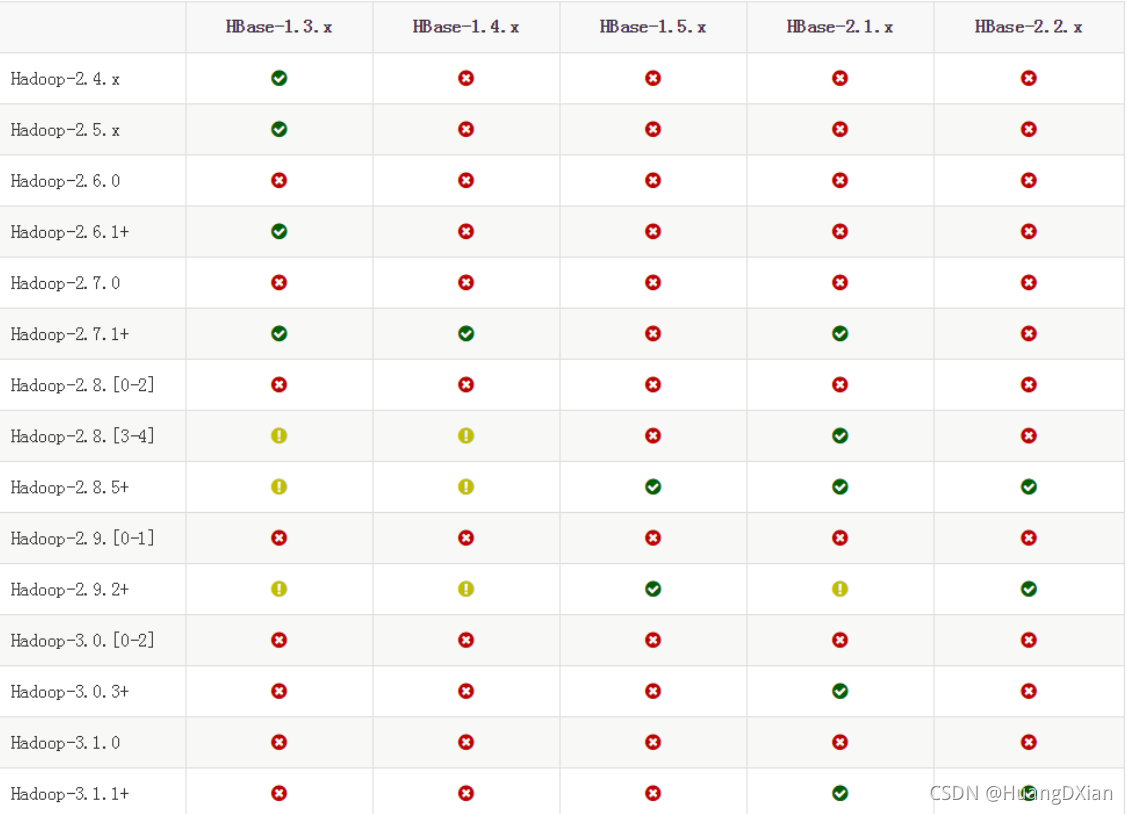
一、 注意安装Hadoop版本与Hbase版本的兼容性问题!!!
基于之前安装为(安装方法->)Hadoop3.1.3版本于此安装Hbase2.2.-x版本,下载2.2.2 bin.tar.gz版本即可
Hbase官方下载地址 传送门

兼容性下面表格截图来自官网
下载完成后将hbase压缩包导入Ubuntu系统中,解压安装包hbase-2.2.2-bin.tar.gz至路径 /usr/local,命令如下:
cd ~
sudo tar -zxf ~/下载/hbase-2.2.2-bin.tar.gz -C /usr/local
1.2 将解压的文件名hbase-2.2.2改为hbase,以方便使用,命令如下:
cd /usr/local
sudo mv ./hbase-2.2.2 ./hbase
Shell 命令,下面把hbase目录权限赋予给hadoop用户;
将hbase下的bin目录添加到path中,这样,启动hbase就无需到/usr/local/hbase目录下,大大的方便了hbase的使用。
编辑~/.bashrc文件
再执行source命令使上述配置在当前终端立即生效,命令如下:
cd /usr/local
sudo chown -R hadoop ./hbase
vim ~/.bashrc
export PATH=$PATH:/usr/local/hbase/bin
source ~/.bashrc
二、2. HBase配置
HBase有三种运行模式,单机模式、伪分布式模式、分布式模式。作为学习,以下先决条件很重要,比如没有配置JAVA_HOME环境变量,就会报错。
– jdk
– Hadoop( 单机模式不需要,伪分布式模式和分布式模式需要)
– SSH
以上三者如果没有安装,请回到Hadoop3.1.3的安装参考如何安装。
配置JAVA环境变量。如果你之前已经按照本网站Hadoop安装教程安装Hadoop3.1.3,则已经安装了JDK1.8。JDK的安装目录是/usr/lib/jvm/jdk1.8.0_162, 则JAVA _HOME =/usr/lib/jvm/jdk1.8.0_162;配置HBASE_MANAGES_ZK为true,表示由hbase自己管理zookeeper,不需要单独的zookeeper。hbase-env.sh中本来就存在这些变量的配置,大家只需要删除前面的#并修改配置内容即可,添加完成后保存退出即可。
vim /usr/local/hbase/conf/hbase-env.sh
****
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export HBASE_MANAGES_ZK=true
*****
在启动HBase前需要设置属性hbase.rootdir,用于指定HBase数据的存储位置,因为如果不设置的话,**hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。**此处设置为HBase安装目录下的hbase-tmp文件夹即(/usr/local/hbase/hbase-tmp),添加配置。
不同的模式主要区别在于配置文件的设置
vim /usr/local/hbase/conf/hbase-site.xml
****
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase/hbase-tmp</value>
</property>
</configuration>
***
接下来测试运行,启动HBase。如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。start-hbase.sh用于启动HBase,bin/hbase shell用于打开shell命令行模式,用户可以通过输入shell命令操作HBase数据库,stop-hbase.sh用于关闭hbase。
start-hbase.sh
bin/hbase shell
stop-hbase.sh
](https://img-blog.csdnimg.cn/4d8ab89ea5404fd59ec43eaa87b83c45.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBASHVhbmdEWGlhbg==,size_20,color_FFFFFF,t_70,g_se,x_16)
关闭单机版HBASE
2.2 伪分布式模式配置
1.配置/usr/local/hbase/conf/hbase-env.sh。配置JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK.
HBASE_CLASSPATH设置为本机HBase安装目录下的conf目录(即/usr/local/hbase/conf)
vim /usr/local/hbase/conf/hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export HBASE_CLASSPATH=/usr/local/hbase/conf
export HBASE_MANAGES_ZK=true
2.配置/usr/local/hbase/conf/hbase-site.xml用命令vi打开并编辑hbase-site.xml,修改hbase.rootdir,指定HBase数据在HDFS上的存储路径;将属性hbase.cluter.distributed设置为true。假设当前Hadoop集群运行在伪分布式模式下,在本机上运行,且NameNode运行在9000端口。
vim /usr/local/hbase/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
hbase.rootdir指定HBase的存储目录;hbase.cluster.distributed设置集群处于
分布式模式.另外,上面配置文件中,hbase.unsafe.stream.capability.enforce
这个属性的设置,是为了避免出现启动错误。也就是说,如果没有设置
hbase.unsafe.stream.capability.enforce为false,那么,在启动HBase以后,会
出现无法找到HMaster进程的错误,启动后查看系统启动日志
(/usr/local/hbase/logs/hbase-hadoop-master-ubuntu.log),会发现错误。
如果在操作HBase的过程中发生错误,可以通过{HBASE_HOME}目录(/usr/local/hbase)下的logs子目录中的日志文件查看错误原因。
这里启动关闭Hadoop和HBase的顺序一定是:
启动Hadoop—>启动HBase—>关闭HBase—>关闭Hadoop
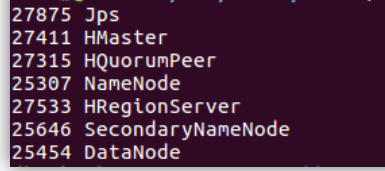
启动Hadoop和和hbase后 查看进程:
三、编程使用Hbse
shell命令
- 创建 create
因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建。
create 'student','Sname','Ssex','Sage','Sdept','course'
查看 表 describe
2.新增 put
一次只能为一个表的一行数据的一个列,也就是一个单元格添加一个数据,所以直接用shell命令插入数据效率很低,在实际应用中,一般都是利用编程操作数据。
当运行命令:
put ‘student’,’95001’,’Sname’,’LiYing’时,
即为student表添加了学号为95001,名字为LiYing的一行数据,其行键为95001。
为95001行下的course列族的math列添加了一个数据
put 'student','95001','course:math','80'
-
删除命令 delete、 deleteall、drop
HBase中用delete以及deleteall命令进行删除数据操作,它们的区别是: 1. delete用于删除一个数据,是put的反向操作; 2. deleteall操作用于删除一行数据。 3. drop 删除表 (删除表有两步,第一步先让该表不可用,第二步删除表) disable 'student' drop 'student'
4. 查看行 get 查看表 scan
get 'student','95001'
#返回的是‘student’表‘95001’行的数据
scan 'student'
#返回的是‘student’表的全部数据。
exit 退出Hbase
stop-hbase.sh 关闭Hbase命令