各层数据可视化
对之前一节分类的图片进行可视化的,
caffe训练(8):用训练好的模型(caffemodel)来分类新的图片
caffe训练(10)自己训练的caffemodel批量预测新图片–无其他参数(如准确率等)
caffe训练(11)自己训练的caffemodel对图片进行批量预测(含准确率等)
分类
- 前面的部分基本是一样的,就是载入模块、路径、图片、向前分类,具体程序如下:
import caffe
import sys
import numpy as np
import time
import cv2
import os
import pickle
import matplotlib.pyplot as plt
caffe_root='D:/caffe-master/' #根目录
sys.path.insert(0,caffe_root+'python')
caffe.set_mode_gpu()
deploy=caffe_root+'zzfl/deploy.prototxt' #deploy文件
caffe_model=caffe_root+'zzfl/fenlei__iter_40000.caffemodel.h5' #训练好的 caffemodel
img=caffe_root+'zzfl/val/620474041777.jpg' #随机找的一张待测图片
labels_name=caffe_root+'zzfl/labels.txt' #类别名称文件,将数字标签转换回类别名称
mean_file=caffe_root+'zzfl/mean.npy' #由*_mean.binaryproto转换的均值文件
net=caffe.Net(deploy,caffe_model,caffe.TEST) #加载model和network,参数1 网络结构,参数2 model权值,参数3 测试阶段
#图片预处理设置
transformer=caffe.io.Transformer({'data':net.blobs['data'].data.shape}) #设定图片的shape格式
transformer.set_transpose('data',(2,0,1)) #改变维度的顺序,由原始图片H*W*K(0,1,2),但我们需要的是K*H*W(2,0,1)
transformer.set_mean('data',np.load(mean_file).mean(1).mean(1)) #计算均值,减去均值
transformer.set_raw_scale('data',255) #把0-1的数值缩放到【0,255】之间
transformer.set_channel_swap('data',(2,1,0)) #交换通道,将图片由RGB变为BGR
image=caffe.io.load_image(img) #加载图片
net.blobs['data'].data[...]=transformer.preprocess('data',image) #执行上面设置的图片预处理操作,并将图片载入到blob中
start =time.clock() #测试开始时间
out=net.forward() #执行测试
end=time.clock() #测试结束时间
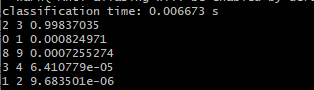
print('classification time: %f s' % (end - start)) #测试经历时间
labels=np.loadtxt(labels_name,str,delimiter='\t') #读取类别名称文件
prob=net.blobs['prob'].data[0].flatten() #取出最后一层(Softmax)属于某个类别的概率值,并打印
top_k=net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i],labels[top_k[i]],prob[top_k[i]]
'''
class_name=caffe_root+'example/myself/labels.txt'
category = net.blobs['prob'].data[0].argmax()
class_str = labels[int(category)].split(',')
class_str = labels[int(category)].split(',')
cv2.putText(img, class_name, (0, img.shape[0]), cv2.cv.CV_FONT_HERSHEY_SIMPLEX, 1, (55, 255, 155), 2)
'''
参数及形状
- 下面这部分是对各卷积层和参数一些变量的输出
print [(k, v.data.shape) for k, v in net.blobs.items()]
//网络的特征存储在net.blobs,首先是每层的特征和它们的形状。第一个是batch,第二个是feature map数目,第三和第四是每个神经元中的长和宽。
print [(k, v[0].data.shape) for k, v in net.params.items()]
//参数和bias存储在net.params,显示出各层的参数和形状,第一个是批次,第二个 feature map 数目,第三和第四是每个神经元中图片

-
输出的结果参数含义
blob:是网络特征,【名称,(batch(一次处理多少),feature map的个数,图片size=n*n)】
params:是各层参数和形状,【名称,(输出channel,输入channel,size=n*n)】
-
结果:

卷积层与池化层
- 下面是可视化的一个子函数,把filter放在一个正方形图片里面
//下面是定义了一个子函数,作用是把各层输出的feature map都放在一个正方形的图片里面,相当于写了一个存放的子函数,#输入为格式为数量,高,宽,(3维度),最终展示是在一个方形上
def vis_square(data, padsize=1, padval=0):
data -= data.min()
data /= data.max()
//将各个图片normalization
//n先开方再平方取到正方形的大小
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = ((0, n ** 2 - data.shape[0]), (0, padsize), (0, padsize)) + ((0, 0),) * (data.ndim - 3)
//pad的作用是把不足的框用0补上
data = np.pad(data, padding, mode='constant', constant_values=(padval, padval))
//将filters放进正方形里面
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
print data.shape
plt.imshow(data)
plt.show()
//显示,服务器上 plt.imshow显示不出来,要加上plt.show(),或者用opencv的这个显示,
cv2.imwrite("./out1.jpg",im) #前面是存放路径,后面是图片
- 然后进行可视化,卷积层和pooling层
//according to the net.params or net.blobs
//the parameters are a list of [weights, biases]
filters = net.['conv1'][0].data
vis_square(filters.transpose(0, 2, 3, 1))
//这里要转换是因为vis_square函数定义(output_mun,height,width,channels)
//输出的数量是filter的数量,输出96个filter
//params存储网络中间层的网络参数,conv1层的参数尺寸为(96, 3, 11, 11),params['conv1'][0].data为conv1的权重参数,filters转置后的尺寸为(96, 11, 11, 3),符合vis_square函数中data的定义(n, height, width, channels)。
//选择第四张图片(其实那一张都是一样的,因为50张图片是一样的),过滤后输出96张feature map
feat = net.blobs['conv1'].data[4, :96]
vis_square(feat, padval=1)
//输出第一张图片前36张feature map
feat = net.blobs['conv1'].data[0, :36]
vis_square(feat, padval=1)
//#第二个卷积层:有 128 个滤波器,每个尺寸为 5X5X48。我们只显示前面 48 个滤波器,每一个滤波器为一行。
filters = net.params['conv2'][0].data
vis_square(filters[:48].reshape(48**2, 5, 5))
//第二层输出 256 张 feature,这里显示 36 张。
feat = net.blobs['conv2'].data[4, :36]
vis_square(feat, padval=1)
//同上,只是换张图片
feat = net.blobs['conv2'].data[0, :36]
vis_square(feat, padval=1)
//第三个卷积层:全部 384 个 feature map
feat = net.blobs['conv3'].data[4]
vis_square(feat, padval=0.5)
//第四个卷积层:全部 384 个 feature map
feat = net.blobs['conv4'].data[4]
vis_square(feat, padval=0.5)
//第五个卷积层:全部 256 个 feature map
feat = net.blobs['conv5'].data[4]
vis_square(feat, padval=0.5)
//第五个 pooling 层:我们也可以观察 pooling 层
feat = net.blobs['pool5'].data[4]
vis_square(feat, padval=1)
- 结果的图片:
conv1-params

conv1-blobs

conv3-blobs

全连接层
最后是全连接层,先是全连接层4096个神经元的输出值,下面的图是对这些输出值的统计直方图,对于fc6大多数神经元响应值在40以下,比fc7要小。全连接层前后相连,越往后神经元值越不会均匀分布,通过神经元之间的竞争,最后一层全连接层prob产生的尖峰为优胜神经元,该优胜神经元决定了对象属于哪一类。
//第六层(第一个全连接层)输出后的直方分布:
feat = net.blobs['fc6'].data[4]
plt.subplot(2, 1, 1)
plt.plot(feat.flat)
plt.subplot(2, 1, 2)
_ = plt.hist(feat.flat[feat.flat > 0], bins=100)
plt.show()
//第七层(第二个全连接层)输出后的直方分布:可以看出值的分布没有这么平均了。
feat = net.blobs['fc7'].data[4]
plt.subplot(2, 1, 1)
plt.plot(feat.flat)
plt.subplot(2, 1, 2)
_ = plt.hist(feat.flat[feat.flat > 0], bins=100)
plt.show()
//输出优胜神经元
feat = net.blobs['prob'].data[0]
plt.plot(feat.flat)
plt.show()
- 在这里插入图片描述结果的图是这样的


总体流程
1.查看CNN各层的activations值的结构(即每一层的输出)
代码如下:
# 显示每一层
for layer_name, blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
- 第i次循环体内部
layer_name提取的是net的第i层的名称
blob提取的是net的第i层的输出数据(4d)
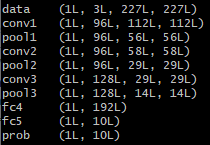
结果为:
data (50, 3, 227, 227) 网络的输入,batch_number = 50,图像为227*227*3的RGB图像
conv1 (50, 96, 55, 55) 第一个conv层的输出图像大小为55*55,feature maps个数为96
pool1 (50, 96, 27, 27) 第一个pool层的图像尺寸为27*27,feature map个数为96
norm1 (50, 96, 27, 27) 第一个norm层的图像尺寸为27*27,feature map个数为96
conv2 (50, 256, 27, 27) 第二个conv层的图像尺寸为27*27,feature map个数为256
pool2 (50, 256, 13, 13) 第二个pool层的图像尺寸为13*13,feature map个数为256
norm2 (50, 256, 13, 13) 第二个norm层的图像尺寸为13*13,feature map个数为256
conv3 (50, 384, 13, 13) 第三个conv层的图像尺寸为13*13,feature map个数为384
conv4 (50, 384, 13, 13) 第四个conv层的图像尺寸为13*13,feature map个数为384
conv5 (50, 256, 13, 13) 第五个conv层的图像尺寸为13*13,feature map个数为256
pool5 (50, 256, 6, 6) 第五个pool层的图像尺寸为13*13,feature map个数为256
fc6 (50, 4096)
第六个fc层的图像尺寸为4096
fc7 (50, 4096)
第七个fc层的图像尺寸为4096
fc8 (50, 1000)
第八个fc层的图像尺寸为1000
prob (50, 1000)
probablies层的尺寸为1000
下面画出该数据,从图中观察更为形象
2.查看每一层的参数结构
代码如下:
for layer_name, param in net.params.iteritems():
print layer_name + '\t' + str(param[0].data.shape), str(param[1].data.shape)
- 第i次循环体内部
layer_name提取的是net的第i层的名称
param提取的是net的第i层的参数
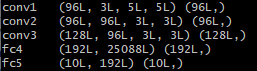
结果如下:
conv1 (96, 3, 11, 11) (96,) 第一个conv层的filters的尺寸,这里的3是因为输入层的data为rgb,可以看做三个feature maps
conv2 (256, 48, 5, 5) (256,) 第二个conv层的filters尺寸
conv3 (384, 256, 3, 3) (384,)第三个conv层的filters尺寸
conv4 (384, 192, 3, 3) (384,)第四个conv层的filters尺寸
conv5 (256, 192, 3, 3) (256,)第五个conv层的filters尺寸
fc6 (4096, 9216) (4096,)第一个fc层的权值尺寸
fc7 (4096, 4096) (4096,)第二个fc层的权值尺寸
fc8 (1000, 4096) (1000,)第三个fc层的权值尺寸
应该注意到,由于pool层和norm层并没有需要优化的参数,所以参数中并没有关于pool层和norm层的信息
下面给出filters如何对输入数据进行filter的一幅形象化的图
3.可视化4D数据的函数
def vis_square(data):
# 输入的数据为一个ndarray,尺寸可以为(n, height, width)或者是 (n, height, width, 3)
# 前者即为n个灰度图像的数据,后者为n个rgb图像的数据
# 在一个sqrt(n) by sqrt(n)的格子中,显示每一幅图像
# 对输入的图像进行normlization
data = (data - data.min()) / (data.max() - data.min())
# 强制性地使输入的图像个数为平方数,不足平方数时,手动添加几幅
n = int(np.ceil(np.sqrt(data.shape[0])))
# 每幅小图像之间加入小空隙
padding = (((0, n ** 2 - data.shape[0]),
(0, 1), (0, 1)) # add some space between filters
+ ((0, 0),) * (data.ndim - 3)) # don't pad the last dimension (if there is one)
data = np.pad(data, padding, mode='constant', constant_values=1) # pad with ones (white)
# 将所有输入的data图像平复在一个ndarray-data中(tile the filters into an image)
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
# data的一个小例子,e.g., (3,120,120)
# 即,这里的data是一个2d 或者 3d 的ndarray
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
# 显示data所对应的图像
plt.imshow(data); plt.axis('off')
4.查看第一个convolution layers的filters的图像
- 代码如下:
# the parameters are a list of [weights, biases]
filters = net.params['conv1'][0].data
vis_square(filters.transpose(0, 2, 3, 1))
- filters存储的是第一个conv层的filters的数据
例子:形状为:(96, 3, 11, 11)
结果如下:共96幅图像(96个filters,每个filters为11113)
5.查看第一个convolution layers的输出(activations)的图像
- 代码如下:
feat = net.blobs['conv1'].data[0, :36]
vis_square(feat)
- feat存储的是第一个卷基层的后36幅图像
feat的尺寸为(36, 55, 55)
结果如下:
6. 查看pool5的输出图像
- 代码如下:
feat = net.blobs['pool5'].data[0]
vis_square(feat)
- feat存储的是pool5的输出图像
feat的尺寸为(256, 6, 6)
7. 第一个全连接层的输出
- 代码如下:
feat = net.blobs['fc6'].data[0]
plt.subplot(2, 1, 1)
plt.plot(feat.flat)
plt.subplot(2, 1, 2)
_ = plt.hist(feat.flat[feat.flat > 0], bins=100)
8. probability层的输出
代码如下:
feat = net.blobs['prob'].data[0]
plt.figure(figsize=(15, 3))
plt.plot(feat.flat)
