这篇文章是基于《Effective Python——编写高质量Python代码的59个有效方法》[美] 布雷特·斯拉特金 著 爱飞翔 译 这本书中的内容,写写自己在某方面的感悟,并摘录一些作为读书笔记供今后鞭策。侵删。
第 1 条:确认自己所用的Python版本
-
如果你现在想入手Python学习,那么就选择python3。
$ python --version Python 2.7.8 -
流行的Python运行环境:CPython、Jython、IronPython、PyPy。
memo
-
选择什么版本Python下载?
- 按照我的经验来看,最好不要选择最新版本的型号,因为会有一些包并没有匹配最新版本的,可以试试3.5/3.6。
-
解释器的问题
我们在编写python代码时,会得到一个以.py结尾的文件,而我们需要使用解释器去执行我们的.py文件。-
CPython解释器:这是Python自带的一种解释器,通过 cmd(command line,命令行)便可以打开,在cmd下,输入"python",或是直接在“运行”(win+R打开)中输入python均可以进入交互式命令行界面(解释器),如下图所示:
方法一:


方法二:


python还自带了一种可以直接打开的CPython解释器——IDLE ( 集成开发环境),当安装好python后,便可以发现如下图所示的应用程序,打开即可,如果找不到的话,可以在电脑中搜索idle.exe。

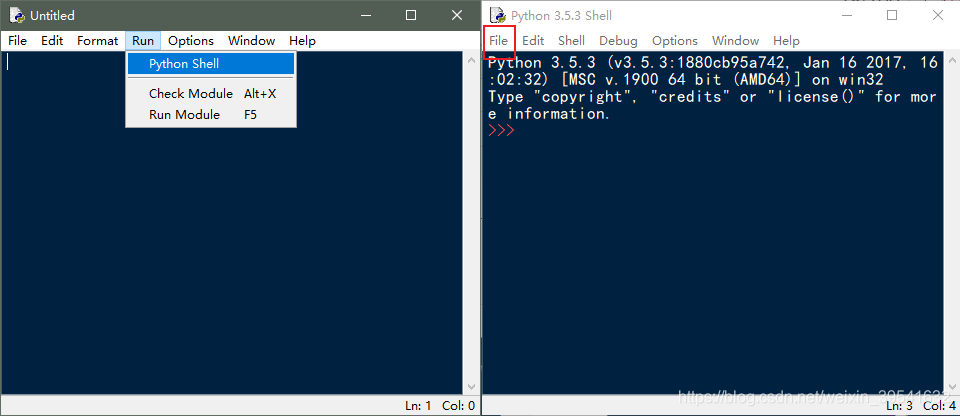
打开后便可以看到如下的界面中的一个:图中的Python Shell可以打开右侧的界面,点击File->New Files可以新建出左侧的界面。我们可以在右侧进行交互式编程,可以用它来当作计算器使用,在左侧界面中可以编写脚本或者小程序。
-
IPyhton解释器:一种交互方式更友好的python解释器。功能和CPython并没有区别,如下图所示:

-
Pypy解释器:能够提高Python代码的执行速度,会对代码进行编译,而非传统的解释执行,如果你对C语言是如何运行的有所了解的话,可能你能够理解。
-
Jython解释器:运行在Java平台的解释器。
-
IronPython解释器:运行在Microsoft.NET平台上的解释器。
-
第 2 条:遵循PEP 8 风格指南
空白
- 使用space来表示缩进,不要使用tab。
- 每行字符数不应该超过79。
- 对于占据多行的长表达式来说,除了首行之外的其余各行都应该在通常的缩进级别上再加4个空格。
- 在同一个类中,各方法之间应该用一个空行隔开。
- 文件中的函数与类之间应该用两个空行隔开。
- 为变量赋值的时候,在等号两边添加一个空格,其余条件下等号两边能不加空格就不要加。
memo
-
python中的空格和tab键不能混用
否则的话则会报类似如下的错误:IndentationError: unindent does not match any outer indentation level -
Pycharm中如何设置每行字符个数?
File→Settings→Code Style→ columns

可以看到右侧显示了一条竖线来表示字符范围。

-
如何在pycharm设置pep8外部工具,实现代码的自动排版?
-
安装autopep8
pip install autopep8 -
本文使用的Pycharm版本如下
PyCharm 2019.3.1 (Community Edition) Build #PC-193.5662.61, built on December 19, 2019 Runtime version: 11.0.5+10-b520.17 amd64 VM: OpenJDK 64-Bit Server VM by JetBrains s.r.o Windows 10 10.0 GC: ParNew, ConcurrentMarkSweep Memory: 974M Cores: 4 Registry: Non-Bundled Plugins: izhangzhihao.rainbow.brackets -
File - Settings - Tools - External Tools
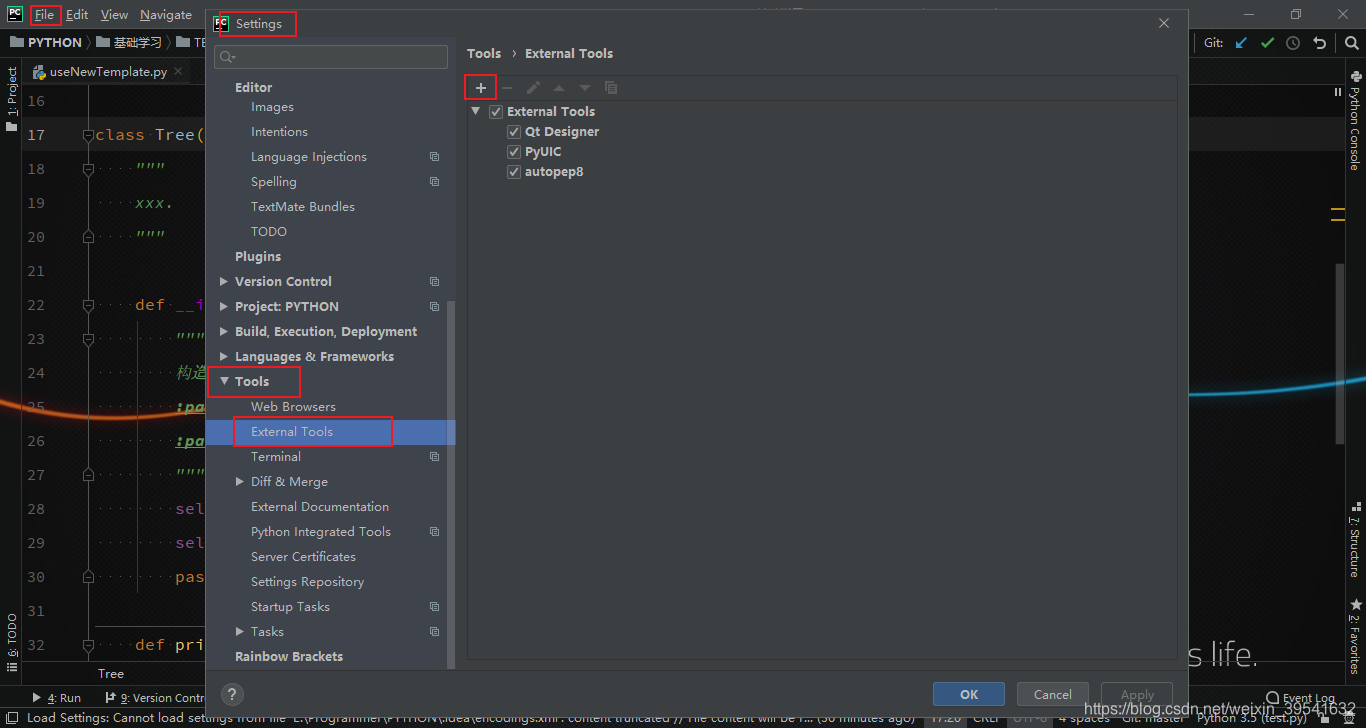

上图的内容如下:Name:autoPep8 Program:autopep8 Arguments: --in-place --aggressive --aggressive $FilePath$ Working directory: $ProjectFileDir$ Output filters: $FILE_PATH$\:$LINE$\:$COLUMN$\:.*点击OK即可配置成功。
这是未经规范化的代码:
# coding: utf-8 # !/usr/bin/python """ @File : useNewTemplate.py @Author : jiaming @Modify Time: 2019/11/29 21:30 @Contact : https://blog.csdn.net/weixin_39541632 @Version : 1.0 @Desciption : None """ import os import random import pysnooper class Tree(object): """ xxx. """ def __init__(self, left,right): """ 构造函数 :param left: 左节点 :param right: 右节点 """ self.left = left self.right=right pass def print_array(self): pass @pysnooper.snoop() def main(): """ 主函数 :return: """ pass if __name__ == "__main__": main()
点击完毕autopep8后,我们可以看到如下的效果。# coding: utf-8 # !/usr/bin/python """ @File : useNewTemplate.py @Author : jiaming @Modify Time: 2019/11/29 21:30 @Contact : https://blog.csdn.net/weixin_39541632 @Version : 1.0 @Desciption : None """ import os import random import pysnooper class Tree(object): """ xxx. """ def __init__(self, left, right): """ 构造函数 :param left: 左节点 :param right: 右节点 """ self.left = left self.right = right pass def print_array(self): pass @pysnooper.snoop() def main(): """ 主函数 :return: """ pass if __name__ == "__main__": main()
-
命名
- 函数、类属性、变量:小写字母+下划线 (lowercase_underscore)
- 受保护的类属性:以单个下划线开头 (_leading_underscore)
- 私有的类属性:应该以两个下划线开头 (__double_leading_underscore)
- 类与异常:采用驼峰命名法。百度百科:驼峰命名法
- 模块级常量:大写+下划线分隔
- 类中实例方法首个参数:默认为self就好
- 类中的类方法的首个参数:默认为cls就好
表达式语句
-
判断是否为空值或是非空值,不应该采用长度判断法,应该使用条件判断,比如:
>>> l = [] >>> l is None False >>> len(l) == 0 True >>> l.append(1) >>> l is None False可以参考我的这篇博文,探究None和False的区别None和False
-
将单行的if、while、for、except的复合语句拆分成多行完成。
-
import语句总是应该在文件开头
-
引入模块时采用 from…import…as…格式
-
将引入模块按照顺序引入:标准库模块,第三方模块,自用模块。每一部分的模块均按照字母顺序排列。
第 3 条:了解bytes、str与unicode的区别
Python 3有两种表示字符序列的类型:bytes和str。前者的实例包含原始的8位值,后者的实例包含Unicode字符。把Unicode字符表示为二进制数据有许多种方法,最常见的编码方式是UTF-8。
要想把Unicode字符转化成为二进制数据,就必须使用encode方法,要想把二进制数据转换成为Unicode字符,则必须使用decode方法。来看下面这个样例:
>>> s = 'a'.encode()
>>> s
b'a'
>>> type(s)
<class 'bytes'>
>>> s = '123'.encode()
>>> s
b'123'
>>> s = '我喜欢Python'.encode()
>>> s
b'\xe6\x88\x91\xe5\x96\x9c\xe6\xac\xa2Python'
>>> s.decode('UTF-8')
'我喜欢Python'
在Python 3中编写接受str或bytes,并返回str的方法:
以下是在交互式命令行中运行的结果。
>>> def to_str(bytes_or_str):
... if isinstance(bytes_or_str, bytes):
... value = bytes_or_str.decode('utf-8')
... else:
... value = bytes_or_str
... return value
...
在Python 3中编写接受str或bytes,并返回bytes的方法:
以下是在交互式命令行中运行的结果。
>>> def to_bytes(bytes_or_str):
... if isinstance(bytes_or_str, str):
... value = bytes_or_str.encode('utf-8')
... else:
... value = bytes_or_str
... return value
...
memo
- 对于操作二进制文件可能出现的问题
在python 3中,如果内置的open函数获取了文件的句柄,那么请注意,该句柄1会采用UTF-8编码格式来操作文件。
向文件中写入二进制数据:使用的方式为(‘wb’)而不是(‘w’)。读取数据时采用(‘rb’)而不是(‘r’)
第 4 条:使用辅助函数来代替复杂表达式
一行代码可以有多复杂?
print('\n'.join([''.join([('Love'[(x-y) % len('Love')] if ((x*0.05)**2+(y*0.1)**2-1)**3-(x*0.05)**2*(y*0.1)**3 <= 0 else ' ') for x in range(-30, 30)]) for y in range(30, -30, -1)]))
下图展现了它的结果。代码解释请参考我的这篇博客:心形

针对上述极为复杂的代码我们应该采取使用函数的方式来简化。我们只需要将上面代码中的各个语句拆分出来即可。这会让代码变得更加易读,比原来密集的写法更好。
由于Python短小精悍,功能强大,所以很容易就能够写出非常复杂的表达式,我们要避免这种写法。
是一种标识符或者指针,可以理解为文件的描述符,用来指代开发者将要操作的文件。
 ↩︎
↩︎
