11月19日晚,韩国棋院宣布80后的一代传奇围棋手李世石,正式退役退出,而李世石唯一一位在与AlphaGo的大战中,能够获得一局胜利的棋手。李世石从1995年7月开始职业围棋生涯,2003年刚满20岁的李世石就获得LG杯冠军。李世石属于典型的力战型棋风,善于敏锐地抓住对手的弱处主动出击,以强大的力量击垮对手,他的攻击可以用"稳,准,狠"来形容,经常能在劣势下完成逆转。

中国棋手古力与李世石被外界称为“一生之敌”,在2013年两人进行了一场“梦百合”世纪之战,最终李世石以6比2战胜古力。在得知李世石宣布退役之后,古力也在其微博上发声:“希望今后你能活成更加独一无二的李世石”。

在李世石24年的围棋生涯中,一共赢得了50座冠军奖杯,包括18次世界冠军和32次全国冠军,累积获得总奖金接近98亿韩元。
终局之战
大概是因为中信集团的董事长常振明七段是一位围棋高手,曾经做过聂卫平的队友,所以中信旗下企业经常赞助一些围棋比赛,比如李世石退役战中登场的AI选手“韩豆(HANDOL)”就是今年“中信建投证券杯”世界智能围棋公开赛的季军得主,顺道提一句19年智能围棋赛的冠军是来自腾讯AI LAB的“绝艺”,可见国内对局类AI的发展态势也很强劲。
由于公认AI棋手在与人类顶尖棋手的水平差距在两子左右,因此在在本轮对局的第一局比赛中李世石受让两子,并贴七目半的方式展开。局中李世石一直保持优势,在回顾了本局棋谱之后,笔者认为本局李世石在第80手的这一“飞”,绝对堪称这位天才棋手凭生精力之所聚,是断绝白棋所有希望的杀招。不过本文并不是一个有关围棋的文章,所以具体对局分析这里也就不加赘述了。

在第二局中双方回归互不相让的公平对局模式,结果AI韩豆轻松获胜,第三局李世石再次受两子,贴七目半,结果还是落败,最终以1-2不敌AI。
我们知道让两子,这几乎已经是相差两个段位棋手之间的教学赛了,而且赛后的评论中也指出韩豆之所以会在第一局中落败关键还是对于让子的对局训练量不足,如果进行专门训练AI也不一定会落败。由此可见AI与人类棋手的差距之大,也不难理解李世石做为一位80后正值职业生崖黄金时期也会选择退设的道理了。
神之一手
可能也有不少读者和笔者一样也是通过《棋魂》这部动画片,开始了解围棋的。而三年前李世石与AlphaGo的第四局对弈中的第78手这一挖,则堪称是神之一手最佳代言了,甚至被围棋界认为是“捍卫了人类智慧文明的瑰宝”。

随后AlphaGo被李世石的“神之一手”下得陷入混乱,走出了黑93一步常理上的废棋,导致棋盘右侧一大片黑子“全死”。 此后,“阿尔法围棋”判断局面对自己不利,每步耗时明显增长,更首次被李世石拖入读秒。最终,李世石冷静收官锁定胜局。不过后来通过仔细复盘人们发现这78手并非完全无解,只是骗到了当时的AlphaGo引发了AI的Bug才使人类能够赢下一盘。
大魔王AlphaZero
虽然没有公开算法模型没有公开,但是目前世界上棋力最强的几个AI棋手应该都是基于AlphaZero的。我们知道之前初代Alpha是基于人类对局棋谱进行训练的,AlphaGo Zero则是抛弃人类棋谱,完全是通过自我对局来完成训练。主要分为两个部分,一是神经网络,二蒙特卡洛树搜索。
首先生成自对局的棋谱,然后将棋谱作为输入训练神经网络,训练好的神经网络用来预测落子和胜率。这是一个典型的神经网络具体如下图:
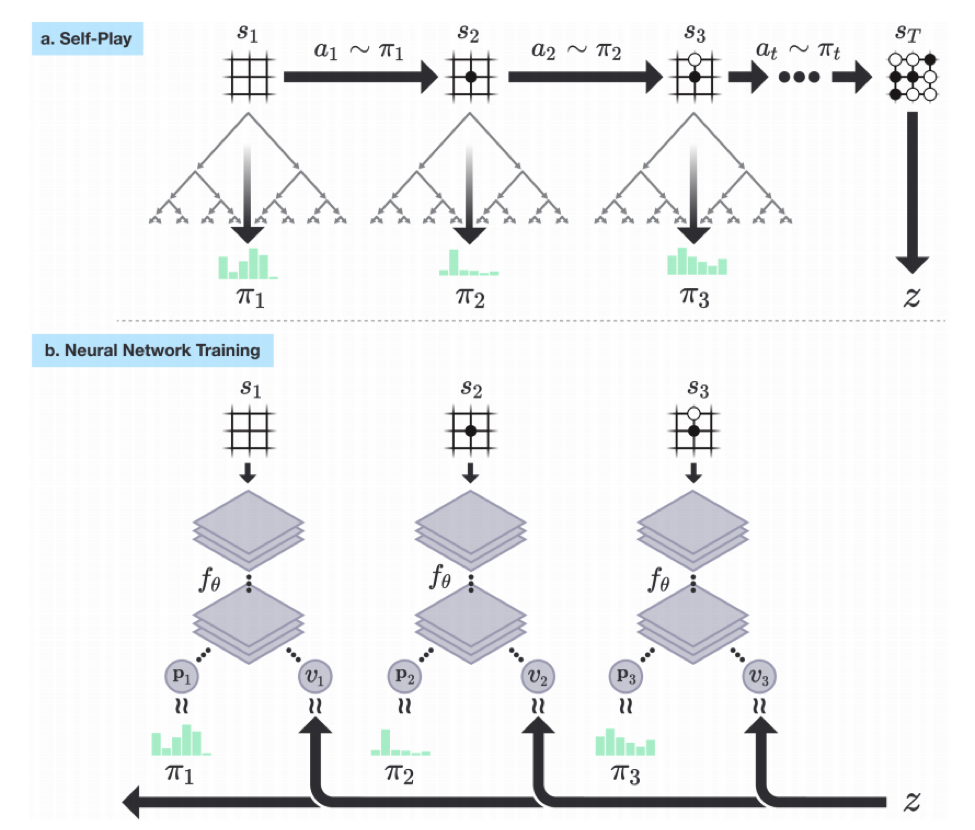
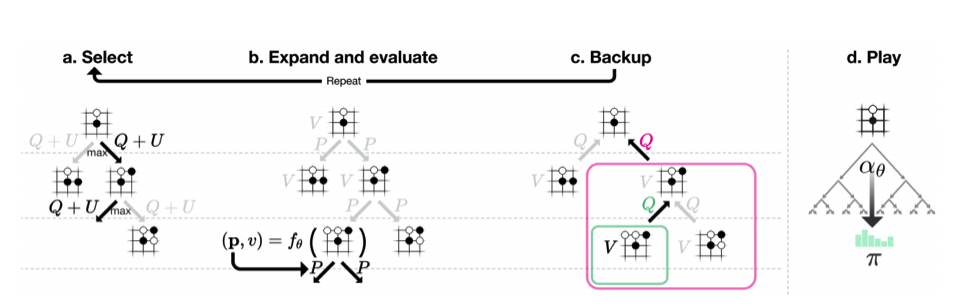
蒙特卡洛树搜索主要用于生成自对局的棋谱,他将博弈分为select、Expand and Evaluatet以及Backup几个阶段,而每次模拟的过程都是递归的,从父节点的局面开始,选择一个走子。比如开局的时候,所有合法的走子都是可能的选择,那么我该走哪个子就是select,基于每个可能的select进行再展开和递归搜索就是Expand,而Backup则是通过神经网络得到每个动作的概率和胜率,把这些动作添加到树上,最后把胜率传回,再做Evaluatet,如此递归完成整个树的搜索。具体如下:
零距离感受AlphaZero
由于围棋的门槛比较高因此受众不多,不过AlphaZero的应用并不限于围棋,据笔者观察在Github上已经有不少基于AlphaZero模型的中国象棋开源项目了,比如https://github.com/NeymarL/ChineseChess-AlphaZero。
只要安装了Tensorflow(GPU版)就能直接通过命令git clone https://github.com/NeymarL/ChineseChess-AlphaZero,将该项目下载下来,然后使用pip install -r requirements.txt来安装就可以了。如果没有显卡的,将requirements.txt中的tensorflow-gpu改为tensorflow也可以安装。
完成安装后输入python cchess_alphazero/run.py play命令,就可以直接与AlphaZero进行中国象棋的对局了。

未来展望,Open AI提出通用对局AI模型-MuZero
就在几周以前,那个在DOTA2的比赛中占胜人类顶尖选择的Open AI再发神作《Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model》(论文地址:https://arxiv.org/pdf/1911.08265.pdf)。我们知道之前的AlphaZero虽强,但是还需要提前了解规则,比如我们刚刚举的例子当中,就需要提前定义胜负条件及规则,源码详见这个文件:https://github.com/NeymarL/ChineseChess-AlphaZero/blob/distributed/cchess_alphazero/environment/chessboard.py
而MuZero则是 AlphaZero的强化版,他甚至不需要提前知道规则,他只需要知道对局的结果就可以了。读者可以简单的理解为MuZero将之前蒙特卡洛搜索的算法推广到一个基于强化学习的版本上,具体如下:

从论文提到的情况上看,MuZero的成绩不俗。

上图中纵坐标为Elo评分,横坐标为训练步数,黄色曲线代表AlphaZero的分数,而蓝色曲线代表MuZero的分数,我们看到在国际象棋、将棋、围棋和阿达利游戏中MuZero最终表现均不低于AlphaZero。
我们知道现实生活中的许多真实的问题(如股票,军事行动)都没有明确的规则,或者规则会变动,需要具体决策需要AI自行摸索,而这也是强化学习的优势所在。未来强人工智能是否能够出现让我们拭目以待。
