1、读取txt文件并返回字典
文件内容如下:

代码如下:
#!/usr/bin/env python
# coding=utf-8
import codecs
def read_txt(path):
txt_dict = {}
with codecs.open(path, 'r', 'utf-8') as config:
for line in config.readlines():
# 遍历文件中每一行并以“=”分隔,再做列表解析,使用for循环去掉换行符,并以列表形式返回
result = [ele.strip() for ele in line.split('=', 1)]
# 先使用dict()将嵌套列表'[result]'转换成字典,再使用update更新字典
txt_dict.update(dict([result]))
return txt_dict
运行结果如下:

2、读取csv文件
import csv
#打开文件,用with打开可以不用去特意关闭file了,python3不支持file()打开文件,只能用open()
with open("XXX.csv","r",encoding="utf-8") as csvfile:
#读取csv文件,返回的是迭代类型
read = csv.reader(csvfile)
for i in read:
print(i)3、读取csv文件并返回字典:
文件如下:
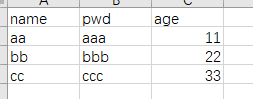
代码如下:
#!/usr/bin/env python
# coding=utf-8
import codecs
import csv
with codecs.open('D:/userinfo.csv', 'r', encoding='utf-8') as fp:
fp_key = csv.reader(fp)
for csv_key in fp_key:
print('字典的key值:%s' % csv_key)
csv_reader = csv.DictReader(fp, fieldnames=csv_key)
print('DictReader()方法返回值:%s' % csv_reader)
for row in csv_reader:
print('--------->>')
csv_dict = dict(row)
print(csv_dict)
运行结果如下:
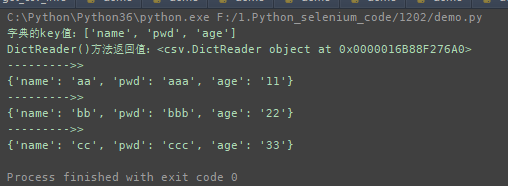
注意:读取csv文件的两个方法reader()和DictReader():
import csv
#csv文件,是一种常用的文本格式,用以存储表格数据,很多程序在处理数据时会遇到csv格式文件
files=open('test.csv','rb')
#方法一:按行读取,返回的是一个迭代对象
'''
reader=csv.reader(files)
for line in reader:
print(line)
'''
print '***'*10
#方法二:读取结果生成一个dict
Reader=csv.DictReader(files)
for row in Reader:
#print(row)
#上一句输出结果:
#{'url': 'baidu.com', 'xuhao': '1', 'key': '\xe7\x99\xbe\xe5\xba\xa6'}
#简单的数据处理
print(row['xuhao'],row['url'])
files.close()