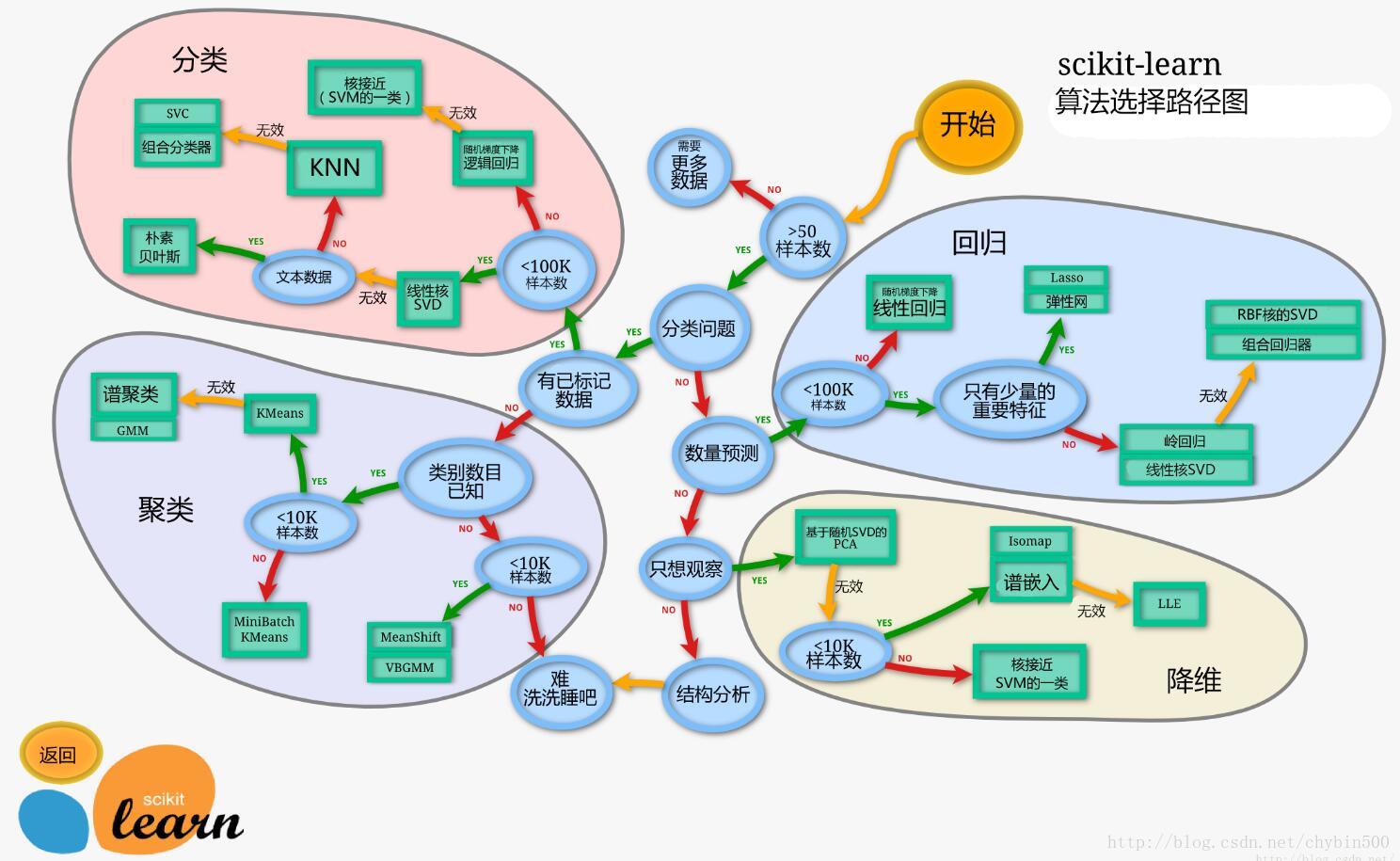
一、机器学习开发流程
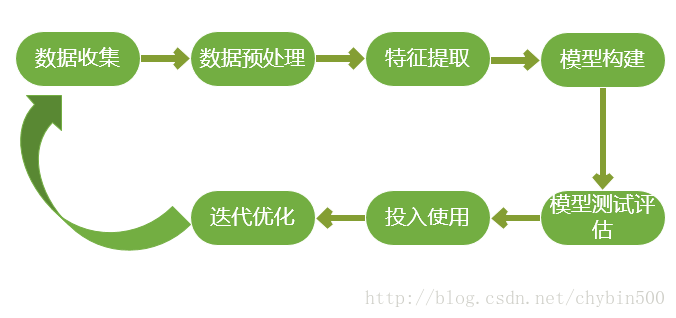
1、数据收集
数据来源一般有三类:
(1) 业务数据
(2) 日志数据
(3) 外部数据
2、数据预处理
大部分情况下,收集到的数据需要经过处理才能够为算法所用,预处理的主要有以下几个部分:
(1) 数据过滤
(2) 缺失值处理
(3) 处理可能的异常、错误、或者异常值
(4) 合并多个数据源来的数据
(5) 数据汇总
数据清洗与转换
对于数据进行初步的预处理,需要将其转换为一种适合机器学习模型的表示形式,对于很多模型来说,这个形式就是向量或者矩阵。
(1) 类别数据:将类别数据编码为对应的数值表示,一般使用1-of-k方法
(2) 文本数据:从文本中提取有用的数据,一般使用词袋法或者TF-IDF
(3) 图像或者音频:对像素、声波、音频、振幅等进行傅里叶变换
(4) 数值数据转为类别数据以减少变量的值。比如年龄分段。
(5) 对数值数据进行转换,比如对数转换
(6) 对特征进行正则,标准化,以保证同一模型的不同输入变量的值域相同。
(7) 对现有变量进行组合或转换以生成新特征。
1-of-k 编码方法
- 功能
- 将非数值型的特征值转换为数值型的数据
- 描述
- 假设变量的取值有k个,如果对这些值用1到k编序,则可以用维度为k的向量来表示一个变量的值,这样的向量里,该取值所对应的序号所在的元素为1,其他元素为0。
- 举例
-
比如一个特征T1的取值有三个:A、B、C,那么对这些值编码可以为(1,0,0)、(0,1,0)、(0,0,1)。那么有几个样本为 :
那么可以编码为:
词袋法
文本数据抽取可以使用词袋法,词袋法是将文本当做一个无序的数据集合,文本特征可以采用文本中的词条T进行体现,那么当文本中出现的所有词条及其出现的次数就可以体现文档的特征。
- 举例
-
有两个文档:文档1和文档2,他们里面一共有A、B、C、D、E五个词,他们在文件中各自一共出现的次数如下所示:
文档1:A(2次)、B(1次)、C(3次)、D(9次)、E(1次)
文档2:A(1次)、B(5次)、C(2次)、D(10次)
那么:
词频TF(A|文档1)=2/16、TF(B|文档1)=2/16、……
词频TF(A|文档2)=1/18、TF(B|文档2)=5/18、…..
然后就能得到一个矩阵:
3、特征提取
4、模型构建
5、模型测试评估
交叉验证
将数据分为训练集和测试集,在训练集上构建模型,然后在测试集上测试效果,迭代进行数据模型的修改,这种方式被称为交叉验证。
模型评估的几个指标
- 准确率:预测正确的样本/总样本数
- 召回率(覆盖率):正确的正例样本数/样本中的正例样本数
- 精准率:正确的正例样本数/预测为正例的样本数
- F值:精确率和召回率的调和平均值
6、投入使用、模型部署与整合
7、迭代优化
二、机器学习的分类
1、按照是否有样本分
(1) 监督学习
通过已经标注的样本来建立模型,这样的学习是监督学习。监督学习有两类模型:
- 判别式模型(Discriminative Model)
- 直接对条件概率进行建模,常见的判别式模型有:线性回归、决策树、支持向量机SVM、k近邻、神经网络等。
- 生成式模型(Generative Model)
- 对联合分布概率进行建模,常见的生成式模型有:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA等
- 判别式模型和生成式模型的区别:
-
● 生成式模型关注的是数据是如何产生的,寻找的是数据的分布模型;判别式模型关注的是数据的差异性,寻找的是分类面。
通俗地讲,如果输入是x,样本标注的是y,判别式模型是估计条件概率P(y|x),生成式模型是估计他们的联合概率P(x,y)。
●由生成式模型可以产生判别式模型,但是由判别式模型没法产生生成式模型。
●生成式模型更普遍适用;判别式模型更直接,目标性更强。
(2) 无监督学习
无监督学习是试图学习或者提取数据背后的数据特征,常见的算法有聚类、降维、文本处理(特征提取)。
2、按照类型分
(1) 分类
(2) 回归
(3) 聚类
(4) 降维
三、数据标准化
1、数据标准化的目的
一是消除量纲(单位)的影响,二是消除极值。
2、数据标准化有三种方法:
(1)StandardScaler
使数据处理为符合正态分布,用原数据减去均值,然后再除以方差。
import sklearn.preprocessing as pp
x=[
[1,2,3,4],
[5,6,7,8],
[3,5,7,8],
[9,2,3,1]
]
####1.第一种方式:StandardScaler标准化
ss=pp.StandardScaler()
ss.fit(x)
#均值
print(ss.mean_)
#方差
print(ss.var_)
#缩放比例
print(ss.scale_)
print("------")
#对原数据进行转换,标准化
print(ss.transform(x))
(2)MinMaxScaler
极大极小值方法,按照数据最大最小的范围(通常是0到1),对数据进行缩放。
####2.第二种方式:MinMaxScaler标准化
s2=pp.MinMaxScaler()
s2.fit(x)
print(s2.data_max_)
print(s2.data_min_)
print(s2.transform(x))
(3)Normalization
正则化方法,是将数据缩放到单位的向量,是基于向量来算的,可以用于文本数据的标准化。
print("2.第三种方式:Normalizer")
s3=pp.Normalizer()
s3.fit(x)
print(s3.transform(x))
四、模型评估的方法
分类模型:
1、ROC曲线
2、AUC值
3、混淆矩阵
混淆矩阵也叫F值计算法,如下图所示,将预测值和真实值做成一个矩阵,得出各个指标。
那么:
F值调和了召回率和精准率。
五、算法的选择过程
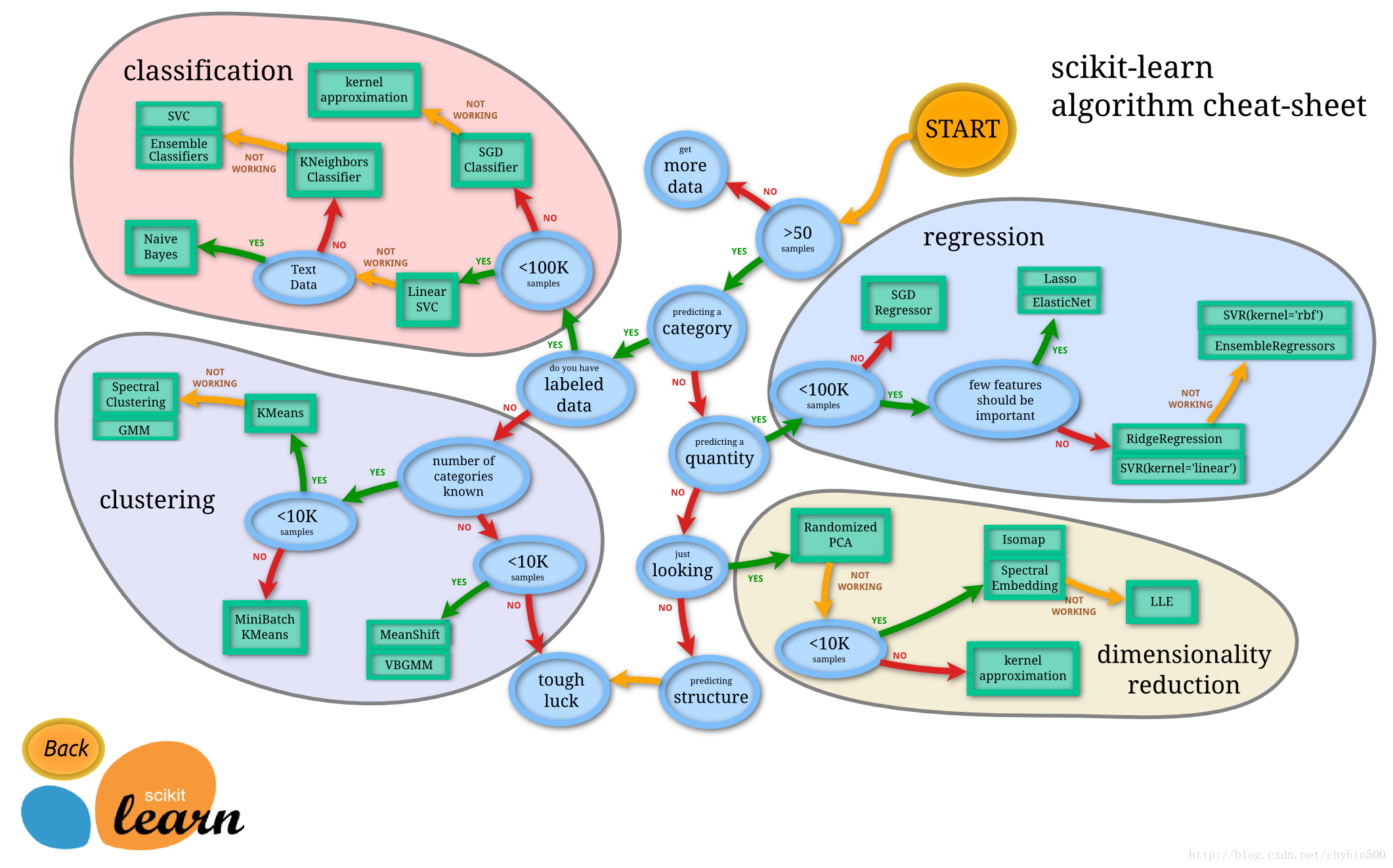
中文版: