机器学习1-基础知识
《机器学习》第2章-模型评估与选择
《统计学习方法》第1章-统计学习方法概论
1. 机器学习三要素
方法=模型+策略+算法
- 模型:要学习的条件概率分布或者决策函数
- 策略:按照什么样的准则学习或者选择最佳模型
- 经验风险最小化:
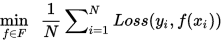
- 结构风险最小化:即正则化(regularization),在经验风险的基础上增加表示模型复杂度的正则化项
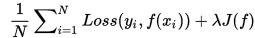
- 经验风险最小化:
- 算法:模型的具体计算方法,一般指最优化方法
2. 模型评估
- 简单交叉验证:随机地将数据集分为两个部分,一部分作为训练集,另一部分作为测试集
- 训练/测试集的划分要尽可能地保持数据分布的一致性
- 交叉验证法cross validation:(1)将数据集划分为k个大小相等的互斥子集,

(2)每次使用k -1个子集的数据训练模型,剩下的一个子集用于测试模型。从而可以进行k 次训练和测试;(3)选出k 次测试中平均测试误差最小的模型- 留一法:
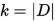
- 留一法:
- bootstrapping法:给定包含m个样本的数据集D,每次随机从D中有放回地抽样出一个样本,重复执行m次,生成新的数据集S。
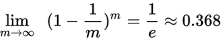
即通过bootstrap sampling方法,原数据集D中仍然越有1/3的样本没有出现在数据集S中。没有出现的数据样本D-S可以作为测试集用于测试,这样的测试结果成为包外估计out-of-bag estimation
3. 性能度量
- 错误率与精度:
- 错误率:分类错误的样本数占样本总数的比例
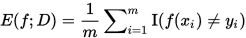
- 精度:分类正确的样本数占样本总数的比例
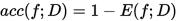
- 错误率:分类错误的样本数占样本总数的比例
- 查准率、查全率:
* 二分类问题的TP/FP/TN/FN

- 查准率P:所有被判断有病的样本中真正有病的概率
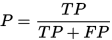
- 查全率R:所有被判断有病的的样本占真正有病的样本的比率

- F1值:查准率和查全率的调和平均值

- 查准率和查全率相互矛盾。对于一个测试样本,通过设置不同的阈值,则分类器对样本的预测结果大于该阈值则判为正例,小于该阈值则判为负例,每个阈值对应一个(查全率,查准率)数据点。所有阈值的对应点就组成了P-R曲线
- 如果一个学习器的P-R曲线被另一个学习器完全包住,则可断言后者的性能优于前者

- 如果一个学习器的P-R曲线被另一个学习器完全包住,则可断言后者的性能优于前者
- 查准率P:所有被判断有病的样本中真正有病的概率
- ROC和AUC:
- ROC曲线:
- 纵轴为“真正例率”(true positive rate, TPR),即查全率

- 横轴为“假正例率(false positive rate, FPR),即所有没病的样本中被错判为有病的概率


- 纵轴为“真正例率”(true positive rate, TPR),即查全率
- AUC(area under ROC curve):ROC曲线下的面积,AUC值越大,则学习器性能越好
- 和P-R曲线相比,ROC曲线更具有鲁棒性,不容易受到样本变化的影响

- ROC曲线:




4. 偏差bias与方差variance
- 缘由:算法在不同训练集上学得的结果有可能不同,即便这些训练集来自于同一个分布
- 假设:对某个测试样本
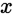 ,令
,令 为
为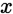 在数据集中的标记,
在数据集中的标记,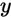 为
为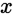 的真实标记,
的真实标记, 为某个训练集
为某个训练集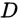 上学到的模型
上学到的模型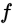 在
在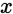 上的预测输出。以回归任务为例:
上的预测输出。以回归任务为例:
-
学习算法在不同数据集上的期望预测为
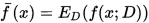
-
使用样本数相同的不同训练集产生的预测结果的方差为
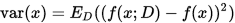
-
噪声为
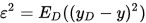
假定噪声期望为0,即
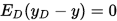
-
偏差(bias)为期望输出与真实标记的差别,即
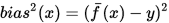
注意:偏差是一个不随测试集D变化的常数
-
- 对算法的期望泛化误差进行分解:
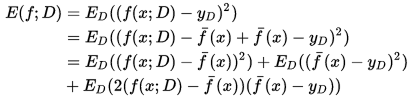
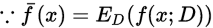


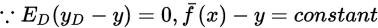
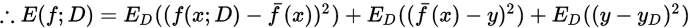
于是,返回误差可以理解为方差、偏差与噪声之和
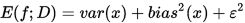
- 偏差:学习算法的期望误差与真实结果的偏离程度,刻画了学习算法本身的拟合能力
- 方差:同样大小的训练集的变动所导致的学习性能的变化,刻画了数据扰动所造成的影响
- 噪声:在当前任务下任何学习算法所能达到的期望泛化误差的下限,刻画了学习问题本身的难度。表征了数据集的质量(食材的好坏)


- 偏差-方差权衡:
- 欠拟合时,偏差主导了泛化误差率,训练数据的扰动不足以使学习器发生显著变化
- 过拟合时,方差主导了泛化误差率,学习器的拟合能力非常强,训练数据发生的轻微扰动都导致学习器发生显著变化

