JMeter关联的实现
前言:下文中会多次使用到【BeanShell Sampler】和【Debug Sampler】,前者其实是起到一个mock server的作用,返回自定义的响应结果,后者能够输出JMeter的变量情况。
1 关联的释义与简单示例
接口测试中的所谓关联,就是将服务器返回结果中的一个值(这个值在接口响应前并不预知)提取出来并保存为一个参数,传递给下一个接口作为条件使用。
豆瓣的API貌似被关闭了,幸好还有一个网站可以调用,免注册,使用比较方便,网址贴上。下面的例子将以这个网站的 API地址 为例进行演示。
接下来的测试场景是这样的:
- 请求 getRegionProvince 接口,得到包含各个省份 code 的列表,并在这个列表里提取北京的 code
- 将北京的 code 作为getSupportCityDataSet接口 theRegionCode 参数的参数值,请求接口得到北京下辖的行政区域列表。

getRegionProvince的接口说明如下:
GET /WebServices/WeatherWS.asmx/getRegionDataset? HTTP/1.1
Host: ws.webxml.com.cn
HTTP/1.1 200 OK
Content-Type: text/xml; charset=utf-8
Content-Length: length
<?xml version="1.0" encoding="utf-8"?>
<DataSet xmlns="http://WebXml.com.cn/">
<schema xmlns="http://www.w3.org/2001/XMLSchema">schema</schema>xml</DataSet>
getSupportCityDataSet的接口说明如下:
GET /WebServices/WeatherWS.asmx/getSupportCityDataset?theRegionCode=string HTTP/1.1
Host: ws.webxml.com.cn
HTTP/1.1 200 OK
Content-Type: text/xml; charset=utf-8
Content-Length: length
<?xml version="1.0" encoding="utf-8"?>
<DataSet xmlns="http://WebXml.com.cn/">
<schema xmlns="http://www.w3.org/2001/XMLSchema">schema</schema>xml</DataSet>
根据上面的接口说明,先建立下面的脚本:

运行脚本,结果树的响应数据(为节省篇幅,只保留了小部分数据):
<?xml version="1.0" encoding="utf-8"?>
<DataSet xmlns="http://WebXml.com.cn/">
<xs:schema id="getRegion" xmlns="" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xs:element name="getRegion" msdata:IsDataSet="true" msdata:UseCurrentLocale="true">
<xs:complexType>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Province">
<xs:complexType>
<xs:sequence>
<xs:element name="RegionID" type="xs:string" minOccurs="0" />
<xs:element name="RegionName" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="Country">
<xs:complexType>
<xs:sequence>
<xs:element name="RegionID" type="xs:string" minOccurs="0" />
<xs:element name="RegionName" type="xs:string" minOccurs="0" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
</xs:element>
</xs:schema>
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1">
<getRegion xmlns="">
<Province diffgr:id="Province5" msdata:rowOrder="4">
<RegionID>3117</RegionID>
<RegionName>河北</RegionName>
</Province>
<Province diffgr:id="Province6" msdata:rowOrder="5">
<RegionID>3118</RegionID>
<RegionName>河南</RegionName>
</Province>
<Province diffgr:id="Province7" msdata:rowOrder="6">
<RegionID>3119</RegionID>
<RegionName>山东</RegionName>
</Province>
<Province diffgr:id="Province29" msdata:rowOrder="28" diffgr:hasChanges="inserted">
<RegionID>311101</RegionID>
<RegionName>北京</RegionName>
</Province>
<Country diffgr:id="Country1" msdata:rowOrder="0">
<RegionID>3320</RegionID>
<RegionName>阿尔及利亚</RegionName>
</Country>
<Country diffgr:id="Country2" msdata:rowOrder="1">
<RegionID>3522</RegionID>
<RegionName>阿根廷</RegionName>
</Country>
<Country diffgr:id="Country3" msdata:rowOrder="2">
<RegionID>3170</RegionID>
<RegionName>阿曼</RegionName>
</Country>
</getRegion>
</diffgr:diffgram>
</DataSet>
我们可以看到响应结果中北京的RegionID是311101,但如何将它提取出来并保存到变量中呢?这就要用到【正则表达式提取器】了。在HTTP请求【getRegionDataset】上添加【后置处理器】-【正则表达式提取器】,正则表达式和正则表达式提取器下文会详细解析。

再将第二个接口写入sampler(取样器)中,注意${code}的写法,代表对code这个变量的引用

运行脚本,查看结果树请求信息:

2 常用正则表达式详解
正则表达式描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式是相对繁琐抽象的,理解和记忆难度较高,因此这里对JMeter中能用到的正则表达式语法(主要是限定符)进行一下讲解。
| 字 符 | 描 述 |
|---|---|
| . | 匹配除换行符 \n 之外的任何单字符 |
| * | 贪婪,匹配前面的子表达式零次或多次,等价于{0,} |
| + | 占有,匹配前面的子表达式一次或多次,等价于{1,} |
| ? | 懒惰,匹配前面的子表达式零次或一次 ,等价于 {0,1} |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如a{3}匹配“aaaaa”,能匹配到“aaa” |
| {n,m} | 重复n到m次,例如正则 “a{3,4}” 将a重复匹配3次或者4次 |
| *? | 重复任意次,但尽可能少重复,如 “acbacb” 正则 “a.*?b” 只会取到第一个"acb" |
| +? | 重复1次或更多次,但尽可能少重复,与上面一样,不同的是至少重复一次 |
| ?? | 重复0次或1次,但尽可能少重复,如 “aaacb” 正则 “a.??b” 只会取到最后的三个字符"acb" |
| {n,m}? | 重复n到m次,但尽可能少重复,如 “aaaaaaaa” 正则 “a{0,m}” 因为最少是0次所以取到结果为空 |
| {n,}? | 重复n次以上,但尽可能少重复,如 “aaaaaaa” 正则 “a{1,}” 最少是1次所以取到结果为 “a” |
部分表达式使用【正则表达式测试器】实测结果如下:
- *:0次或多次,因为0个也被能匹配,所以b、c和末尾被匹配成空
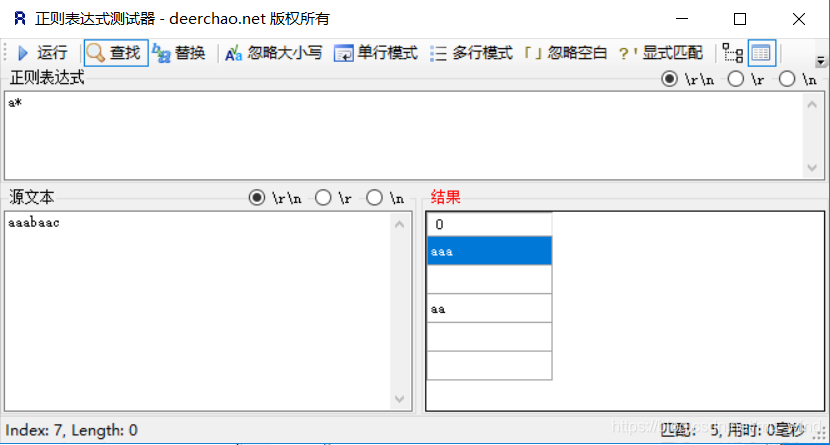
- +:一个或多个,因为至少要匹配一个,不会有空字符串
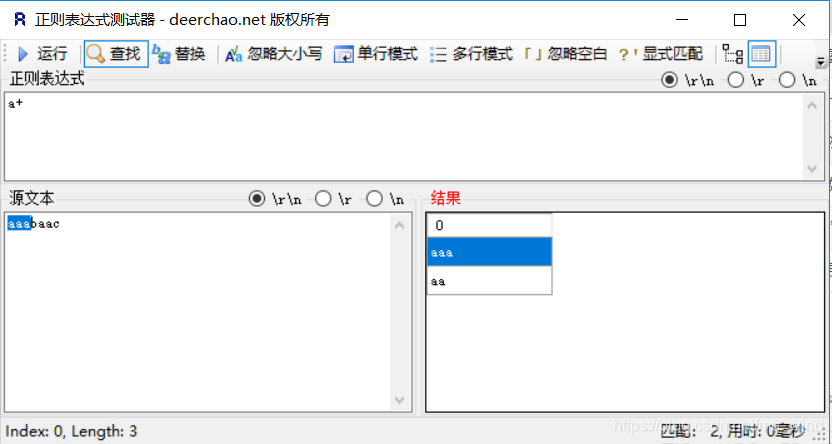
- ?:0个或一个,同*一样,没有a的被匹配成空字符串

- a{n}:

- a{n,m}:

- a{n,}:
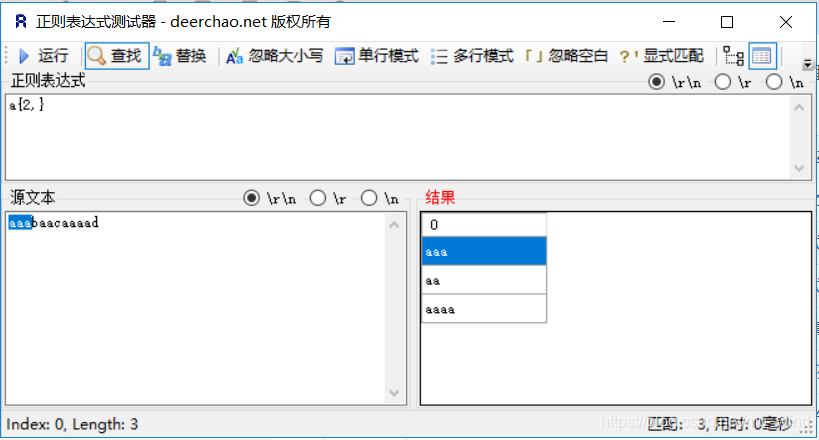
3 正则表达式提取器
正则表达式提取器一般在取样器上创建,它的作用是在取样器(包括HTTP请求和BeanShell Sampler及其他取样器)的结果中按照一定的规则提取特定的值,并保存到内存中的某一个字段上,正则表达式所在的取样器之后的组件,都能通过引用方式(格式:${XXX})使用该值。

3.1 参数详解
| 名称 | 描述 | 必须 |
|---|---|---|
| 名称 | 脚本中显示的这个元件的描述性名称 | 是 |
| Apply to | Main sample only:仅适用于主样本,默认用这个就可以了 | 是 |
| Field to check | 要检查的响应字段,即在取样器响应内容的哪个区域进行匹配 | 是 |
| Name of created variable | 引用名称,即匹配到的变量存储的名称,一般会有[refname]_g(匹配数量)、[refname]_g0 (整体)、[refname]_gn(某个具体匹配值)等多个变量, | 是 |
| Regular Expression | 正则表达式,用于分析响应数据的正则表达式,除非使用$0$组,否则必须至少包含一组括号 | 是 |
| Template | 模板,如果在正则表达式中有多列结果,则可以是$2$$3$等等,表示解析到的第几个值给title,如:$1$表示解析到的第1个值 | 是 |
| Match No. (0 for Random) | 匹配数字,取第几行,0代表随机取值,-1代表全部取值,1、2、3等表示多行返回值取第几个值。 | 是 |
| Default Value | 缺省值,如果表达式没有取得到值,就使用这个默认值 | 是 |
| Use empty default value | 勾选此项后,如果未提取到值,则给变量赋予空字符串,而不是null | 是 |
3.2 用法示例
假如响应内容是"ccBBmmAABBAAddBBAA",想在该响应内容中提取“AAddBB”并存储到参数【test】中,该如何处理?首先,观察待匹配字符串的左右边界分别是"BB"和"AA",那么正则表达式应写成"BB(.+?)AA",在【正则表达式测试器】中测试一下:

可以看到,第1列(列从0开始计数)第二行是我们想要的结果,因此【正则表达式提取器】中按下图填写:

BeanShell Sampler在这里仅仅是提供我们想要的响应内容,方便测试。

运行后查看结果树:

4 JSON值提取
使用【正则表达式提取器】去提取数据,对于响应结果是HTML格式的接口还比较方便,但对于JSON格式的响应结果就有点无能为力了。下面介绍一个专门处理JSON格式响应数据的元件【JSON Extractor】。

参数详解:
| 名称 | 描述 | 必须 |
|---|---|---|
| Name | 脚本中显示的这个元件的描述性名称 | 是 |
| Variable name | 匹配到的数据存储的变量名称,后续可以使用${variable name}引用它 | 是 |
| JSON Path Expressions | JSON路径表达式 | 是 |
| Default Values | 默认值,如果JSON 路径表达式未能匹配到值,将使用该默认值 | 是 |
| Match No. (0 for Random) | 如果匹配到多个结果,选择使用哪个。0代表随机,-1代表全部,x代表第x个 | 是 |
| Compute concatenation var | 勾选此项后,如果匹配到多个结果,JMeter会使用","将他们连接起来,存储在的变量中 | 是 |
示例演示:
假如接口返回下面的JSON数据,我们想在其中提取“周芷若”到“name”参数中。
{
"status":200,
"data":[{"id":101,"name":"张无忌"},{"id":102,"name":"周芷若"}]
}
首先,构造脚本结果如下图,【BeanShell Sampler】作为mock server返回上面的数据:

在【BeanShell Sampler】下面添加【后置处理器】–【JSON Extractor】

这里解释一下【JSON Path expression】的写法,首先"$.“这部分是固定写法,“data"表示在JSON串以"data"为key获取value,也就是”[{“id”:101,“name”:“张无忌”},{“id”:102,“name”:“周芷若”}]”。
而这段字符串是JSONArray(JSON数组)格式,里面有两个JSONObject(JSON对象),第二个JSONObject是我们需要的,因此再按索引值"1"去获取,也就是"data"后面写"[1]",写到这里,我们得到了"{“id”:102,“name”:“周芷若”}"这个JSONObject,接下来再根据"name"这个key去获取相应的值,就得到"周芷若"了。
运行脚本,查看结果树中的【Debug Sampler】的响应数据:

后来在自己开发接口自动化框架的过程中,借鉴JMeter的这个功能,做了一个工具类,在响应结果是JSON串的接口中提取数据十分方便。
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author guozhengMu
* @version 1.0
* @date 2018/12/20 13:07
* @description 根据自定义的字符串解析提取json中的特定内容
* @modify
*/
public class JsonPathExpression {
public static void main(String[] args) {
String str = "{\"data\" : {\"deth\" : {\"bids\" : [[\"3.637\", \"360000\"]],\"asks\" : [[\"4.273\", \"662\"],[[{\"a\":[1,2]}]]]}}}";
// String result = jsonPathExpression("{\"status\" : 200,\"employees\" : [{\"firstName\" : \"Bill\",\"lastName\" : \"Gates\"}, {\"firstName\" : \"George\",\"lastName\" : \"Bush\"}]}", "$.employees[1].firstName");
String result = jsonPathExpression(str, "$.data.deth.asks[1].[0].[0].a[1]");
System.out.println(result);
}
/**
* 根据路径表达式解析JSON
*
* @param jsonString 待处理的字符串
* @param matcher 路径表达式
* @return
*/
public static String jsonPathExpression(String jsonString, String matcher) {
String[] jsons = matcher.split("\\.");
JSONObject object = JSON.parseObject(jsonString);
JSONArray array = new JSONArray();
String result = "";
int index;
for (int i = 1; i < jsons.length; i++) {
if (jsons[i].contains("[")) {
// 解析数字
index = getIndex(jsons[i]);
if (i == jsons.length - 1) { // 最后一层
// 特殊情况处理
if (jsons[i].length() <= 3) {
// []必然是从array中取值
result = array.getString(index);
} else {
array = object.getJSONArray(jsons[i].split("\\[")[0]);
result = array.getString(index);
}
} else { // 不是最后一层
if (jsons[i].length() <= 3) {
try {
array = array.getJSONArray(index);
} catch (Exception e) {
object = array.getJSONObject(index);
}
} else {
// 不知道下一层是array还是object
try {
array = object.getJSONArray(jsons[i].split("\\[")[0]).getJSONArray(index);
} catch (Exception e) {
object = object.getJSONArray(jsons[i].split("\\[")[0]).getJSONObject(index);
}
}
}
} else {
if (i != jsons.length - 1) {
object = object.getJSONObject(jsons[i]);
} else {
result = object.getString(jsons[i]);
}
}
}
return result;
}
/**
* 将字符串中的数字解析出来
*
* @param string:待处理的字符串
* @return
*/
public static int getIndex(String string) {
try {
String regEx = "[^0-9]";
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(string);
String index = matcher.replaceAll("").trim();
return Integer.valueOf(index);
} catch (Exception e) {
return 0;
}
}
}
5 特殊场景
5.1 提取多个值
场景描述:
- 响应结果:
{
"result" : {
"similar" : [{
"id" : "us-B072HFDHKY",
"asin" : "B072HFDHKY"
}, {
"id" : "us-B073WM827B",
"asin" : "B073WM827B"
}, {
"id" : "us-B07GY17KFZ",
"asin" : "B07GY17KFZ"
}, {
"id" : "us-B076NYPS7M",
"asin" : "B076NYPS7M"
}, {
"id" : "us-B07NSBBX7L",
"asin" : "B07NSBBX7L"
}, {
"id" : "us-B077W9GHDV",
"asin" : "B077W9GHDV"
}
]
},
"code" : 0,
"message" : "操作成功!"
}
- 实现目标:在响应结果中前3个 asin 的值。
以上场景,响应结果是JSON格式,在正常情况下,使用【后置处理器】中的【JSON Extractor】显然是很方便的(提取路径:$.result.similar[0].asin 即可获取第一个 asin 的值)。但由于要提取不止一个 asin 值,【JSON Extractor】就不太适用了,这时候要用到【正则表达式提取器】。
- 建立下面的脚本结构:

【BeanShell Sampler】的作用依然是模拟接口响应:
return "{\"result\":{\"similar\":[{\"id\":\"us-B072HFDHKY\",\"asin\":\"B072HFDHKY\"},{\"id\":\"us-B073WM827B\",\"asin\":\"B073WM827B\"},{\"id\":\"us-B07GY17KFZ\",\"asin\":\"B07GY17KFZ\"},{\"id\":\"us-B076NYPS7M\",\"asin\":\"B076NYPS7M\"},{\"id\":\"us-B07NSBBX7L\",\"asin\":\"B07NSBBX7L\"},{\"id\":\"us-B077W9GHDV\",\"asin\":\"B077W9GHDV\"}]},\"code\":0,\"message\":\"操作成功!\"}";
- 【正则表达式】:

- 使用提取值:

- 运行脚本,查看结果:

可见,所有 asin 值已经被提取并保存在内存中,后续的组件中可以任意引用。

5.2 多个值合并
如果响应内容是“<name = Author value = Muguozheng>”,我们同时提取到“Author:Muguozheng”、者“Author”、“Muguozheng”作为下次请求参数,该如何做呢?
首先,去【正则表达式试验器】中测试

根据匹配要求和正则表达式的测试结果,【正则表达式提取器】如下:

运行后查看结果树,后面的sampler(取样器)引用规则如下:
- 使用${test}可以引用"Author:Muguozheng"
- 使用${test_g}可以引用"2"这个数值
- 使用${test_g0}可以引用"<name = Author value = Muguozheng>"
- 使用${test_g1}可以引用"Author"
- 使用${test_g2}可以引用"Muguozheng":

5.3 左右边界不好确定
假如响应结果是这么一个字符串:"<name = Readers value = 马云,马化腾,刘强东>",想要提取“马化腾”这个值。
这个例子的难点在于,正则表达式的左右边界无法确定,因为“马化腾”的右边界“,刘强东”也是响应内容中的动态值(这里的动态指的是,下次请求整体的响应内容可能变成"<name = Readers value = 张三,李四,王五>")。这里,正则表达式写成下面的样式即可:

于是,【正则表达式提取器】可以如下图输入:

运行后查看结果树:

5.4 多个匹配结果
在实际工作中,接口响应结果可能是一个集合,具有同样的左右边界,但我们需要的是最新的那条,一般是最后一条。如下,新建一个【Beanshell Sampler】模拟接口:

return "<td>您的验证码是:400836,切勿将验证码告诉他人<td><td>您的验证码是:54297,切勿将验证码告诉他人<td><td>您的验证码是:65291,切勿将验证码告诉他人<td>";
接下来在【Beanshell Sampler】下创建【正则表达式提取器】(匹配数字写-1,表示取所有匹配结果):

添加【Debug Sampler】和【查看结果树】后运行脚本,在【查看结果树】中可以看到,【正则表达式提取器】匹配结果:

code_1=400836
code_1_g=1
code_1_g0=您的验证码是:400836,切勿将
code_1_g1=400836
code_2=54297
code_2_g=1
code_2_g0=您的验证码是:54297,切勿将
code_2_g1=54297
code_3=65291
code_3_g=1
code_3_g0=您的验证码是:65291,切勿将
code_3_g1=65291
code_matchNr=3
那么我们想获得匹配结果的最后一个,该怎么操作呢?这个问题的难点在于,事先无法确定匹配结果的数量,而解决这个难点的关键就在于【code_matchNr】这个参数,它的含义是匹配到的结果的数量,它的值就是最后一个匹配结果的索引。
很明显,取code_${code_matchNr}就等值于code_3,无论匹配结果的数量是多少,code_${code_matchNr}都代表着最后一条结果。
JMeter不支持嵌套引用,所以${code_${code_matchNr}}这种写法是不正确的。想正确引用该值,需要打开【选项】-【函数助手对话框】,选择_V,填入code_${code_matchNr},点击生成:

${_V(code${code_matchNr})} 这个表达式就表示引用了匹配结果的最后一个。
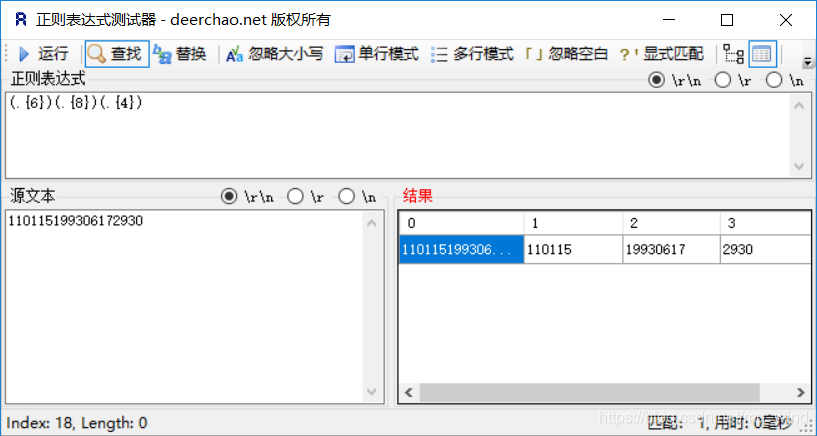
5.5 其他特殊用法
在身份证中匹配提取出生日期,正则表达式如下图: