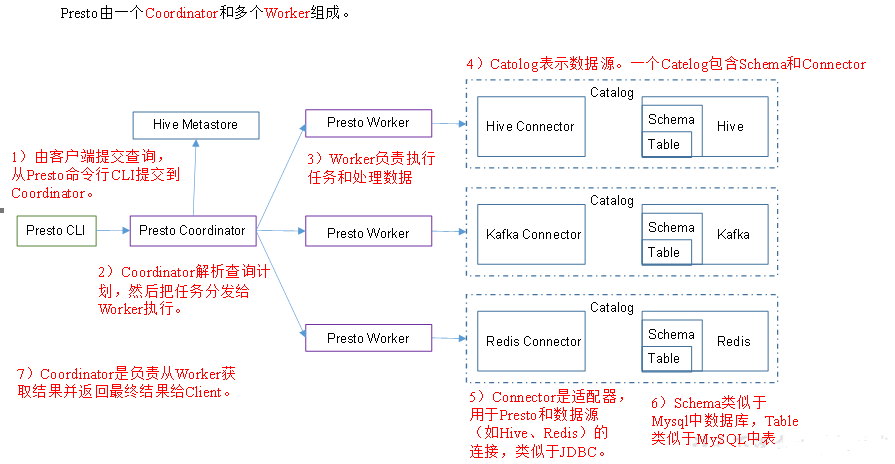
Presto


Presto、Impala性能比较
测试结论:Impala性能稍领先于Presto,但是Presto在数据源支持上非常丰富,包括Hive、图数据库、传统关系型数据库、Redis等。
下载安装
1)下载地址
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.196/presto-server-0.196.tar.gz
Presto Server安装
2)将presto-server-0.196.tar.gz导入hadoop101的/opt/software目录下,并解压到/opt/module目录 [kris@hadoop101 software]$ tar -zxvf presto-server-0.196.tar.gz -C /opt/module/ 3)修改名称为presto [kris@hadoop101 module]$ mv presto-server-0.196/ presto 4)进入到/opt/module/presto目录,并创建存储数据文件夹 [kirs@hadoop101 presto]$ mkdir data 5)进入到/opt/module/presto目录,并创建存储配置文件文件夹 [kirs@hadoop101 presto]$ mkdir etc 6)配置在/opt/module/presto/etc目录下添加jvm.config配置文件 [kirs@hadoop101 etc]$ vim jvm.config


-server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
7)Presto可以支持多个数据源,在Presto里面叫catalog,这里我们配置支持Hive的数据源,配置一个Hive的catalog
[kirs@hadoop101 etc]$ mkdir catalog [kirs@hadoop101 catalog]$ vim hive.properties connector.name=hive-hadoop2 hive.metastore.uri=thrift://hadoop101:9083
8)将hadoop101上的presto分发到hadoop102、hadoop103 [kirs@hadoop101 module]$ xsync presto 9)分发之后,分别进入hadoop101、hadoop102、hadoop103三台主机的/opt/module/presto/etc的路径。配置node属性,node id每个节点都不一样。
[kirs@hadoop101 etc]$vim node.properties node.environment=production node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.data-dir=/opt/module/presto/data [kirs@hadoop102 etc]$vim node.properties node.environment=production node.id=ffffffff-ffff-ffff-ffff-fffffffffffe node.data-dir=/opt/module/presto/data [kirs@hadoop103 etc]$vim node.properties node.environment=production node.id=ffffffff-ffff-ffff-ffff-fffffffffffd node.data-dir=/opt/module/presto/data
10)Presto是由一个coordinator节点和多个worker节点组成。在hadoop101上配置成coordinator,在hadoop102、hadoop103上配置为worker。
(1)hadoop101上配置coordinator节点
[kirs@hadoop101 etc]$ vim config.properties coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8881 query.max-memory=50GB discovery-server.enabled=true discovery.uri=http://hadoop101:8881
(2)hadoop102、hadoop103上配置worker节点
[kirs@hadoop102 etc]$ vim config.properties coordinator=false http-server.http.port=8881 query.max-memory=50GB discovery.uri=http://hadoop101:8881 [kirs@hadoop103 etc]$ vim config.properties coordinator=false http-server.http.port=8881 query.max-memory=50GB discovery.uri=http://hadoop101:8881
启动
11)在/opt/module/hive目录下,启动Hive Metastore,用atguigu角色 nohup bin/hive --service metastore >/dev/null 2>&1 & 12)分别在hadoop101、hadoop102、hadoop103上启动presto server (1)前台启动presto,控制台显示日志 [kirs@hadoop101 presto]$ bin/launcher run [kirs@hadoop102 presto]$ bin/launcher run [kirs@hadoop103 presto]$ bin/launcher run (2)后台启动presto [kirs@hadoop101 presto]$ bin/launcher start [kirs@hadoop102 presto]$ bin/launcher start [kirs@hadoop103 presto]$ bin/launcher start
日志查看路径/opt/module/presto/data/var/log
Presto命令行Client安装--一般没人用
1)下载Presto的客户端
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.196/presto-cli-0.196-executable.jar
2)将presto-cli-0.196-executable.jar上传到hadoop101的/opt/module/presto文件夹下
3)修改文件名称
[kirs@hadoop101 presto]mvpresto−cli−0.196−executable.jarprestocli4)增加执行权限[kirs@hadoop101presto]mvpresto−cli−0.196−executable.jarprestocli4)增加执行权限[kirs@hadoop101presto] chmod +x prestocli
5)启动prestocli
[kirs@hadoop101 presto]$ ./prestocli --server hadoop101:8881 --catalog hive --schema default
6)Presto命令行操作
Presto的命令行操作,相当于hive命令行操作。每个表必须要加上schema。
例如:select * from schema.table limit 100
Presto可视化Client安装
1)将yanagishima-18.0.zip上传到hadoop101的/opt/module目录 2)解压缩yanagishima [kirs@hadoop101 module]$ unzip yanagishima-18.0.zip cd yanagishima-18.0 3)进入到/opt/module/yanagishima-18.0/conf文件夹,编写yanagishima.properties配置 [kirs@hadoop101 conf]$ vim yanagishima.properties jetty.port=7080 presto.datasources=kris-presto presto.coordinator.server.kris-presto=http://hadoop101:8881 catalog.kris-presto=hive schema.kris-presto=default sql.query.engines=presto
4)在/opt/module/yanagishima-18.0路径下启动yanagishima [kirs@hadoop101 yanagishima-18.0]$ nohup bin/yanagishima-start.sh >y.log 2>&1 & 5)启动web页面 http://hadoop101:7080 看到界面,进行查询了。