实验目的
初步认识推荐系统
学会用mapreduce实现复杂的算法
学会系统过滤算法的基本步骤
实验原理
前面我们说过了qq的好友推荐,其实推荐算法是所有机器学习算法中最重要、最基础、最复杂的算法,一个推荐系统的架构,需要综合考虑离线计算、实时计算。需要用到的技术可能还有Flume、Kafka、Redis、Storm、Spark,算法包括ALS矩阵分解、协同过滤、线性回归、余弦相似度等。
1.协同过滤
协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
协同过滤又可分为评比(rating)或者群体过滤(social filtering)。协同过滤以其出色的速度和健壮性,在全球互联网领域炙手可热。
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。简单的说就是:物以类聚,人以群分。
2.协同过滤基本思想
如果两个人对相同商品的打分比较相似,我们就说这两个人比较相似,那么其中一个人买过的东西我们就可以推荐给另一个人,这是基于用户的相似度,我们称之为基于用户的协同过滤。同理,如果同一个人对两个物品打分相似,我们说这两个物品比较相似,我们就可以给购买了其中一个物品的人推荐另一个物品,这就是基于物品的协同过滤。总结来说:
基于用户的协同过滤就是:跟你喜好相似的人喜欢的东西你也很有可能喜欢
基于物品的协同过滤就是:跟你喜欢的东西类似的东西你也可能喜欢
3.协同过滤的实现思路
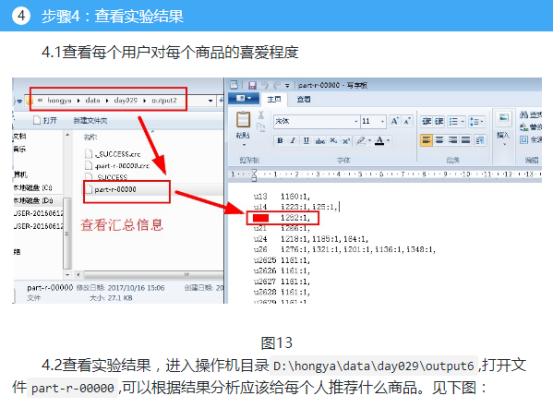
以基于物品的协同过滤为例,第一步我们就是要找到物品之间的相似性,假如我们已经找到了n个商品相互之间的相似性,量化为一个n维矩阵。第二步就是找到要推荐的用户对每个商品的喜爱程度,也就是这个用户给每个商品的打分,假设已经找到了他对n个商品的喜爱程度,量化为一个n维向量(如果不知道他对某个商品的喜爱程度,打分就是0)。第三步我们可以通过将这个相似矩阵乘以这个喜爱向量,就能得到一个新的向量,新的向量的值就代表每个商品给这个用户的推荐指数。
所以主要就是两个问题:相似矩阵、喜爱矩阵(一个用户是喜爱向量、多个用户是喜爱矩阵)。
3.1求相似矩阵
相似性的计算思路比较多,例如根据商品的内容,计算他们的余弦相似度的,这种方法大家可以自行查阅资料。我们计算在喜欢物品i的用户中有多少是喜欢物品j的,也就是同时出现的次数。当一个用户对两个物品都喜欢的时候,我们往往可以认为这两个物品可能属于同一分类。所以我们的相似矩阵就是计算一个同时出现的次数得到。
3.2计算喜爱矩阵
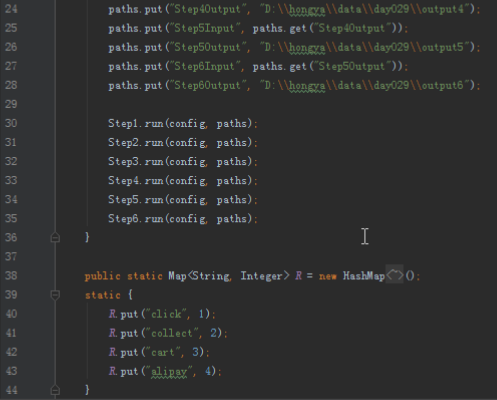
计算一个用户对一个商品的喜爱程度,我们可以根据这个用户的行为得到,最简单的就是买了就是1,不买就是0。实际上这样得到的数据并不能很好的反应真实情况,因为用户行为还有很多,包括浏览、收藏、加购物车、购买等。我们可以通过线性回归的方法去拟合每个行为的权重。我们为了简便,直接假设这四种行为的权重分别为1、2、3、4,也就是说如果用户购买了就说明喜爱程度是4,收藏就说明喜爱程度是2。
4.代码实现协同过滤
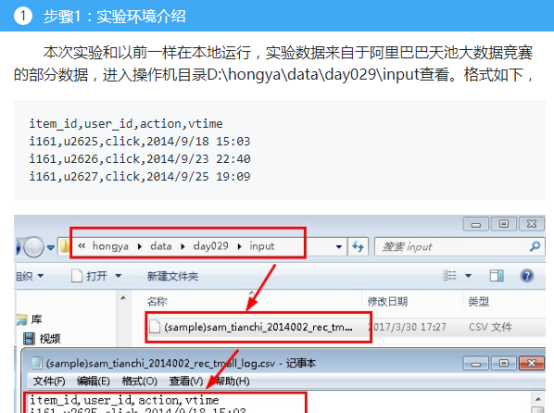
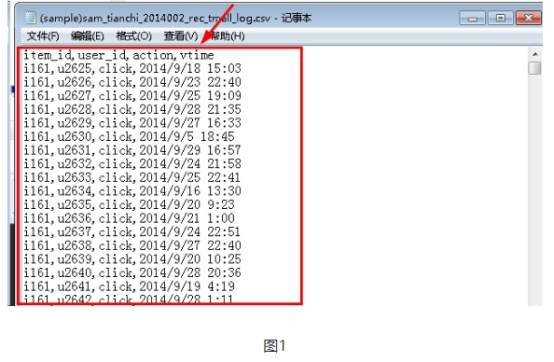
第一步,原始数据清洗。由于我们需要的只是一条url里面的用户id、商品id、行为。所以第一步就是过滤数据,取出关键信息。
第二步,计算相似矩阵。
实验环境
1.操作系统
操作机:Windows_7
操作机默认用户名:hongya,密码:123456
2.实验工具
IntelliJ IDEA

IDEA全称IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
优点:
1)最突出的功能自然是调试(Debug),可以对Java代码,JavaScript,JQuery,Ajax等技术进行调试。其他编辑功能抛开不看,这点远胜Eclipse。
2)首先查看Map类型的对象,如果实现类采用的是哈希映射,则会自动过滤空的Entry实例。不像Eclipse,只能在默认的toString()方法中寻找你所要的key。
3)其次,需要动态Evaluate一个表达式的值,比如我得到了一个类的实例,但是并不知晓它的API,可以通过Code Completion点出它所支持的方法,这点Eclipse无法比拟。
4)最后,在多线程调试的情况下,Log on console的功能可以帮你检查多线程执行的情况。
缺点:
1)插件开发匮乏,比起Eclipse,IDEA只能算是个插件的矮子,目前官方公布的插件不足400个,并且许多插件实质性的东西并没有,可能是IDEA本身就太强大了。
2)在同一页面中只支持单工程,这为开发带来一定的不便,特别是喜欢开发时建一个测试工程来测试部分方法的程序员带来心理上的不认同。
3)匮乏的技术文章,目前网络中能找到的技术支持基本没有,技术文章也少之又少。
4)资源消耗比较大,建个大中型的J2EE项目,启动后基本要200M以上的内存支持,包括安装软件在内,差不多要500M的硬盘空间支持。(由于很多智能功能是实时的,因此包括系统类在内的所有类都被IDEA存放到IDEA的工作路径中)。
特色功能:
智能选择
丰富的导航模式
历史记录功能
JUnit的完美支持
对重构的优越支持
编码辅助
灵活的排版功能
XML的完美支持
动态语法检测
代码检查等等。
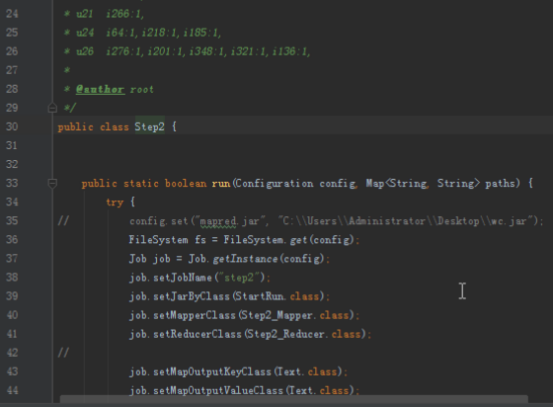
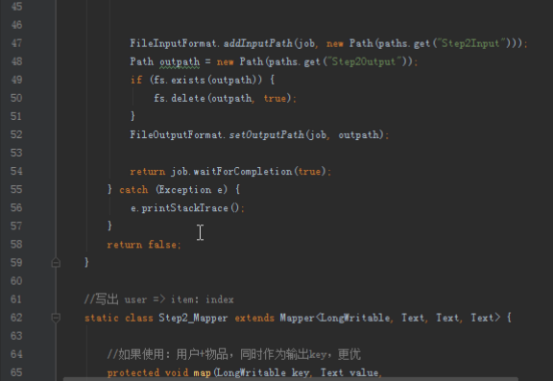
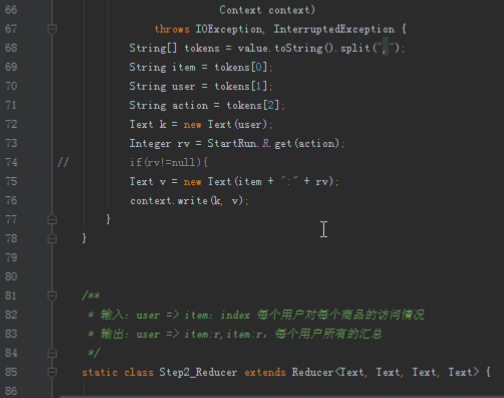
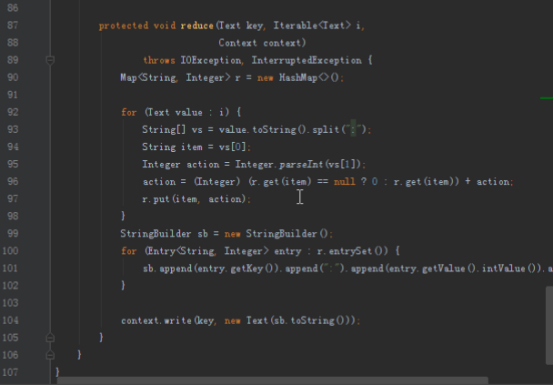
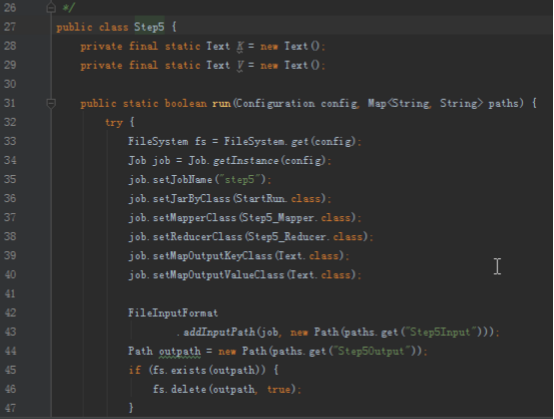
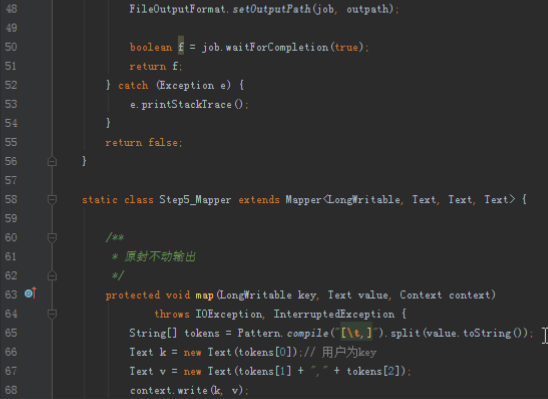
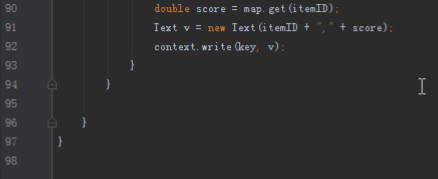
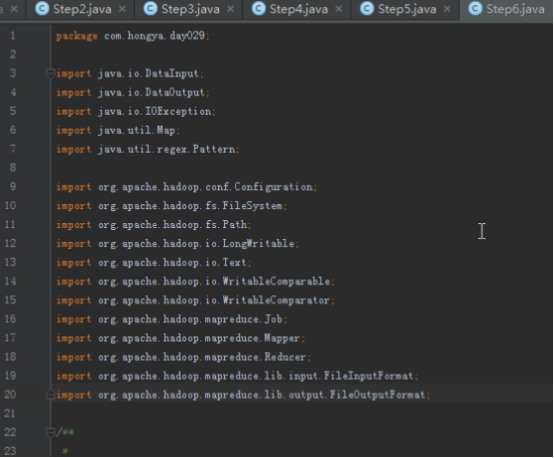
步骤2:代码分析
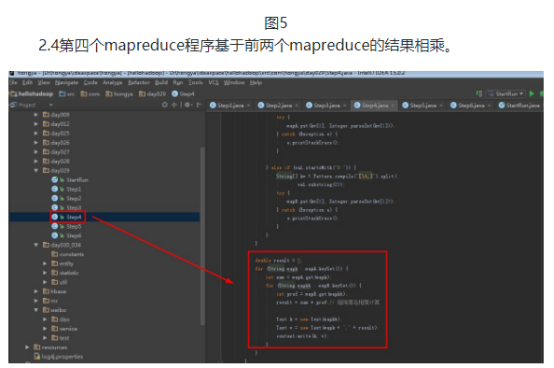
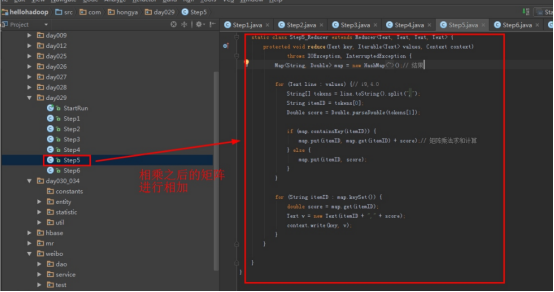
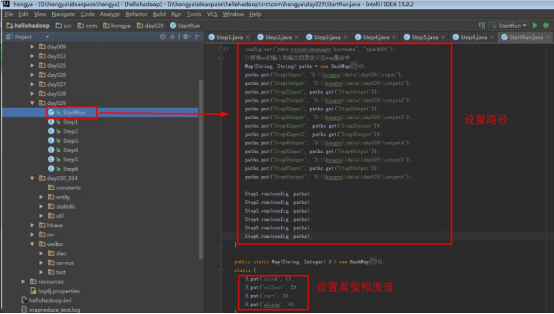
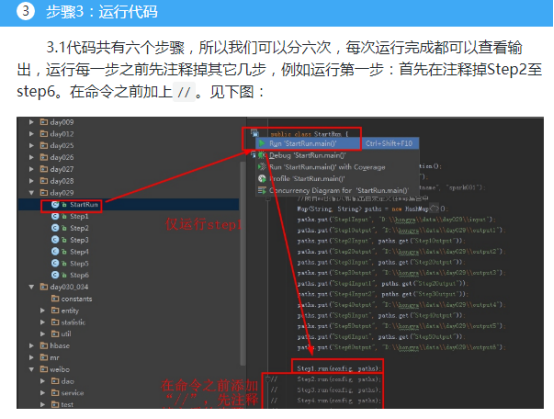
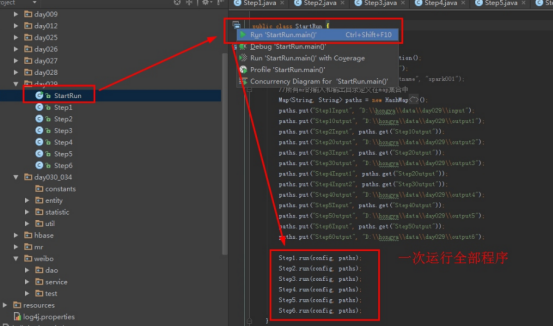
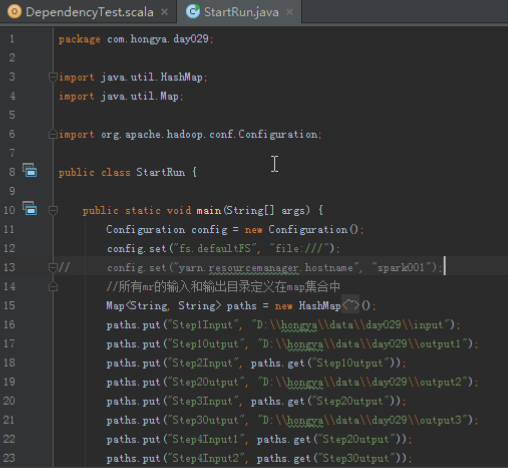
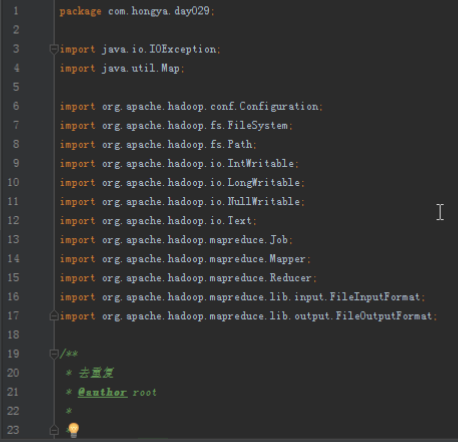
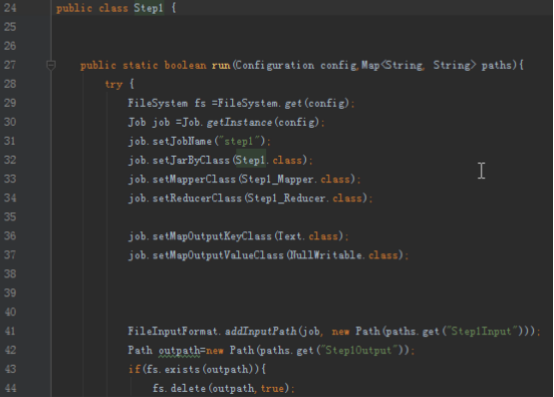
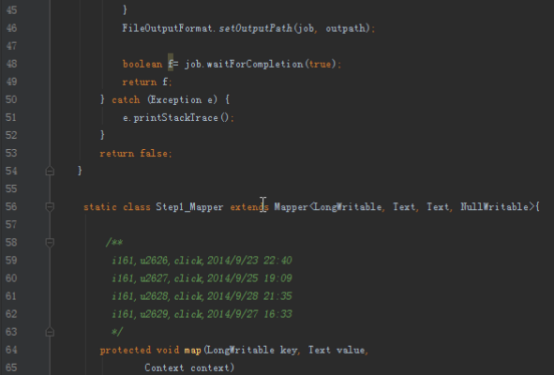
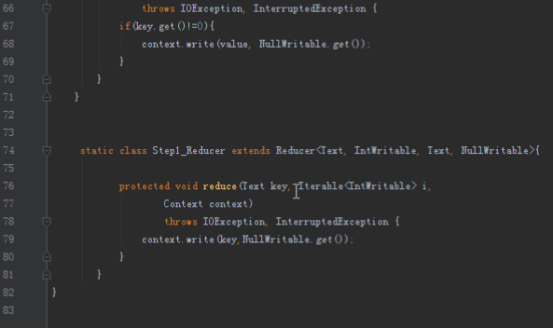
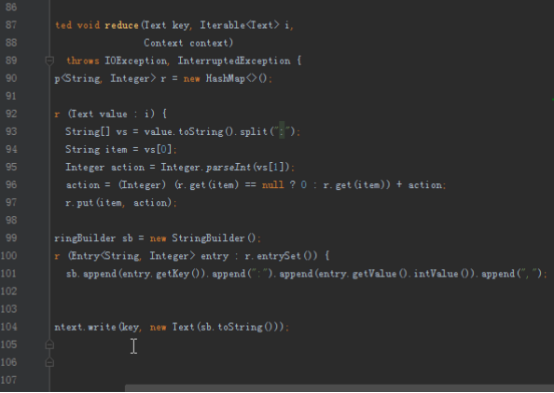
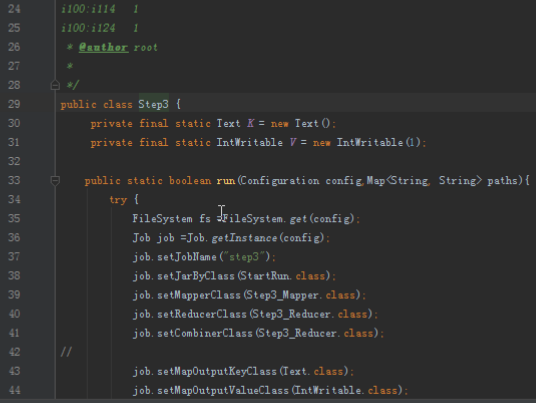
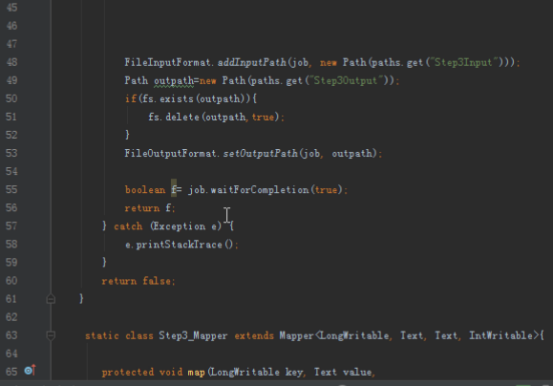
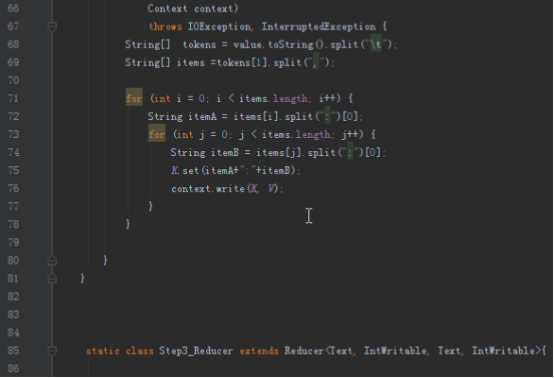
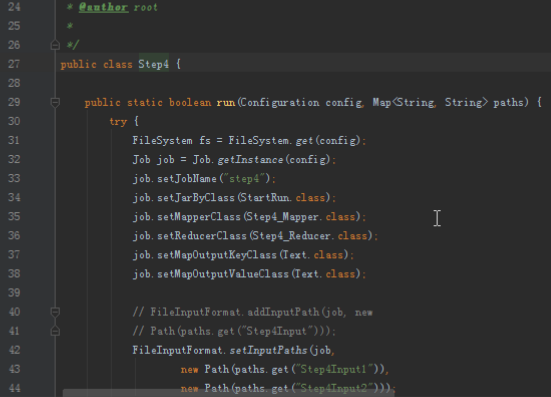
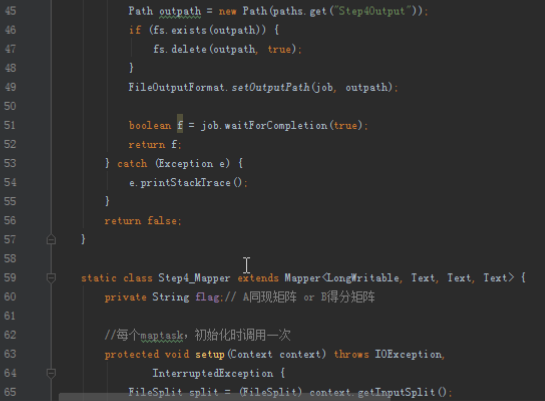
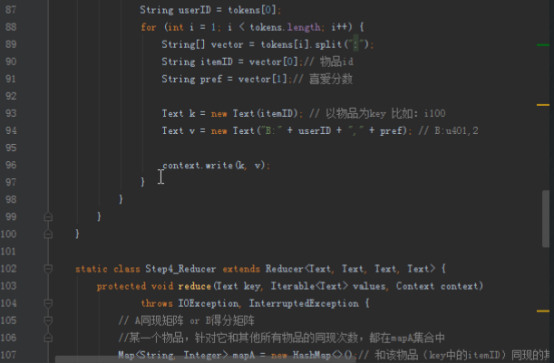
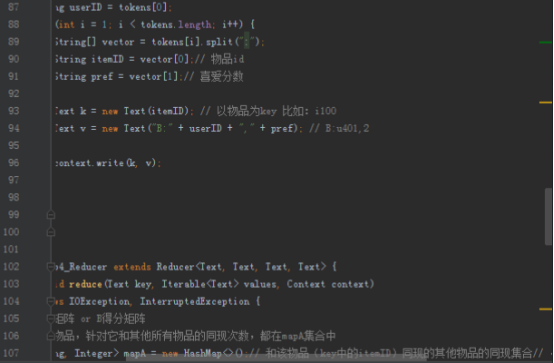
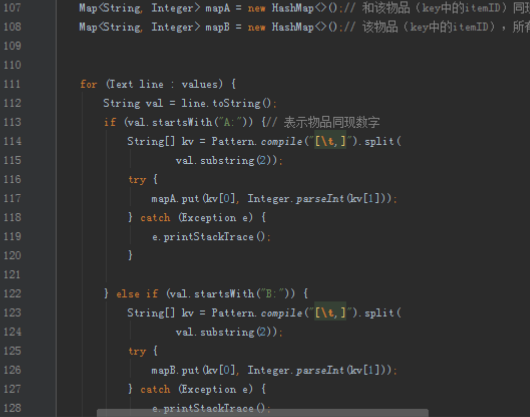
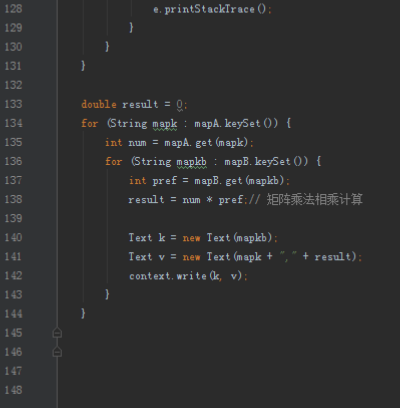
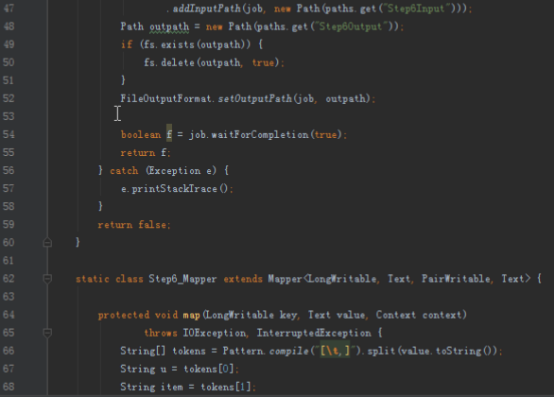
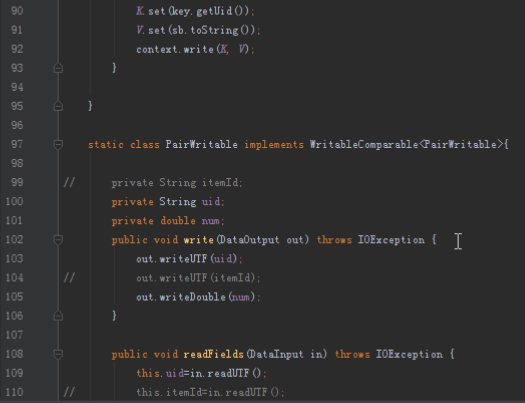
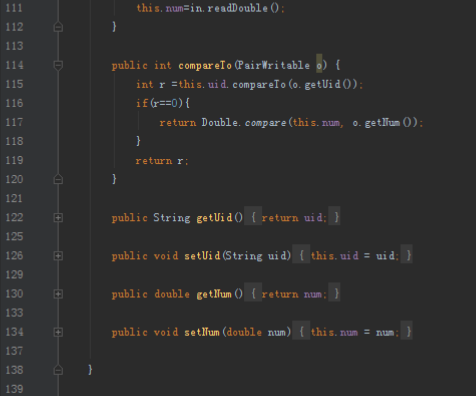
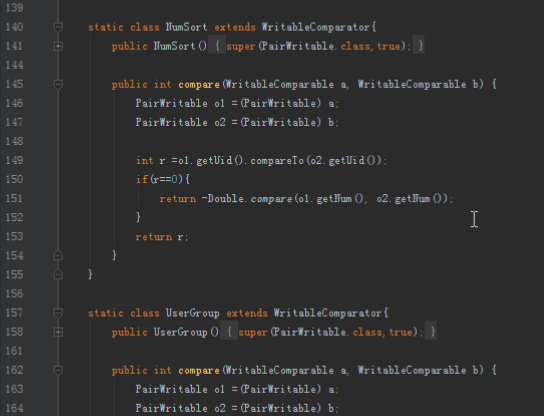
首先操作中打开桌面的IDEA,直接进入hellohadoop|com.hongya|day029下查看实验要用到的代码(其代码文目为:D:\hongya\ideaspace\hellohadoop\src\com\hongya\day029)。本次的逻辑比前几次都复杂,代码量比前几次都大,需要连续跑六个mapred,我们设计的时候尽量每一步简单。
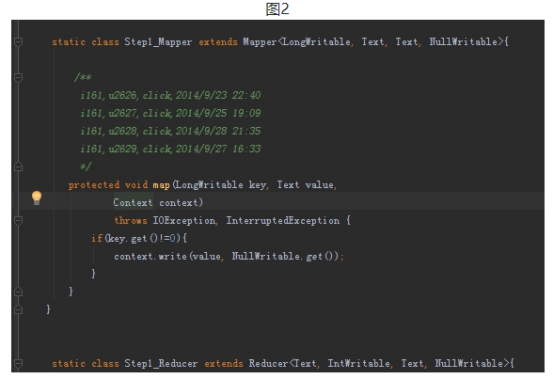
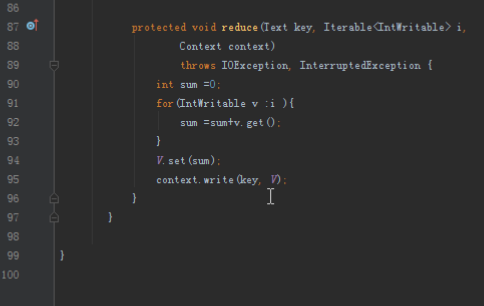
2.1第一个mapreduce程序主要是对数据清洗:
map方法直接写出,reduce方法只写出第一个。