实验目的
了解zookeeper的概念和原理
学会安装zookeeper集群并验证
掌握zookeeper命令使用
实验原理
1.Zookeeper介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。Zookeeper是hadoop的一个子项目。
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
通俗讲就是:在大数据环境中,经常遇到这种问题,一个节点的数据很重要(比如hadoop的namenode),而这个节点万一出了问题怎么办,最简单的方式是给它做个备份,出了问题就切换到备份的节点上。这种方案有两个缺点:第一点,做一个实时的备份是很难的,要时时刻刻保证数据同步对资源消耗很大;另外一点,就需要一个进程监控节点,一旦出现问题就切换到备用节点。万一这个监控进程出问题了怎么办,是否需要再给这个进程做个备份,这样下去就无休止了。
zookeeper的出现解决了这个问题,zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务。首先zookeeper简化了一个选举算法,实现原子广播协议,简称Zab协议。
举个例子:一个zookeeper集群有一个leader,其他的都是follower跟随者(或者observer观察者),这个leader是怎么选举出来的呢?一开始三台机器ABC,分别启动zookeeper以后,发现没有leader,就提议进行leader选举,只要半数以上通过就算成功,过程为:
A提案说,我要选自己,B你同意吗?C你同意吗?B说,我同意选A;C说,我同意选A。(注意,这里超过半数了,其实在现实世界选举已经成功了。但是计算机世界是很严格,另外要理解算法,要继续模拟下去。)
接着B提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;C说,A已经超半数同意当选,B提案无效。
接着C提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;B说,A已经超半数同意当选,C的提案无效。
选举已经产生了Leader,后面的都是follower,只能服从Leader的命令。而且这里还有个小细节,就是其实谁先启动谁当头。
这个过程产生了leader后,zookeeper就可以开始工作了,工作的过程中,理论上每个zookeeper的数据都是一致的,如果某一个节点出了问题,只要还有超过半数的节点正常,那整个集群就可以正常工作,所以zookeeper首先实现了自己的高可用,然后zookeeper还可以保存数据,协调控制数据。
其角色和功能如下:
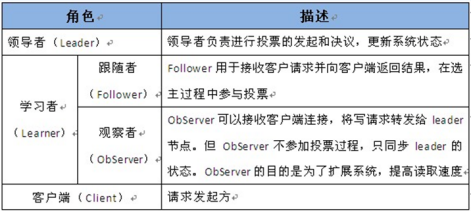
2.Zookeeper用途及特点
刚刚说到zookeeper给自己做了高可用,在大数据环境下,zookeeper主要用于保存数据和协调服务。例如:
Hadoop使用zookeeper的事件处理确保整个集群只有一个NameNode。存储配置信息等。
HBase使用zookeeper的事件处理确保整个集群只有一个HMaster。察觉HRegionServer联机和宕机,存储访问控制列表等。
Kafka使用zookeeper存储消息的offset等信息
Spark使用zookeeper做Master节点的高可用
zookeeper特点:
最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
原子性:更新只能成功或者失败,没有中间状态。
顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
3.zookeeper安装使用
1.集群安装
集群安装需要再多个节点解压zookeeper的安装包,除了配置数据保存的目录,还要配置一个一个节点的id。实验中我们会具体学习。
2.我们以完全分布式安装为例,先进行简单了解:
我们将在三台机器上进行试验,例如这里的三台机器,ip主机名分别为:node6,node7,node8。
1)在三台节点上解压安装包,命令:
tar -zxvf /opt/pkg/zookeeper* -C /opt/soft/
2)添加映射,复制修改配置文件,命令:
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
注意需要添加集群参数:
tickTime=2000
注意这里,修改zookeeer的应用数据保存目录
dataDir=/home/data/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
#zookeeper集群的地址,格式为server.id=ip:2888:3888,这个id是三个节点的名字
ip是虚拟机的主机名
server.1=node6:2888:3888
server.2=node7:2888:3888
server.3=node8:2888:3888
3)配置每个节点的id
刚刚在zoo.cfg配置了一个dataDir和一个server.id,首先创建这个dataDir目录,然后再里面新建一个叫myid的文件,编辑内容。
[root@node6 ~]# mkdir -p /opt/soft/zookeeper-3.4.6/data
[root@node6 ~]# vim /opt/soft/zookeeper-3.4.6/data/myid
myid的内容为zoo.cfg配置的server.id的id,node6为1,node7为2,node8为3.
4)启动集群
和伪分布式一样,分别进入三个节点的zookeeper安装目录,分别输入启动命令(启动程序在bin目录下):
bin/zkServer.sh start
然后分别检查zookeeper节点是否启动成功:
bin/zkServer.sh status
实验环境
1.操作系统
操作机1:Linux_Centos
操作机2:Linux_Centos
操作机3:Linux_Centos
操作机4:Windows_7
操作机1默认用户名:root,密码:123456
操作机2默认用户名:root,密码:123456
操作机3默认用户名:root,密码:123456
操作机4默认用户名:hongya,密码:123456
步骤1:使用xshell登陆集群环境
1.1进入操作机4,点击运行xshell,点击新建,输入名称为node6,主机输入操作机1的IP。见下图:
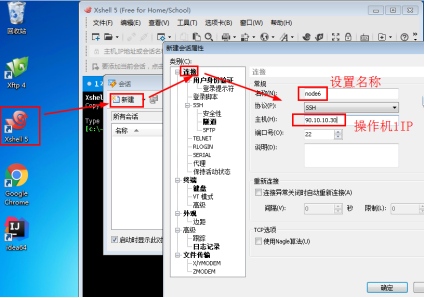
图1
1.2点击用户身份验证,输入用户名:root,密码:123456,点击确定。见下图:
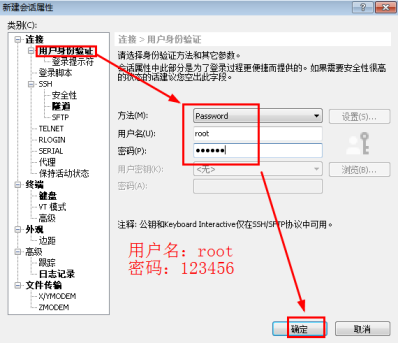
图2
1.3重复以上步骤,连接操作机2和操作机3。其名称分别为node7和node8。然后选中会话点击连接,见下图:

图3
1.4如下图,三个会话都已连接成功。
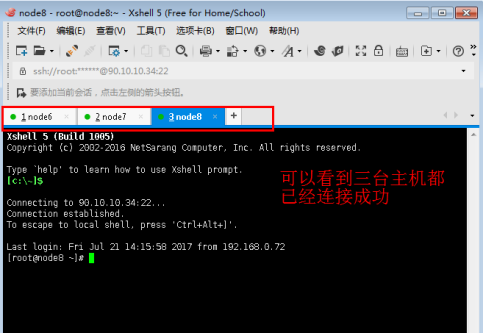
图4
步骤2:配置映射
2.1修改/etc/hosts文件,使其与真实环境中的IP主机名相对应,添加ip和主机名。(三台主机都需要修改,IP地址以实验为准)
vi /etc/hosts
添加内容:
90.10.10.30 node6
90.10.10.24 node7
90.10.10.34 node8

图5
保存退出。
步骤3:免密码登陆
3.1主节点namenode需要控制datanode的启停,所以需要配置namenode到所有节点(包括自身节点)的免密码登陆。(每一台都需要执行,实验中以node6上操作为例)
在namenode生成秘钥
ssh-keygen

图6
3.2将公钥复制到需要免密码登陆的节点上。即设置node6到自己的免密码登陆,node6到node7的免密码登陆,node6到node8的免密码登陆。命令:ssh-copy-id IP(每一台节点都需要执行)
ssh-copy-id node6
ssh-copy-id node7
ssh-copy-id node8
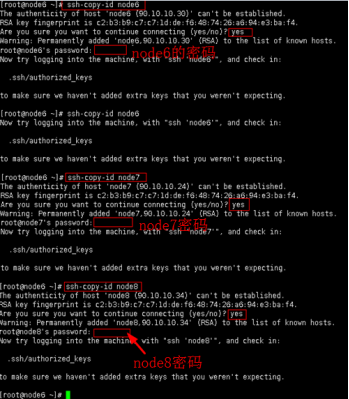
图7
3.3关闭防火墙(每一台都需要执行)
service iptables stop

图8
3.4同步时间(每一台都需要执行)
date -s 10:00

图9
步骤4:搭建伪分布式Zookeeper
4.1使用其中一台,搭建一个伪分布式集群(即单节点),我们在node6中进行实验。找到安装包解压,安装包放在/opt/pkg/里面,解压到一个用户自己的安装目录:
进入相应目录
cd /opt/pkg/
ls
解压安装包并复制到目录/opt/soft/下
tar -zxvf /opt/pkg/zookeeper-3.4.6.tar.gz -C /opt/soft/

图10
4.2进入/opt/soft/下查看安装包
cd /opt/soft/
ls

图11
4.3配置文件,进入zookeeper的conf目录,会有一个zoo_sample.cfg文件,复制一份改名为zoo.cfg。
进入zookeeper的conf目录
cd zookeeper-3.4.6/conf/
复制文件并改名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
查看目录
ls
查看配置文件
vi zoo.cfg
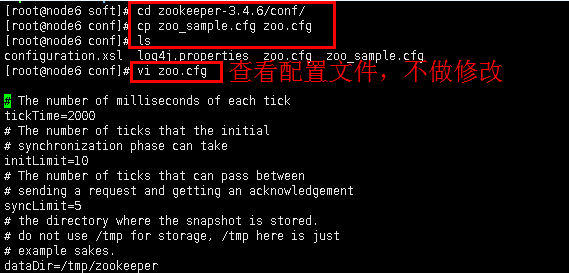
图12
4.4启动测试。进入zookeeper的安装目录,执行bin目录下的zkServe.sh,启动然后查看状态。
cd ..
进入bin目录。
cd bin/
启动zkServe.sh
./zkServer.sh start
查看状态
./zkServer.sh status
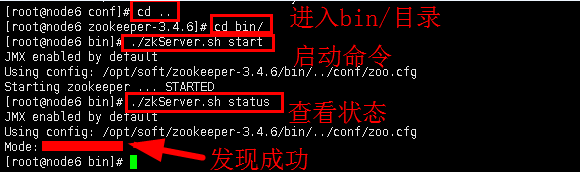
图13
注意:如果查看状态时,如果出现“Error contacting service.It isprobably not running”字样,可能是因为防火墙没有关闭。执行命令“service iptables stop”,然后继续查看状态。
步骤5:搭建集群的Zookeeper
5.1以上步骤中单节点已经建立成功,为了搭建集群,需要把单节点关闭,然后在三台节点同时创建临时目录,并解压zookeeper的安装包,和单节点node6上操作一样,我们可以重复实验步骤4(注:步骤3中三台节点都已进行同样操作,所以这里三台节点只需要重复步骤4即可)。
5.2首先关闭node6 中的zookeeper进程,即关闭单节点,方便开启集群zookeeper。使用命令“jps”查看node6进程,然后使用kill命令杀死“QuorumPeerMain”进程。
查看进程
jps
进程号以实验为准
kill -9 5372
再次查看进程
jps
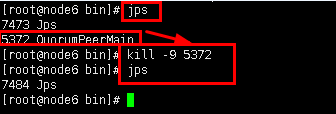
图14
5.3在xshell底部栏中输入命令,可以发送命令到xshell全部会话中(即以下步骤每个节点机器都需执行命令),这样更加方便我们集群搭建。见下图:
cd /opt/pkg/
ls
tar -zxvf /opt/pkg/zookeeper-3.4.6.tar.gz -C /opt/soft/
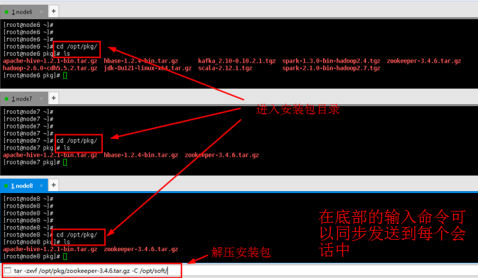
图15
注:这时也可以再次执行关闭防火墙和时间同步命令。(见步骤3.3和3.4,这里不再演示)
5.4进入/opt/soft/下查看安装包,然后进入conf目录下复制配置文件zoo.cfg。(三台节点都需要执行)
cd /opt/soft/
ls
进入zookeeper的conf目录
cd zookeeper-3.4.6/conf/
复制文件并改名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
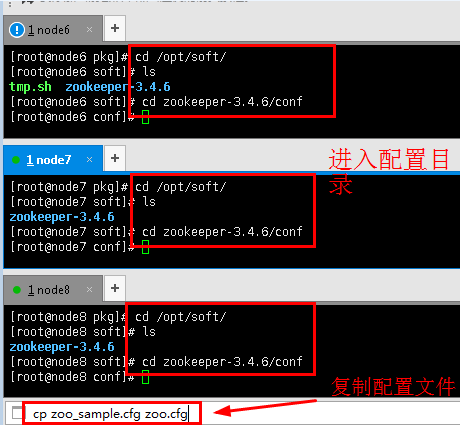
图16
5.5进入zoo.cfg文件,修改内容,注意修改dataDir并添加server集群。(三台节点都需要进行如下操作)
ls
vi zoo.cfg
修改内容:
dataDir=/opt/soft/zookeeper-3.4.6/data //修改zookeeper数据保存目录
添加zookeeper集群,server后面的数字是这个节点的ID,之后会用到:
server.1=node6:2888:3888
server.2=node7:2888:3888
server.3=node8:2888:3888
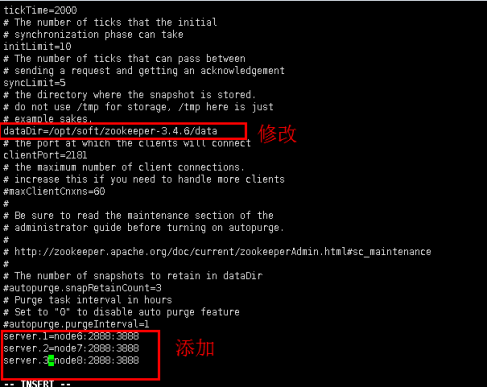
图17
保存退出。
注意:zookeeper集群的地址,格式为server.id=ip:2888:3888,这个id是三个节点的名字, ip是主机ip。
5.6分别在node6、node7、node8三台机器上新建刚刚配置的dataDir目录。(以node6 为例,其他节点上请同学自己建立)
mkdir -p /opt/soft/zookeeper-3.4.6/data

图18
5.7然后分别在node6、node7、node8三台机器的dataDir下新建一个myid文件。
cd /opt/soft/zookeeper-3.4.6
ls
cd data
vi myid
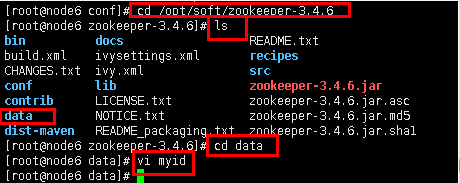
图19
5.8编辑内容为每个节点的id:这里内容分别输入1、2、3,与zoo.cfg文件中的id各个对应,之后保存退出。
图20
5.9在三台机器上启动zookeeper集群,然后查看状态,命令和单节点是一样:
cd ..
进入bin目录。
cd bin/
启动zkServe.sh
./zkServer.sh start
查看状态
./zkServer.sh status

图21
最终状态的结果应该是有一个leader,两个follower
注意:如果进行到步骤5.5,结果中没有leader和follower,而是单节点standalone或其他状态,说明集群启动不成功。这时可以进行如下操作进行修改(三台节点都需要进行如下命令,以node6单个节点截图为例,注意目录变化,命令就不再演示)。
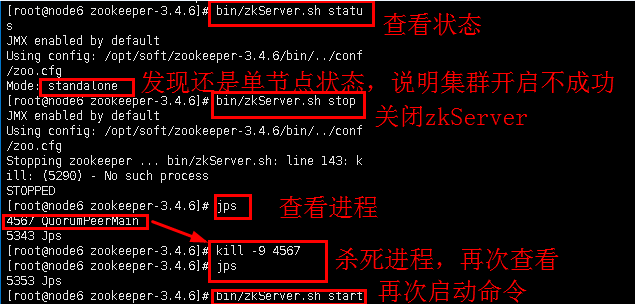
图22
步骤6:使用Zookeeper的客户端命令行工具
6.1启动了zookeeper服务器后,我们可以通过其入口zkCli.sh对其 增加、修改、删除数据。输入命令连上客户端工具,然后输入help命令查看帮助。(以node6上实验为例)。
连接客户端
./zkCli.sh
这一步要注意路径,如果路径为zookeeper-3.4.6,输入命令为:bin/zkCli.sh
help
6.2使用ls查看所有的数据目录。
ls /
6.3还用get查看其中的数据,会显示这个路径的数据、信息。命令格式为:get /path
get /zookeeper

图26
6.4使用create添加节点和数据。格式为:create /path yourdata
create /tmp "i love spark"
查看数据目录
ls /

图27
6.5使用rmr删除数据。
rmr /tmp
再次查看目录
ls /
退出
quit
