这是第二天的学习,这篇随笔相关的也是论文里的3.1的一些学习要点。今天有事,晚上才开始学习,每一天也要不断努力去巩固呀!
(1)表征学习(Representation Learning) : 表征学习可以视为特征学习,而特殊学习的分类又与机器学习相似,分为监督式特征学习和无监督式特征学习,监督式特征学习如神经网络,即你通过足够的训练让这个网络可以判断出事物是什么,达到高的辨别率和完成度。无监督式特征学习是指一堆没被标记过的数据,且网络之前也没有被相关的数据训练过,但这些数据却被用来训练网络,例如各种聚类和变形。一个好的特征学习可以帮助我们更有效的提取出数据的信息从而用于分类或预测。但深度神经网络虽然可以有效地学到数据丰富的特征,但特征难以解读。通常神经网络层数越多,训练成本也越高。
相关网址:https://www.jiqizhixin.com/graph/technologies/64d4c374-6061-46cc-8d29-d0a582934876
(2)Softmax激活函数(归一化指数函数):
 下面解释一下softmax函数。
下面解释一下softmax函数。
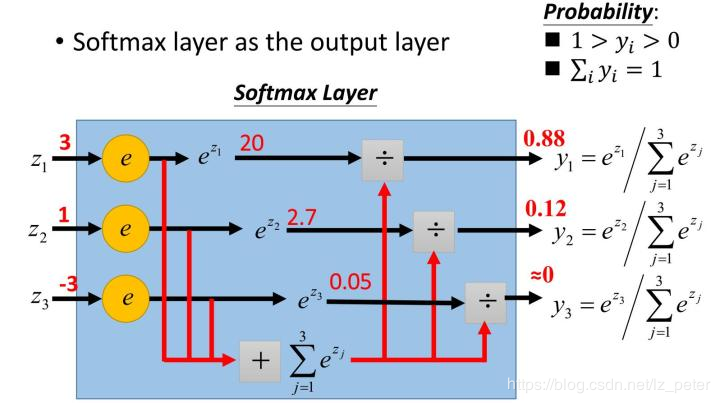
首先,我们知道概率有两个性质:1)预测的概率为非负数;2)各种预测结果概率之和等于1。
而softmax就是将在负无穷到正无穷上的预测结果按照这两步转换为概率的
第一步:将预测结果转化为非负数,利用exp(x)指数函数
这样也就可以使得模型预测的结果一定为正数,保证了概率的非负性
第二步:将各个数据进行一个归一化处理,这是为了使各个不同结果的大小在进行归一化处理后,可以使得概率和为1.
归一化的方法为:先将各个经过第一部处理的数据进行一个求和,设和为sum,然后再将这些经过第一步的数据分别除以sum得到它们相应的概率,这样就可以保证这些所求的概率对应和相加为1啦。
举个栗子:
(3)问:在行人重识别里面引入ID信息不足以增强泛化的一个能力,这时添加行人其他的属性标签进行训练则能提高泛化能力。可是这个不会引起过拟合的问题吗?如果不会(肯定不会),那么为什么在ReID中引入多的属性能增强泛化能力,而在房价预测中添加多的属性多的数据进行训练反而会造成过拟合的后果呢?还是说,在ReID中也使用了dropout的方法呢?不急不急,往后看你会发现总的损失值是通过LAtt 与 LID构成的,用这种方法去解决了过拟合的一个问题。这个有没有点像正则化呢?这个问题需要思考QwQ。
(4)Resnet(华人的骄傲!): 这个的出现解决了梯度弥散或梯度爆炸,以及加入正则化方法后的退化问题。我不知道如何解释清楚残差,怕带偏大家,所以找了两篇我觉得讲的最详细的文章,链接如下:https://blog.csdn.net/lanran2/article/details/79057994
https://blog.csdn.net/mao_feng/article/details/52734438
(5)问:在验证损失中我们注意到在验证子网络和分类子网络都进行了dropout,那么它们是keep什么的prob呢?以及为什么在这里需要用到dropout,而在结合ID损失和属性网络却是使用了FC层?答案可能会出现在下一篇随笔emm。
今天白天课外事情有点多,晚上抓紧学了一会3.1,趁明天没什么事多学一点伐,大家交流起来呀T uT