grep命令
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行。
模式::由正则表达式字符及文本字符所编写的过滤条件
语法:grep [OPTIONS] PATTERN [FILE...]
常用选项:
--color=auto #对匹配到的文本着色显示 ,系统默认将grep别名设置为:grep='grep --color=auto'
-m # #只显示匹配到的#行
-v #显示不被pattern匹配到的行
-i #忽略字符大小写
-n #显示匹配的行号
-c #统计匹配的行数
-o #仅显示匹配到的字符串
-q #静默模式,不输出任何信息
-A #显示匹配到行的后几行
-B #显示匹配到行的前几行
-C #显示匹配到的行的前后几行
-e #实现多个选项间的逻辑or关系
-w #匹配整个单词
-E #使用ERE
-F #相当于fgrep,不支持正则表达式
-f #file 根据模式文件处理
正则表达式
REGEXP:由一类特殊字符及文本字符所编写的模式, 其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
分为两大类,基本的正则表达式和扩展的正则表达式,二者元字符的区别如下:
1、基本正则表达式元字符
^ #如果在[]外则表示以某个字符开头,如果在[]内,则表示除某些字符以外
$ #表示以某个字符结尾
. #表示匹配任意一个字符
* #表示匹配前面字符任意次
[] #表示匹配括号内的多个字符中的任意一个
.* #表示匹配所有
[^] #表示匹配除括号内以外的所有字符
^$ #表示匹配空行信息
\ #将含有特殊含义的字符转义为原字符的含义
2、扩展的正则表达式
+ #表示前面字符出现一次或一次以上
? #表示前面字符出现0次或一次以上
| #表示或者的关系,匹配多个信息
() #匹配一个整体信息,可以进行后项引用
{} #定义前面的字符出现的次数
除此之外正则表达式也支持下面的元字符:
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
一、grep常用选项
举例1:grep查找root关键字,且显示匹配到的第一行
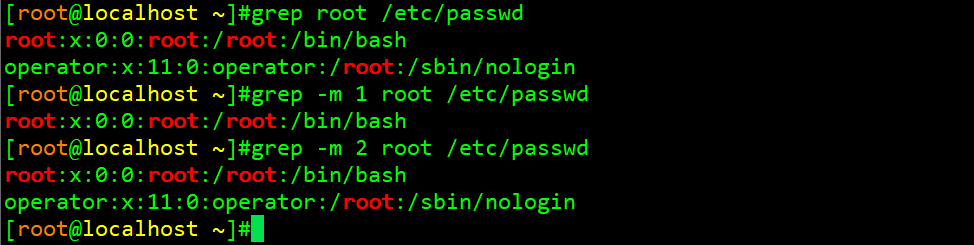
观察以上三条命令的区别,不加-m选项,则默认显示匹配到的所有的行,加了-m选项则只显示-m指定的行数
举例2:显示文档中除shenzhen以外的所有的行
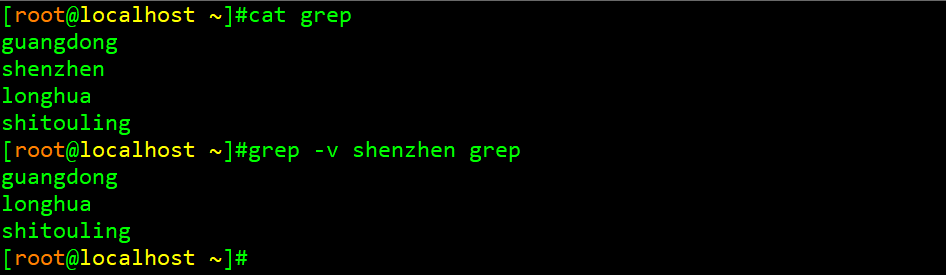
通过以上结果可知,当加上-v选项后,shenzhen所在的那行不再被显示
举例3:不区分大小写查找文档中的shenzhen字符

当加上-i选项后,grep查找时,不区分关键字的大小写
举例4:查找shenzhen字符并显示出字符在文档中的行数

加上-n选项后,会在关键词所在行的行首显示出关键词在文档中的行数
举例5:统计文档中含有shenzhen字符的所有行的数量

加上-c选项后,会统计包含shenzhen字符的行数
举例6:仅显示匹配到的字符

加上-o选项不会显示所匹配到的行,仅显示匹配到的字符
举例7:静默显示,即不输出任何信息

在查询root字符时,不会 输出任何结果,但是会有执行结果
举例8:显示匹配到的行及其后面那一行

加上-A(after)选项,并指定行数为1,则显示的结果为匹配到的行及其后面哪一行
举例9:显示匹配到的行及其前面哪一行

使用-B(before)选项,并指定行数为1,则显示匹配到的行及其前一行
举例10:显示匹配到的行及其前后1行

使用-C选项并指明其行数为1,则显示其匹配到的行以及前后各一行
举例11:匹配多个选项

使用-e选项能实现匹配shenzhen或者longhua的字符的行,并显示到屏幕
举例12:精确匹配到某个单词
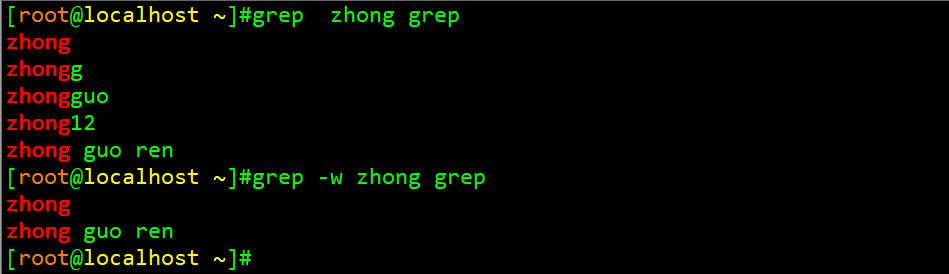
不加-w选项,grep默认会显示出所有包含字符的行,加上-w则表示显示匹配到这个单词的行
举例13:通过扩展的正则匹配
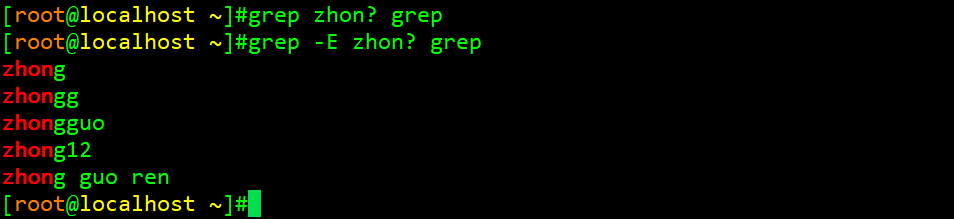
由于?只支持扩展的正则表达式,所以需要在前面加上-E选项才能匹配到关键字符
二、grep位置锚定用法:
常用的表达式:
^ #行首锚定,用于模式的最左侧
$ #行尾锚定,用于模式的最右侧
^<pattern>$ #用于模式匹配整行
^$ #匹配空行
^[[:space:]]*$ #匹配空白行
\<或者\b #词首锚定,用于单词模式的最左侧
\>或者\b #词尾锚定,用于单词模式的最右侧
\<pattern\> #匹配整个单词
举例:查找/etc/passwd中以root开头的行

在查找的字符前加^,只显示以该字符开头的行
举例2:查找/etc/passwd中以nologin结尾的行

在要匹配的字符后面加$,则grep会查找出以该字符结尾的所有行
举例3:查找出文档内容中以大写Z开头,并以520结尾的行
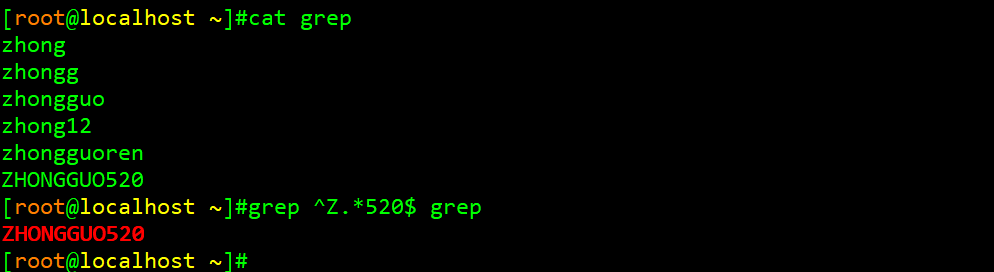
举例4:查找出文档中的空行

^$以这两个字符作为关键字符去匹配,意味着此行内没有任何内容,即空行
举例5:找出文档中空白行

从上图可知,^$匹配不了空白行,^[[:space:]]*$的含义为,以空白行开头且中间有任意个空白字符的行
举例6:查找文档中re在词尾的行

此处需要注意的是,用引号将模式给引起来,否则不生效
三、grep匹配次数
\{n\} #前面的字符重复n次
\{n,\} #前面的字符重复n次以上
\{m,n\} #前面的字符重复m次以上n次以下
举例1:匹配字符r后面的o出现3次的行

注意观察,标红的字符为匹配到的字符,当连续出现3个o则被匹配
举例2:匹配字符r后面的o出现最少3次,最多4次的行
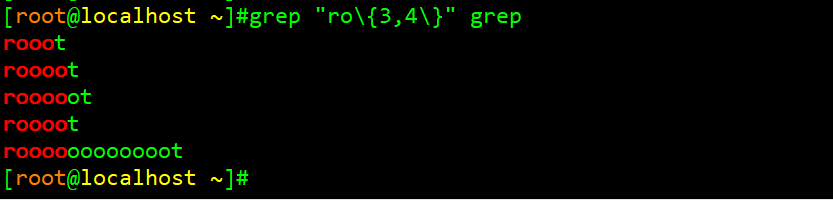
观察此图和上图的区别,可知上图始终只能标识3个o,此图中则标识3个和4个o
举例3:匹配字符r后的o至少3次以上

举例4:匹配字符r后面的o最多出现3次

上图中,匹配o的次数包括0次,1次,2次,3次
四、分组及后向引用
\(\)将一个或多个字符捆绑在一起,当作一个整体处理,分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部变量中吗,这些变量的命名方式为:\1,\2,\3……
举例:利用grep分组匹配字符

以上将root和admin分别放在\(\)中,则将root分成组1,admin分成组2,后面再次出现重复字符时,可以通过\1和、2代替
五、或者
可以用符号\| 来表示匹配中的或者选项
举例:过滤出文档中Cat或者cat
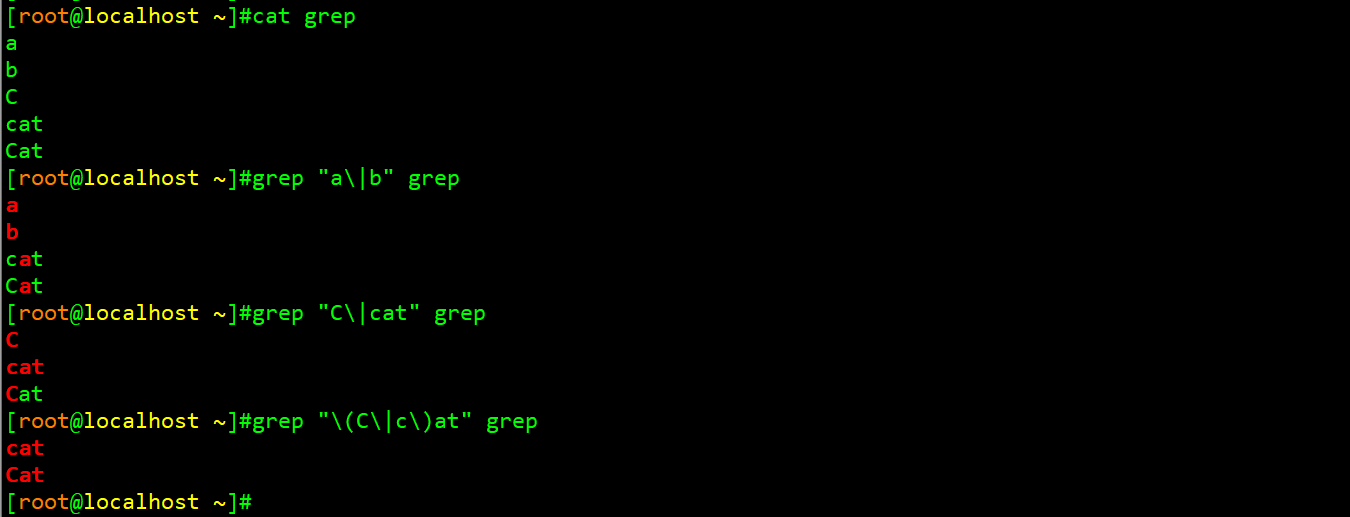
在上图中\|则表示的是逻辑中的或的意思