基本语法
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。
一、选择:|
- | 竖直分隔符表示选择,例如"boy|girl"可以匹配"boy"或者"girl"
二、数量限定:+ ? *
- +表示前面的字符必须出现至少一次(1次或多次),例如,"goo+gle",可以匹配"gooogle","goooogle"等;
- ?表示前面的字符最多出现一次(0次或1次),例如,"colou?r",可以匹配"color"或者"colour";
- *星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,“0*42”可以匹配42、042、0042、00042等。
三、范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体。例如,"gr(a|e)y"等价于"gray|grey",(这里体现了优先级,竖直分隔符用于选择a或者e而不是gra和ey),"(grand)?father"匹配father和grandfather(这里体验了范围,?将圆括号内容作为一个整体匹配)。
四、语法(部分)
正则表达式有多种不同的风格,下面列举一些常用的作为 PCRE 子集的适用于perl和python编程语言及grep或egrep的正则表达式匹配规则:(由于markdown表格解析的问题,下面的竖直分隔符用全角字符代替,实际使用时请换回半角字符)
PCRE(Perl Compatible Regular Expressions中文含义:perl语言兼容正则表达式)是一个用 C 语言编写的正则表达式函数库,由菲利普.海泽(Philip Hazel)编写。PCRE是一个轻量级的函数库,比Boost 之类的正则表达式库小得多。PCRE 十分易用,同时功能也很强大,性能超过了 POSIX 正则表达式库和一些经典的正则表达式库。
五、字符描述
- \ 将下一个字符标记为一个特殊字符、或一个原义字符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\\”匹配“\”而“\(”则匹配“(”。
- ^ 匹配输入字符串的开始位置。
- $ 匹配输入字符串的结束位置。
- {n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
- {n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
- {n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。
- * 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”、“zo”以及“zoo”。*等价于{0,}。
- + 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
- ? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
- ? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。
- . 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“(.|\n)”的模式。
- (pattern) 匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。要匹配圆括号字符,请使用“\(”或“\)”。
- x|y 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。
- [xyz] 字符集合(character class)。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。其中特殊字符仅有反斜线\保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果如果出现在首位则仅作为普通字符。
- [^xyz] 排除型(negate)字符集合。匹配未列出的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。
- [a-z] 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。
- [^a-z] 排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。
六、优先级
优先级为从上到下从左到右,依次降低:
| 运算符 | 说明 |
| \ | 转义符 |
| (), (?:), (?=), [] | 括号和中括号 |
| *、+、?、{n}、{n,}、{n,m} | 限定符 |
| ^、$、\任何元字符 | 定位点和序列 |
| | | 选择 |
grep模式匹配命令
一、 基本操作
grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:
参数 说明
- -E POSIX扩展正则表达式,ERE
- -G POSIX基本正则表达式,BRE
- -P Perl正则表达式,PCRE
在通过grep命令使用正则表达式之前,先介绍一下它的常用参数:
参数 说明
- -b 将二进制文件作为文本来进行匹配
- -c 统计以模式匹配的数目
- -i 忽略大小写
- -n 显示匹配文本所在行的行号
- -v 反选,输出不匹配行的内容
- -r 递归匹配查找
- -A n n为正整数,表示after的意思,除了列出匹配行之外,还列出后面的n行
- -B n n为正整数,表示before的意思,除了列出匹配行之外,还列出前面的n行
- --color=auto 将输出中的匹配项设置为自动颜色显示
使用正则表达式
使用基本正则表达式,BRE
位置
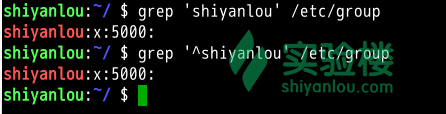
查找/etc/group文件中以"shiyanlou"为开头的行
$ grep 'shiyanlou' /etc/group $ grep '^shiyanlou' /etc/group
数量
# 将匹配以'z'开头以'o'结尾的所有字符串 $ echo 'zero\nzo\nzoo' | grep 'z.*o' # 将匹配以'z'开头以'o'结尾,中间包含一个任意字符的字符串 $ echo 'zero\nzo\nzoo' | grep 'z.o' # 将匹配以'z'开头,以任意多个'o'结尾的字符串 $ echo 'zero\nzo\nzoo' | grep 'zo*' #注意:其中\n为换行符

选择
# grep默认是区分大小写的,这里将匹配所有的小写字母 $ echo '1234\nabcd' | grep '[a-z]' # 将匹配所有的数字 $ echo '1234\nabcd' | grep '[0-9]' # 将匹配所有的数字 $ echo '1234\nabcd' | grep '[[:digit:]]' # 将匹配所有的小写字母 $ echo '1234\nabcd' | grep '[[:lower:]]' # 将匹配所有的大写字母 $ echo '1234\nabcd' | grep '[[:upper:]]' # 将匹配所有的字母和数字,包括0-9,a-z,A-Z $ echo '1234\nabcd' | grep '[[:alnum:]]' # 将匹配所有的字母 $ echo '1234\nabcd' | grep '[[:alpha:]]'
下面包含完整的特殊符号及说明:
特殊符号 说明
- [:alnum:] 代表英文大小写字母及数字,亦即 0-9, A-Z, a-z
- [:alpha:] 代表任何英文大小写字母,亦即 A-Z, a-z
- [:blank:] 代表空白键与 [Tab] 按键两者
- [:cntrl:] 代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等
- [:digit:] 代表数字而已,亦即 0-9
- [:graph:] 除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键
- [:lower:] 代表小写字母,亦即 a-z
- [:print:] 代表任何可以被列印出来的字符
- [:punct:] 代表标点符号 (punctuation symbol),亦即:" ' ? ! ; : # $...
- [:upper:] 代表大写字母,亦即 A-Z
- [:space:] 任何会产生空白的字符,包括空白键, [Tab], CR 等等
- [:xdigit:] 代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节
注意:之所以要使用特殊符号,是因为上面的[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在LANG环境变量的值,zh_CN.UTF-8的话[a-z],即为所有小写字母,其它语系可能是大小写交替的如,"a A b B...z Z",[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
# 排除字符
$ $ echo 'geek\ngood' | grep '[^o]'
注意:当^放到中括号内为排除字符,否则表示行首。
使用扩展正则表达式,ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
数量
# 只匹配"zo" $ echo 'zero\nzo\nzoo' | grep -E 'zo{1}' # 匹配以"zo"开头的所有单词 $ echo 'zero\nzo\nzoo' | grep -E 'zo{1,}'
注意:推荐掌握{n,m}即可,+,?,*,这几个不太直观,且容易弄混淆。
选择
# 匹配"www.shiyanlou.com"和"www.google.com" $ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -E 'www\.(shiyanlou|google)\.com' # 或者匹配不包含"baidu"的内容 $ echo 'www.shiyanlou.com\nwww.baidu.com\nwww.google.com' | grep -Ev 'www\.baidu\.com'
注意:因为.号有特殊含义,所以需要转义。