关于维修
随着时间的流逝,由于数据库的分布式性质,副本中的数据可能会与其他副本不一致。节点修复可纠正不一致之处,以使所有节点具有相同且最新的数据。对于Apache Cassandra™(DDAC) 群集的每个DataStax分发,节点修复都是定期维护的重要组成部分。使用数据库设置或各种工具来配置每种修复类型。
Hinted Handoff (提示移交)(在写入时进行修复)
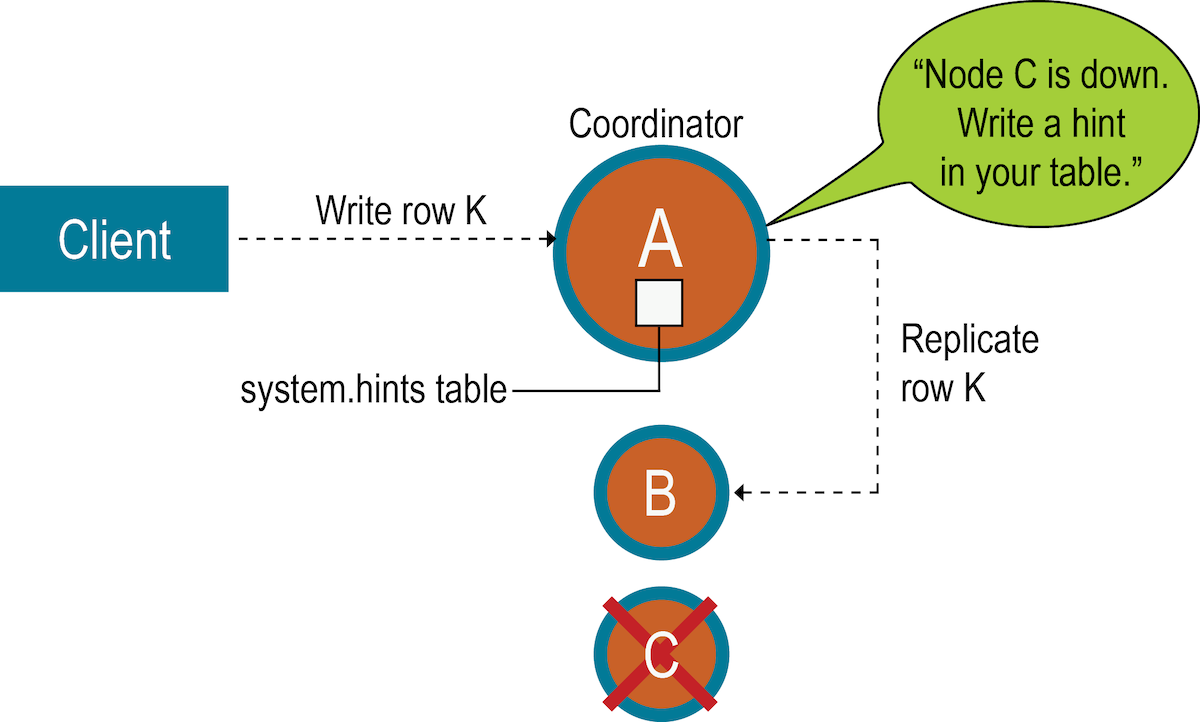
有时,节点在写入数据时变得无响应。无法响应的原因包括硬件问题,网络问题或出现长时间垃圾回收(GC)暂停的过载节点。通过设计,提示切换从本质上允许Apache Cassandra™(DDAC)的DataStax Distribution继续执行相同数量的写操作,即使集群以减少的容量运行时也是如此。
如果故障检测器将节点标记为已关闭并且在cassandra.yaml文件中启用了 提示切换,则协调器节点会在一段时间内存储丢失的写入。提示包含以下信息:
- 发生故障的节点的目标ID
- 提示ID,它是数据的时间UUID
- 标识Cassandra 版本的消息ID
- 数据本身为斑点
提示每十秒钟刷新一次到磁盘上,从而减少了提示的陈旧性。当八卦发现节点重新联机时,协调器将重播每个剩余的提示,以将数据写入新返回的节点,然后删除提示文件。如果节点关闭的时间超过max_hint_window_in_ms参数中配置的值(默认为三个小时),则协调器将停止编写新提示。
协调器还每隔十分钟检查一次提示,这些提示对应于在中断期间过短而导致故障检测程序无法通过八卦注意到的超时超时的写入。如果副本节点过载或不可用,并且故障检测器尚未将该节点标记为已关闭,则在write_request_timeout_in_ms(默认为2秒)触发的超时后,对该节点的大多数或所有写入都会失败。协调器返回TimeOutException错误,并且写入将失败。但是,将存储提示。如果多个节点同时经历短暂中断,则协调器上可能会累积大量内存压力。协调器跟踪它当前正在编写多少个提示。如果提示的数量增加太多,则协调器将拒绝写入并抛出提示。OverloadedException 错误。
该一致性水平写入请求的数量会影响是否写入提示,并且写入请求随后会失败。如果群集由复制因子为1的两个节点A和B组成,则每一行仅存储在一个节点上。假设节点A是协调器,但是在一致性级别为ONE的行K写入到节点K之前发生故障。在这种情况下,无法满足指定的一致性级别,并且由于节点A是协调者,因此它无法存储提示。节点B无法写入数据,因为它尚未作为协调者接收到数据,并且尚未存储提示。如果无法满足客户端指定的一致性级别,则协调器将检查已启动且不会尝试写入提示的副本数。在这种情况下,协调器将返回一个UnavailableException错误。写入请求失败,并且提示未写入。
通常,建议在群集中具有足够的节点,并使用足够多的复制因子来避免写入请求失败。例如,考虑一个由三个节点A,B和C组成的群集,其复制因子为3。当将行K写入协调器(在这种情况下为节点A)时,即使节点C发生故障,也可以满足ONE或QUORUM的一致性级别。为什么?节点A和B都将接收数据,因此符合一致性级别要求。将为节点C存储提示,并在节点C出现时写入提示。同时,协调器可以确认写入成功。
一致性级别ANY
对于希望当所有正常副本都关闭并且无法满足一致性级别ONE时Cassandra接受写入的应用程序,数据库提供了一致性级别ANY。在适当的副本目标可用并收到提示重播之后,ANY保证写入是持久且可读的。
死亡的节点可能已经存储了未传递的提示,因为任何节点都可以是协调者。长时间中断后,死节点上的数据将过时。如果节点已关闭很长时间,请运行手动修复。
- 丢失必要的历史数据以准确告诉集群的其余部分缺少哪些数据。
- 失败节点协调的请求丢失了尚未提示的提示。
通过停用节点或使用nodetool removenode命令从集群中删除节点时,数据库会自动删除针对不再存在的节点的提示,并删除已删除表的提示。
有关提示存储的更多说明,请参阅3.0版Cassandra的新功能:改进的提示存储和交付博客文章。有关基本信息,请参阅现代提示的切换博客文章。
Read Repair (读修复)(读取数据时进行修复)
ONE
或者
LOCAL_ONE
,
Apache的卡桑德拉DataStax分布™(DDAC)开始读修复。此类读取修复在前台运行,并阻止应用程序操作,直到修复过程完成。
ONE或 LOCAL_ONE不阻止应用程序操作的读取查询,因为必须存在数据不匹配才能触发读取修复,并且由于仅查询一个副本,因此不会进行比较,因此不会发生不匹配。
- 该协调器节点请求数据和其他一个副本的消化他们的数据。
- 如果从副本返回给协调器的数据不匹配,则从查询中涉及的所有副本中请求读取(由一致性级别决定),然后合并结果。
- 如果单个副本没有每列的所有最新数据,则通过混合和匹配来自不同副本的列来组合一条新记录。
- 确定最新版本后,记录将仅写回请求中涉及的副本。
LOCAL_QUORUM
具有三倍复制因子的读取,将查询两个副本,因此仅修复这两个副本。
gc_grace_seconds过期之前尚未传播到所有副本节点 ,则该数据可能会继续作为实时数据返回。
对于5.1.12之前的DDAC版本,还可以配置群集范围和本地数据中心的非阻塞后台修复,并由参数控制 dclocal_read_repair_chance,read_repair_chance 如table_options中所述。
- 如果表的读取修复机会属性不为零,则在每次查询期间, Cassandra都会在
0.0和之间生成一个随机数1.0。 - 如果该随机数小于或等于
read_repair_chance,则启动非阻塞全局读取修复。 - 如果不是,则Cassandra进行测试以查看随机数是否小于或等于
dc_local_read_repair_chance,如果是,则仅在本地DC中执行无阻塞读取修复。
read_repair_chance,首先对其进行评估。如果 read_repair_chance大于或等于给 dclocal_read_repair_chance定表,则永远不会进行本地DC读取修复。
由于检查DTCS压缩中使用的时间戳的方法,因此无法对使用DateTieredCompactionStrategy(DTCS)-已过时的表执行读修复。如果表使用 DateTieredCompactionStrategy,则设置 read_repair_chance为零。对于其他压缩策略, read_repair_chance通常将其设置为0.2。
Anti-entropy repair (逆熵)
nodetool repair为您的定期维护的一部分。
逆熵节点修复对于Apache Cassandra™(DDAC)群集的每个DataStax分发都很重要。频繁的数据删除和关闭的节点是导致数据不一致的常见原因。将逆熵修复用于日常维护,以及在群集需要通过运行nodetool修复进行修复时。
- 逆熵修复如何工作?
- 顺序维修与并行维修
- 为每个副本构建一个Merkle树
- 比较Merkle树以发现差异
Cassandra Merkle树的叶子是行值的哈希。树中较高的每个父节点是其各自子节点的哈希。由于Merkle树中的较高节点表示数据在树的更下方,因此Casandra可以独立检查每个分支,而无需协调器节点下载整个数据集。为了进行反熵修复,Cassandra使用了深度为15(2 15 = 32K叶节点)的紧凑树版本。例如,对于包含一百万个分区和一个损坏的分区的节点,流式传输大约30个分区,这是落在树的每个叶子中的数量。Cassandra与较小的Merkle树配合使用,因为它们需要较少的存储内存,并且在比较过程中可以更快地传输到其他节点。

在启动节点从参与的对等节点接收到Merkle树之后,启动节点将每棵树与其他所有树进行比较。如果检测到差异,则不同的节点将交换冲突范围的数据,并将新数据写入SSTables。比较从Merkle树的顶部节点开始。如果未检测到差异,则无需修复数据。如果检测到差异,则处理进行到左子节点并进行比较,然后比较右子节点。当发现一个节点不同时,与该节点有关的范围存在不一致的数据。与该Merkle树节点下的叶子对应的所有数据将被新数据替换。对于任何给定的副本集,Cassandra 一次仅对一个副本执行验证压缩。
Merkle树的构建需要大量资源,从而增加了磁盘I / O并占用了内存。此处讨论的某些选项有助于减轻对群集性能的影响。
nodetool repair如果未指定节点,请在指定的节点或所有节点上运行命令。启动修复的节点成为操作的协调器节点。为了构建Merkle树,协调器节点确定具有匹配数据范围的对等节点。在对等节点上触发主压缩或验证压缩。验证压缩会读取并为存储的列族中的每一行生成一个哈希,然后将结果添加到Merkle树中,然后将该树返回到发起节点。默克尔树使用数据的哈希值,因为通常,哈希值将小于数据本身。将在卡桑德拉修复博客中详细讨论了这个过程。
顺序修复在另一个节点上执行操作。并行修复可同时修复具有相同副本数据的所有节点。数据中心并行(-dc-par)通过在所有数据中心中同时运行顺序修复来组合顺序和并行。每个数据中心中的一个节点将运行修复,直到修复完成。
顺序修复为每个副本拍摄快照。快照是到现有SSTables的硬链接。它们是不可变的,几乎不需要磁盘空间。在修复过程中,快照处于活动状态,然后数据库将其删除。当协调器节点在Merkle树中发现差异时,协调器节点将根据快照进行必要的修复。例如,对于复制因子为3(RF = 3)且副本A,B和C的键空间中的表,修复命令立即获取每个副本的快照,然后从快照中依次修复每个副本(使用快照) A修复副本B,然后快照A修复副本C,然后快照B修复副本C)。
并行修复可同时为所有数据中心中的所有节点构造Merkle表。它可以同时在节点A,B和C上工作。在并行修复期间,动态窃听将使用未经修复的快照中的副本来处理对该表的查询。使用并行修复可以快速完成修复,也可以在出现操作性停机时允许在修复期间完全消耗资源的情况下使用修复。
与顺序修复不同,数据中心并行修复可同时为所有数据中心构造Merkle表。因此,不需要(或生成)快照。