介绍
Row
在Cassandra里面, name/value的对就是columns;每个拥有一系列columns的实体叫做rows;row的 unique identifier叫做row key或者primary key。
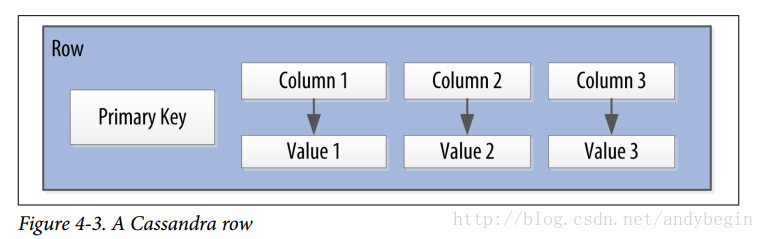
在Cassandra中,如果有些column没有value,则不会被保存下来。
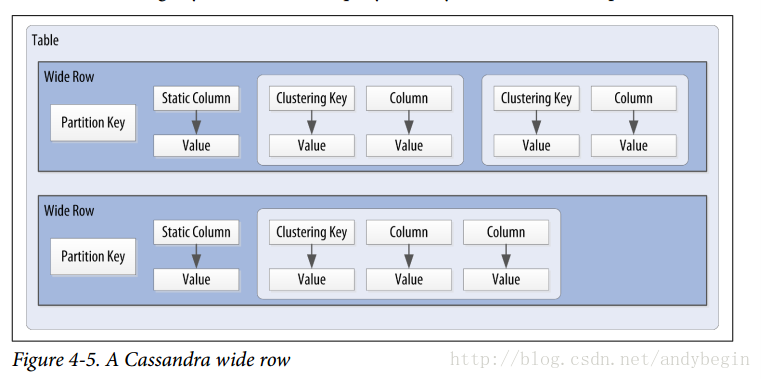
Wide row
一个wide row表示这个row包含了许多columns。Cassandra使用一个特殊的主键叫做composite key或者compound key来代表这个wide rows,它也可以叫做partitions。composite key是由partition key和一些额外的clustering columns构成。
Partition key用来表明node在哪个rows上保存。Clustering columns用来控制数据如何在partition里面存储。Static column是一种不属于primary key但是却被每个row都分享使用的结构。
总结
- column:代表 name/value 对
- row:一个包含多个columns的容器,有一个primary key引用
- table:一个包含多个rows的容器
- keyspace:一个包含多个tables的容器
- cluster:跨越一个或多个节点的keyspaces容器
cluster
因为Cassandra的设计就是分布式设计,部署在多个机器上运行。所以在最外面的结构是cluster,有时候也叫作ring。为什么叫做ring呢,那是因为Cassandra的设计是类似于ring的形态把数据分配给nodes。
keyspaces
Cluster是keyspace的容器,keyspace是数据模型的最外层。类似于关系型数据库,数据库是数据模型的最外层;在Cassandra里面,keyspace就是data model的最外层。
tables
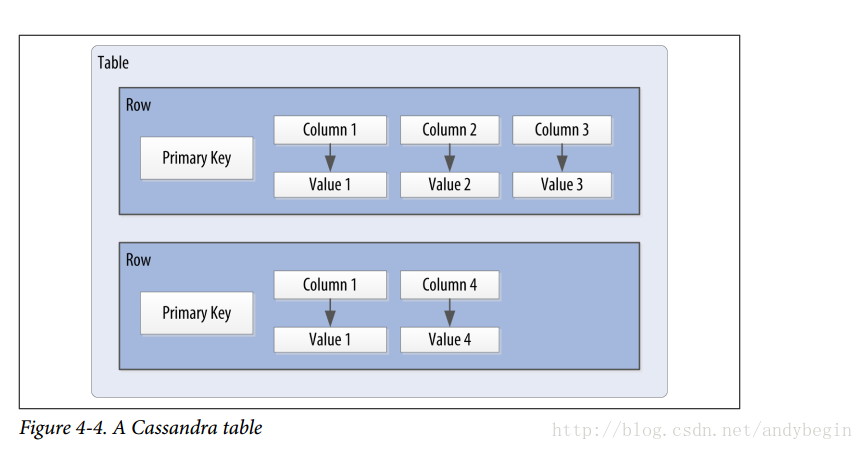
Table是一系列有序rows的容器,rows又是一系列有序columns的容器。这个排序是由columns决定的。在写数据进入Cassandra的table,需要指定一个或多个columns的value。这些values的集合叫做row。至少其中一个value必须是primary key的。
正如前面说的,并不需要对每个column都插入数据,所以现在我们把user表做个修改。
cqlsh:my_keyspace> ALTER TABLE user ADD title text;
cqlsh:my_keyspace> DESCRIBE TABLE user ;现在我们插入数据进去:
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name, title) VALUES ('Bill', 'Nguyen', 'Mr.');
cqlsh:my_keyspace> INSERT INTO user (first_name, last_name) VALUES('Mary', 'Rodriguez');
cqlsh:my_keyspace> select * FROM user ;