1.概述:
下面是我画的一张思维导图,作为概述:

2.生成http请求:
url有不同的种类,例如常见的http,ftp,mailto,不同的协议标识着他们用于不同的功能,也可以把他们看作一种url功能上的分类.不同的分类有遵守着各自的规则.也就是我们所说的协议.
2-1:那浏览器是如何解析url地址的:
url地址是一个字符串,解析的时候会根据特定的字符去拆分,其中"//" 作为一个分隔标识,他前面的标识协议,后面是服务器的名称,服务器后面的 "/",标识文件路径.有的路径在服务上不存在,如果nginx会出找相应的应用路由匹配,如果存在文件路径,会被当做文件路径使用.
2-2: http的基本思路:
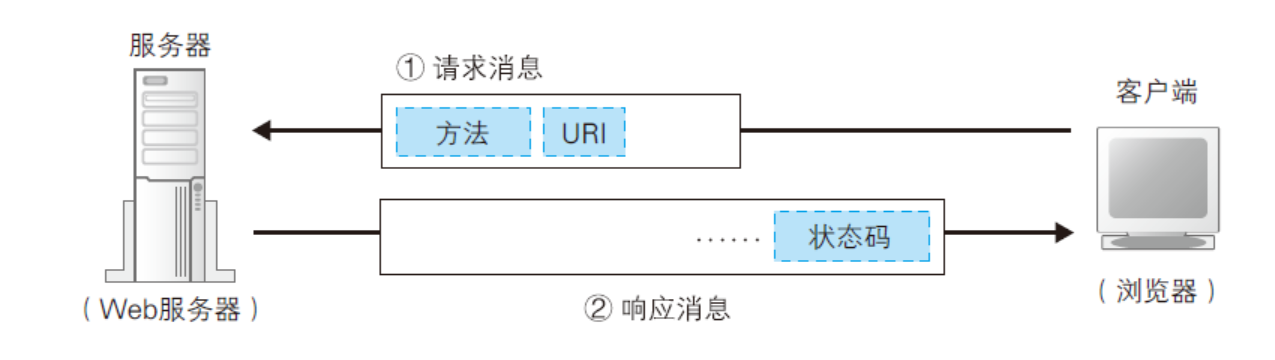
图中的1:请求信息包括两部分: 对什么,进行什么操作.
其中"对什么"指的是内容,指的是资源路径,成为URI(uniform resource identifier).如具体的某一个html,一张图片 xxx.com/abc.html, xxx.com/abc.jpg
也可以把uri理解为邮件上的地址,完成一次通信,不是只有地址就可以的,还需要邮差去送,走着送还是骑车,还是火车,这就是请求的方式,也就是"进行什么操作"
常见的请求方式:GET,POST.OPTION HEAD,PUT,DELETE等.客户端在发送数据前会先发送头字段.在发送数据.
图中2,web服务器接收到消息后,根据要求作出响应,并将响应结果放到响应信息里,其中有一个状态码用于标识成功还是失败.
2-3:生成http请求:
根据uri资源的路径和请求的方式根据协议规定生成请求信息:
第一行: 请求行.告诉服务他该进行什么样的操作.