上一章简单介绍了RabbitMQ的安装和一些参数及简单的传送信息,今天我们介绍一些其他的参数。
当创建了队列和发送的消息,如果没有被消费者消费的时候,重启了RabbitMQ服务,队列和消息都会丢失了。
pika版本1.1.0
一、RabbitMQ持久化
MQ默认建立的是临时 queue 和 exchange,如果不声明持久化,一旦 rabbitmq 挂掉,queue、exchange 将会全部丢失。所以我们一般在创建 queue 或者 exchange 的时候会声明 持久化。
1.queue 声明持久化
# 声明消息队列,消息将在这个队列传递,如不存在,则创建。durable = True 代表消息队列持久化存储,False 非持久化存储 result = channel.queue_declare(queue = 'python-test',durable = True)
2.exchange 声明持久化
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建.durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test', durable = True)
注意:如果已存在一个非持久化的 queue 或 exchange ,执行上述代码会报错,因为当前状态不能更改 queue 或 exchange 存储属性,需要删除重建。如果 queue 和 exchange 中一个声明了持久化,另一个没有声明持久化,则不允许绑定。队列必须在第一次声明的时候,就必须要持久化。
3.消息持久化(******)
虽然exchange和queue都声明了持久化,但是消息只存在内存里,rabbitmq重启后,内存里面的东西还是会丢失。所以必须声明消息也是持久化,从内存转存到硬盘。
# 向队列插入数值 routing_key是队列名。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化 channel.basic_publish(exchange = '',routing_key = 'python-test',body = message, properties=pika.BasicProperties(delivery_mode = 2))
4.Message acknowledgment消息不丢失(******)
消费者(consumer)调用callback函数时,会存在处理消息失败的风险,如果处理失败,则消息丢失。但是也可以选择消费者处理失败时,将消息回退给 rabbitmq ,重新再被消费者消费,这个时候需要设置确认标识。
channel.basic_consume('python-test',callback # no_ack 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉 auto_ack = False)
二、消息的能者多劳
服务器的性能大小不一,有的服务器处理的快,有的服务器处理的慢,因此默认的轮询方式不能够满足我们的需求,我们要的是 能者多劳,
最大限度的发挥我们机器的性能. 为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
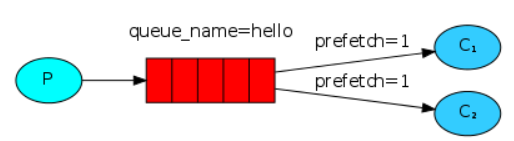
channel.basic_qos(prefetch_count=1) channel.basic_consume(callback,queue='task_queue')
三、RabbitMQ发布与订阅
我们看到生产者将消息投递到Queue中,实际上这在RabbitMQ中这种事情永远都不会发生。实际的情况是,生产者将消息发送到Exchange(交换器),由Exchange将消息路由到一个或多个Queue中(或者丢弃)。所以rabbitmq的发布与订阅要借助交换机(Exchange)的原理实现
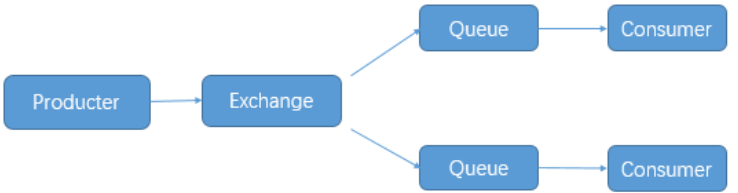
在此之前我们需要先了解一些参数:
routing key
生产者在将消息发送给Exchange的时候,一般会指定一个routing key(指定连接队列名),来指定这个消息的路由规则,而这个routing key需要与Exchange Type及
binding key联合使用才能最终生效。在Exchange Type与binding key固定的情况下(在正常使用时一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,
通过指定routing key来决定消息流向哪里。RabbitMQ为routing key设定的长度限制为255 bytes
Binding
RabbitMQ中通过Binding将Exchange与Queue关联起来,这样RabbitMQ就知道如何正确地将消息路由到指定的Queue了。
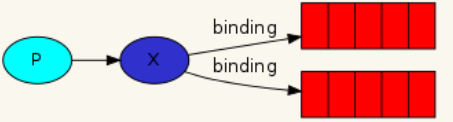
Binding key
在绑定(Binding)Exchange与Queue的同时,一般会指定一个binding key;消费者将消息发送给Exchange时,一般会指定一个routing key;
当binding key与routing key相匹配时,消息将会被路由到对应的Queue中。
在绑定多个Queue到同一个Exchange的时候,这些Binding允许使用相同的binding key。
binding key 并不是在所有情况下都生效,它依赖于Exchange Type,比如fanout类型的Exchange就会无视binding key,而是将消息路由到所有绑定到该Exchange的Queue。
Exchange Types一共有四种工作模式:fanout,direct,topic,headers
现在我们一般都不用headers,所以我们只分析前三种
模式一:fanout
这种模式下,传递到exchange的消息将会转发到所有与其绑定的queue上。fanout类型转发消息是最快的。
注意以下几点:
- 不需要指定 routing_key ,即使指定了也是无效。
- 需要提前将 exchange 和 queue 绑定,一个 exchange 可以绑定多个 queue,一个queue可以绑定多个exchange。
- 需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。

发布者代码:
import pika import json credentials = pika.PlainCredentials('guest', 'guest') # mq用户名和密码 connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost',port = 5672,credentials = credentials))
#创建链接 channel=connection.channel() # 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout') for i in range(10): message=json.dumps({'OrderId':"1000%s"%i}) # 向队列插入数值 exchange指定队列名。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化。routing_key 不需要配置 channel.basic_publish(exchange = 'python-test',routing_key = '',body = message, properties=pika.BasicProperties(delivery_mode = 2)) print(message) connection.close()
订阅者代码:
import pika credentials = pika.PlainCredentials('guest', 'guest') connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost',port = 5672,credentials = credentials)) channel = connection.channel() # 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除 result = channel.queue_declare('',exclusive=True) # 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout') # 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去,queue临时队列 channel.queue_bind(exchange = 'python-test',queue = result.method.queue) # 定义一个回调函数来处理消息队列中的消息,这里是打印出来 def callback(ch, method, properties, body): ch.basic_ack(delivery_tag = method.delivery_tag) print(body.decode()) channel.basic_consume(result.method.queue,callback,# 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉 auto_ack = False) channel.start_consuming()
模式二:direct
这种工作模式的原理是 消息发送至 exchange,exchange 根据 路由键(routing_key)转发到相对应的 queue 上。
- 可以使用默认 exchange =' ' ,也可以自定义 exchange
- 这种模式下不需要将 exchange 和 任何进行绑定,当然绑定也是可以的。可以将 exchange 和 queue ,routing_key 和 queue 进行绑定
- 传递或接受消息时 需要 指定 routing_key
- 需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。
发布者代码:
import pika import json credentials = pika.PlainCredentials('guest', 'guest') # mq用户名和密码 connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost',port = 5672,credentials = credentials)) channel=connection.channel() # 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='direct') for i in range(10): message=json.dumps({'OrderId':"1000%s"%i}) # 指定 routing_key。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化 channel.basic_publish(exchange = 'python-test',routing_key = 'OrderId',body = message, properties=pika.BasicProperties(delivery_mode = 2)) print(message) connection.close()
订阅者代码:
import pika credentials = pika.PlainCredentials('guest', 'guest') connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost',port = 5672,credentials = credentials)) channel = connection.channel() # 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除 result = channel.queue_declare('',exclusive=True) # 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='direct') # 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去 channel.queue_bind(exchange = 'python-test',queue = result.method.queue,routing_key='OrderId') # 定义一个回调函数来处理消息队列中的消息,这里是打印出来 def callback(ch, method, properties, body): ch.basic_ack(delivery_tag = method.delivery_tag) print(body.decode()) #channel.basic_qos(prefetch_count=1) # 告诉rabbitmq,用callback来接受消息 channel.basic_consume(result.method.queue,callback, # 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉 auto_ack = False) channel.start_consuming()
模式三:topicd
这种模式和第二种模式差不多,exchange 也是通过 路由键 routing_key 来转发消息到指定的 queue 。 不同点是 routing_key 使用正则表达式支持模糊匹配,但匹配规则又与常规的正则表达式不同,比如‘’#‘’是匹配全部,“*”是匹配一个词。
举例:routing_key =“#orderid#”,意思是将消息转发至所有 routing_key 包含 “orderid” 字符的队列中。代码和模式二 类似,就不贴出来了。
发布者代码:
import pika import sys credentials = pika.PlainCredentials('用户名', '密码') parameters = pika.ConnectionParameters(host='localhost',credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() #队列连接通道 channel.exchange_declare(exchange='mytopic',type='topic') log_level = sys.argv[1] if len(sys.argv) > 1 else 'all.info' message = ' '.join(sys.argv[1:]) or "all.info: Hello World!" channel.basic_publish(exchange='topic_log', routing_key=log_level, body=message) print(" [x] Sent %r" % message) connection.close()
订阅者代码:
import pika,sys credentials = pika.PlainCredentials('用户名', '密码') parameters = pika.ConnectionParameters(host='localhost',credentials=credentials) connection = pika.BlockingConnection(parameters) channel = connection.channel() queue_obj = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 queue_name = queue_obj.method.queue log_levels = sys.argv[1:] # info warning errr if not log_levels: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for level in log_levels: channel.queue_bind(exchange='topic_log', queue=queue_name, routing_key=level) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback,queue=queue_name, no_ack=True) channel.start_consuming()
RabbitMQ服务器的管理
./sbin/rabbitmq-server -detached # 后台启动 ./sbin/rabbitmqctl status # 查看状态 ./sbin/rabbitmqctl stop # 关闭 ./sbin/rabbitmqctl list_queues # 查看queue