作业代码:http://pages.cs.wisc.edu/~remzi/OSTEP/
http://pages.cs.wisc.edu/~remzi/OSTEP/Homework/homework.html
项目:https://github.com/remzi-arpacidusseau/ostep-projects
reading the famous papers of our field is certainly one of the best ways to learn.
the real point of education is to get you interested in something, to learn something more about the subject matter on your own and not just what you have to digest to get a good grade in some class.
We created these notes to spark your interest in operating systems, to read more about the topic on your own, to talk to your professor about all the exciting research that is going on in the field, and even to get involved with that research. It is a great field(!), full of exciting and wonderful ideas that have shaped computing history in profound and important ways. And while we understand this fire won’t light for all of you, we hope it does for many, or even a few. Because once that fire is lit, well, that is when you truly become capable of doing something great. And thus the real point of the educational process: to go forth, to study many new and fascinating topics, to learn, to mature, and most importantly, to find something that lights a fire for you.
文件系统:
The file system is the part of the OS in charge of managing persistent data
For example, when writing a C program, you might first use an editor (e.g., Emacs7 ) to create and edit the C file (emacs -nw main.c). Once done, you might use the compiler to turn the source code into an executable (e.g., gcc -o main main.c). When you’re finished, you might run the new executable (e.g., ./main). Thus, you can see how files are shared across different processes. First, Emacs creates a file that serves as input to the compiler; the compiler uses that input file to create a new executable file (in many steps – take a compiler course for details); finally, the new executable is then run.
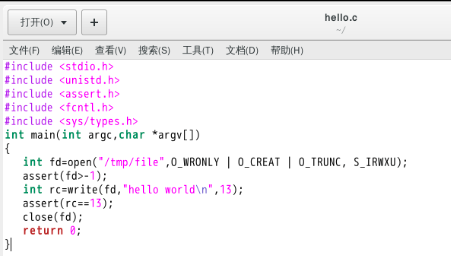
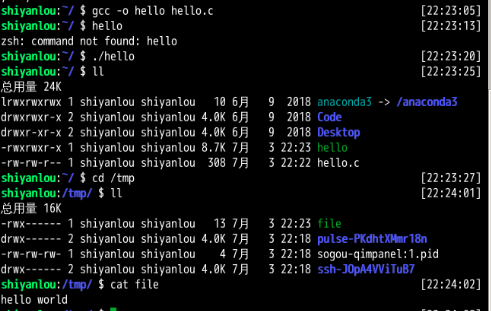
You might be wondering what the OS does in order to actually write to disk.
操作系统把设备驱动程序抽象了。
The file system has to do a fair bit of work: first figuring out where on disk this new data will reside, and then keeping track of it in various structures the file system maintains. Doing so requires issuing I/O requests to the underlying storage device, to either read existing structures or update (write) them. As anyone who has written a device driver8 knows, getting a device to do something on your behalf is an intricate and detailed process. It requires a deep knowledge of the low-level device interface and its exact semantics. Fortunately, the OS provides a standard and simple way to access devices through its system calls. Thus, the OS is sometimes seen as a standard library
文件系统采用许多不同的数据结构和访问方法,从简单列表到复杂的btree
file systems employ many different data structures and access methods, from simple lists to complex btrees
我们的目标:
One of the most basic goals is to build up some abstractions in order to make the system convenient and easy to use。(Abstractions are fundamental to everything we do in computer science)
another way to say this is our goal is to minimize the overheads of the OS.
These overheads arise in a number of forms: extra time (more instructions) and extra space (in memory or on disk).
有点明白进程为啥这么重要了。
程序--->进程的过程:
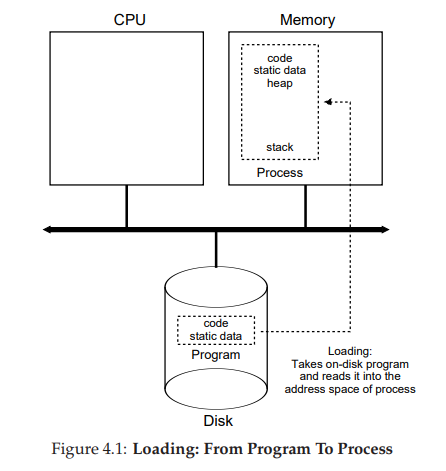
To truly understand how lazy loading of pieces of code and data works, you’ll have to understand more about the machinery of paging and swapping, topics we’ll cover in the future when we discuss the virtualization of memory. For now, just remember that before running anything, the OS clearly must do some work to get the important program bits from disk into memory。
当程序变为进程前,OS会申请内存(为了堆栈)(
操作系统也可能使用参数初始化堆栈;
具体来说,它会填写参数
main()函数,即argc和argv数组)
Once the code and static data are loaded into memory, there are a few other things the OS needs to do before running the process. Some memory must be allocated for the program’s run-time stack (or just stack). As you should likely already know, C programs use the stack for local variables, function parameters, and return addresses; the OS allocates this memory and gives it to the process. The OS will also likely initialize the stack with arguments; specifically, it will fill in the parameters to the main() function, i.e., argc and the argv array。
OS可能还会申请堆(Heap)
The OS may also create some initial memory for the program’s heap. In C programs, the heap is used for explicitly requested dynamicallyallocated data;
具体的实现:programs request such space by calling malloc() and free it explicitly by calling free(). The heap is needed for data structures such as linked lists, hash tables, trees, and other interesting data structures. The heap will be small at first; as the program runs, and requests more memory via the malloc() library API, the OS may get involved and allocate more memory to the process to help satisfy such calls.
, in UNIX systems, each process by default has three open file descriptors, for standard input, output, and error
PCB的内容:

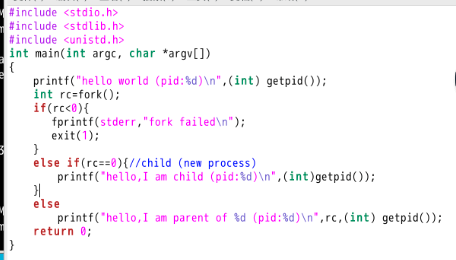
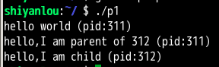
(这里的解释不是很懂): Now the interesting part begins. The process calls the fork() system call, which the OS provides as a way to create a new process. The odd part: the process that is created is an (almost) exact copy of the calling process. That means that to the OS, it now looks like there are two copies of the program p1 running, and both are about to return from the fork() system call. The newly-created process (called the child, in contrast to the creating parent) doesn’t start running at main(), like you might expect (note, the “hello, world” message only got printed out once); rather, it just comes into life as if it had called fork() itself. You might have noticed: the child isn’t an exact copy. Specifically, although it now has its own copy of the address space (i.e., its own private memory), its own registers, its own PC, and so forth, the value it returns to the caller of fork() is different. Specifically, while the parent receives the PID of the newly-created child, the child is simply returned a 0. This differentiation is useful, because it is simple then to write the code that handles the two different cases (as above).

(还是不太理解exec()这个系统调用的作用)
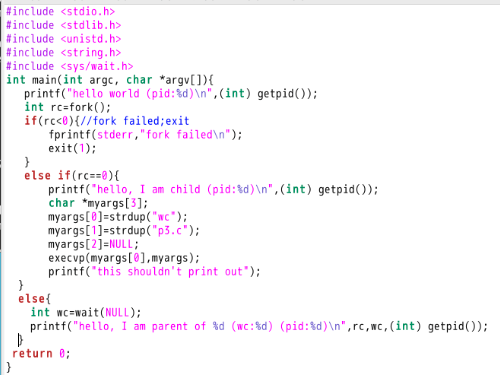
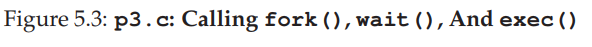
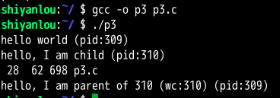
Shell 的运行过程(最重要的是fork()和exec()的组合):
The shell is just a user program4 . It shows you a prompt and then waits for you to type something into it. You then type a command (i.e., the name of an executable program, plus any arguments) into it; in most cases, the shell then figures out where in the file system the executable resides, calls fork() to create a new child process to run the command, calls some variant of exec() to run the command, and then waits for the command to complete by calling wait(). When the child completes, the shell returns from wait() and prints out a prompt again, ready for your next command。
For now, suffice it to say that the fork()/exec() combination is a powerful way to create and manipulate processes。
(花时间阅读Man Pages对系统程序员来说很重要)
Spending some time reading man pages is a key step in the growth of a systems programmer;

单处理机。(CPU每次只运行一个程序)

操作系统如何实现分时系统?
we’ll also see where the “limited” part of the name arises from; without limits on running programs, the OS wouldn’t be in control of anything and thus would be “just a library” – a very sad state of affairs for an aspiring operating system!
开机时,操作系统所做的事情:
The kernel does so by setting up a trap table at boot time. When the machine boots up, it does so in privileged (kernel) mode, and thus is free to configure machine hardware as need be. One of the first things the OS thus does is to tell the hardware what code to run when certain exceptional events occur. For example, what code should run when a hard-disk interrupt takes place, when a keyboard interrupt occurs, or when program makes a system call? The OS informs the hardware of the locations of these trap handlers, usually with some kind of special instruction. Once the hardware is informed, it remembers the location of these handlers until the machine is next rebooted, and thus the hardware knows what to do (i.e., what code to jump to) when system calls and other exceptional events take place。
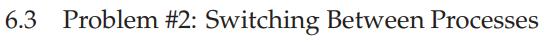
OS如何切换进程。
问题的关键是:进程在CPU运行的时候,OS没有占用CPU。(因为CPU每时每刻只能允许一个程序运行)那OS如何切换进程呢?

One approach that some systems have taken in the past is known as the cooperative approach In this style, the OS trusts the processes of the system to behave reasonably. Processes that run for too long are assumed to periodically give up the CPU so that the OS can decide to run some other task.
Most processes, as it turns out, transfer control of the CPU to the OS quite frequently by making system calls
Thus, in a cooperative scheduling system, the OS regains control of the CPU by waiting for a system call or an illegal operation of some kind to take place
你可能会有疑问:那万一程序陷入了无限循环咋办?
You might also be thinking: isn’t this passive approach less than ideal? What happens, for example, if a process (whether malicious, or just full of bugs) ends up in an infinite loop, and never makes a system call? What can the OS do then?


2019-10-26
00:09:20
第四章课后题:
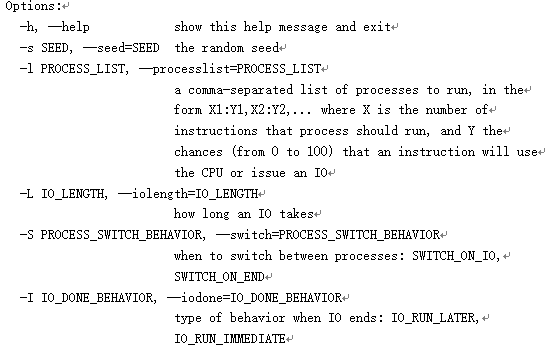
问题1:
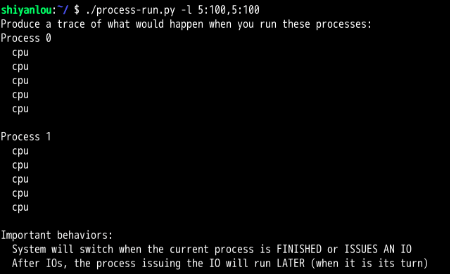

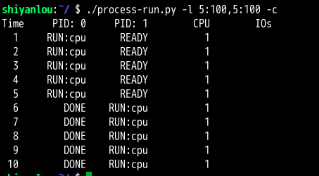
CPU使用率为100%
问题2:
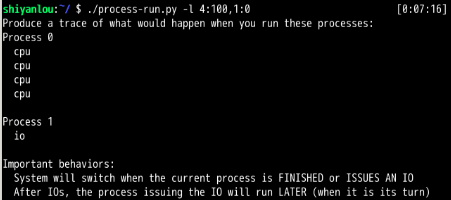
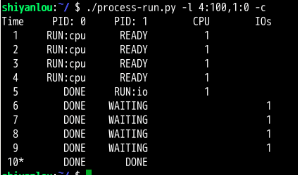
CPU利用率为56%。 完成这两个进程需要10,
问题3: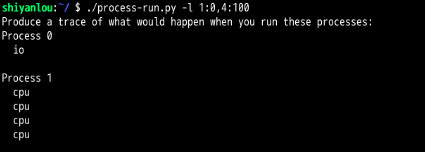
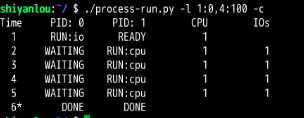
发现:CPU利用率达到了100%,交换顺序真的是太重要了!因为直接把CPU利用率从56%提高到了100%。
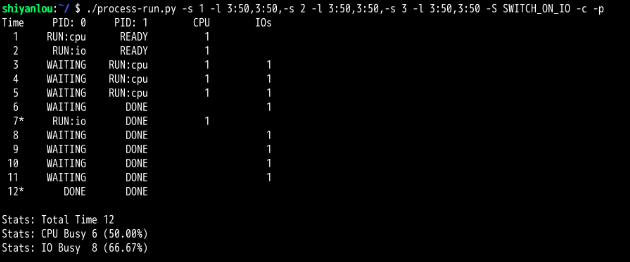
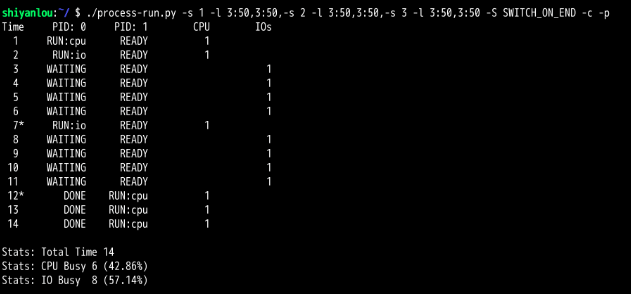
第4题:
如果SWITCH_ON_END位开启,那么在进行IO操作时,不会切换到CPU运行,此时就造成了CPU空闲。导致资源的浪费
第5题:
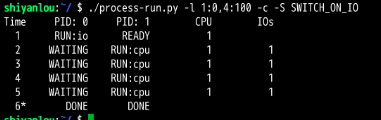
如果SWITCH_ON_IN位开启,那么在进行IO操作时,就会切换到CPU运行,此时就合理的利用了CPU
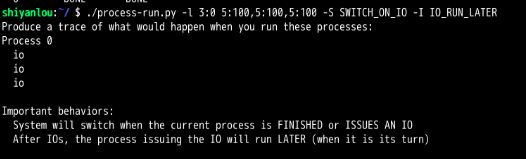
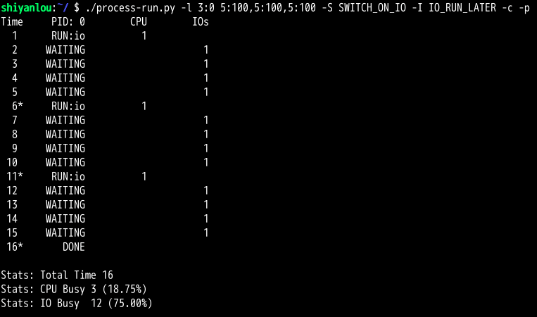
CPU先取指执行,第一条取得访问IO的指令,那么进程就切换到IO,此时CPU一直是空闲状态,接着等待IO结束,此时又取指执行,又来了两次。
所以单进程访问IO时,会导致CPU严重的资源浪费,所以要引入多进程。
第7题:
与第6题结果相同
第8题:
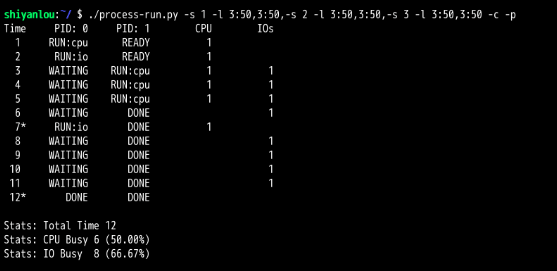
第7章 进程调度:习题
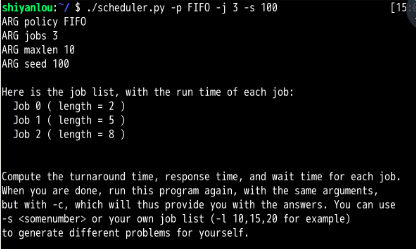
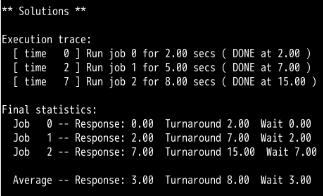

问题1:
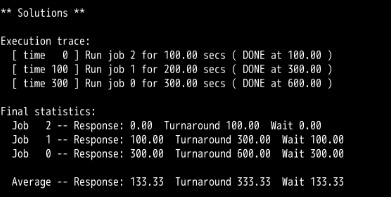
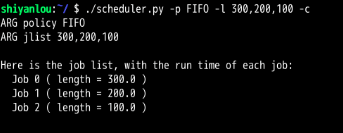
FIFO
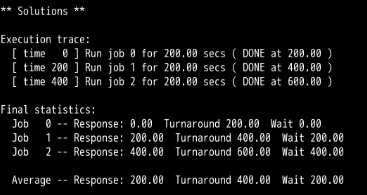
SJF
2.
FIFO:

SJF:

第3题:
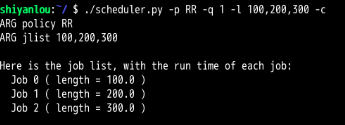
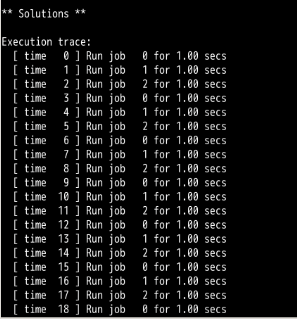
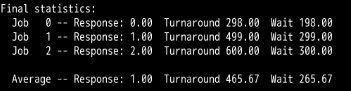
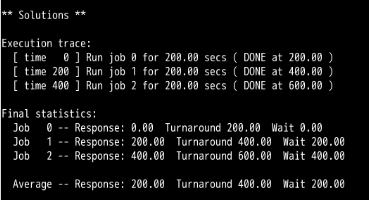
可以看到:RR调度算法的平均周转时间和平均等待时间比SJF,FIFO算法长,而平均响应时间则比SJF和FIFO快的不是一点半点。
第4题:
第1题,和第2题可以看出,都可以满足SJF与FIFO有着相同的周转时间。
现在给出如下的例子:


可以看出,此时SJF比FIFO更优,而且周转时间SJF比FIFO快。
结论就是:只有当进入的进程的先后顺序为:A,B,C,....,且A,B,C..的长度满足A<=B<=C<=.....时,即依次递增时,才会满足SJF与FIFO有着相同的周转时间。
第5题:
记录在书中
第6题:
时间分别是 500 ,400 ,300
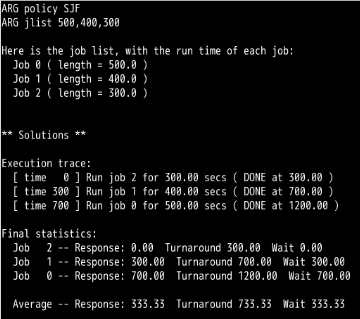
可以看到响应时间会增加。
第7题:
增加时间片长度至10.(从1 增加至 10,与第3题形成对比)
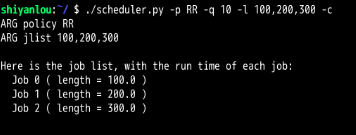

可以看到平均响应时间从1至10,平均周转时间没变,而平均等待时间从265.67减少至了256.67
第7题:
测试:当时间片长度 > 每个进程的长度时 , RR算法会退化为FIFO 算法,效率会大大降低
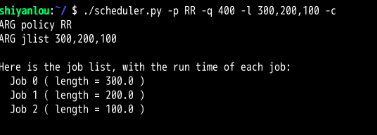
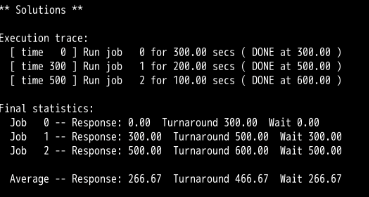
RR:
FIFO:
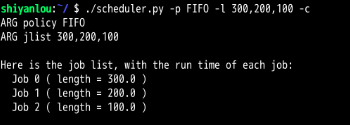
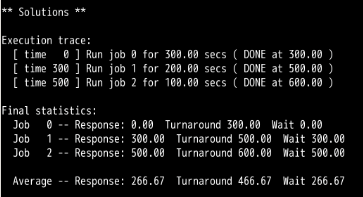
所以给出的方程式为:当有N个工作时,只有当RR的时间片 >= MAX(R1,R2,R3,....Rn)时,此时是最坏情况的响应时间
第八章
第1题
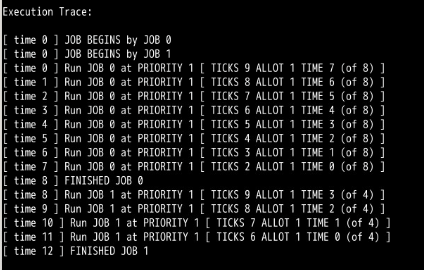
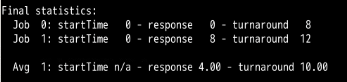
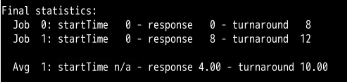
把时间片设置为20,可以看到

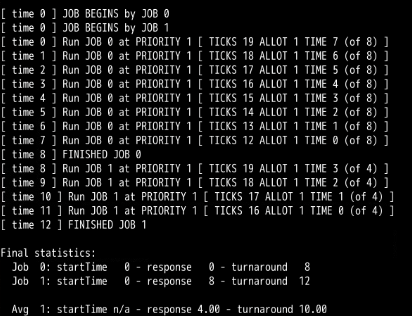
第3题:
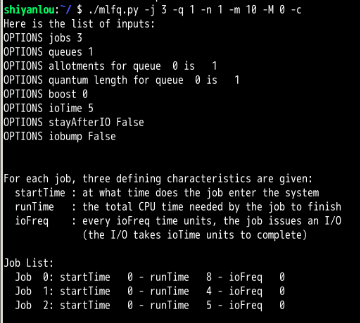
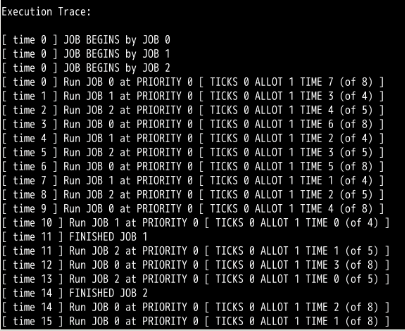

要使mlfq调度程序像时间片轮转调度那样,只需要这几个作业在一个优先级队列即可
第4题:(不会)
--jlist 0,180,0 : 50,150,50, -q 10 -S -i 1 -I (不会)
第5题:
彩票调度算法:

应用在分布式上
作业:
1.
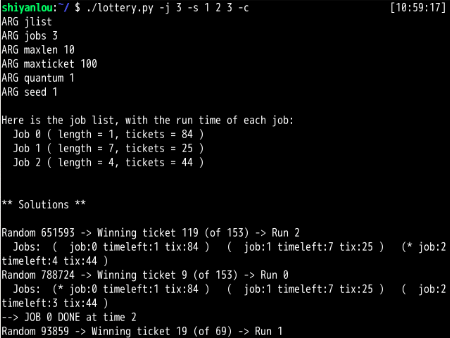
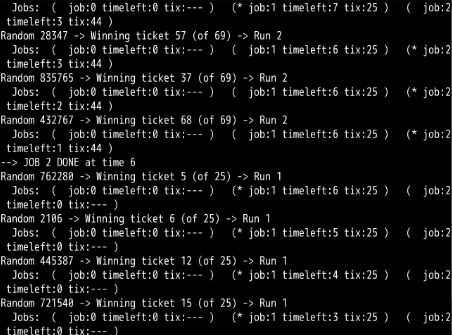

第2题:
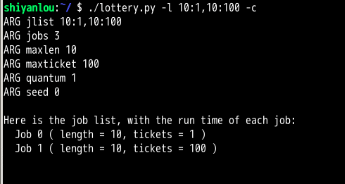
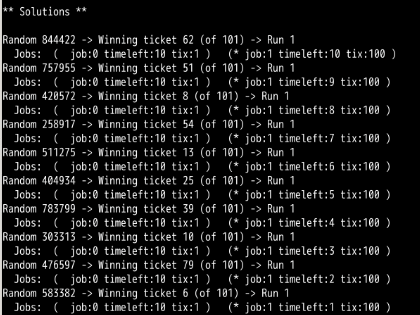
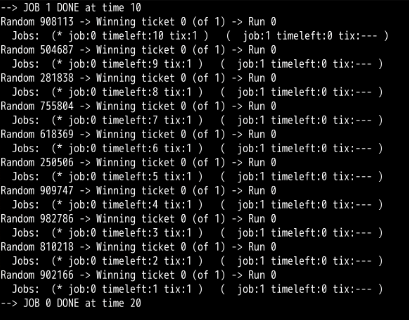
彩票数量如此不平衡时,会发生“饿死”现象。工作1完成之前,工作0几乎99%不可能完成。
第3题:
第一次模拟: 第2次: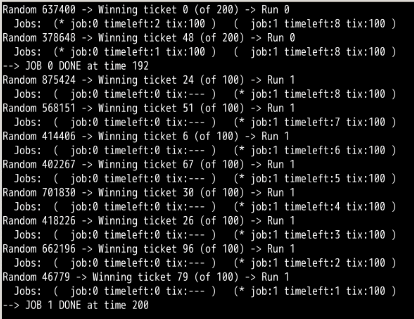
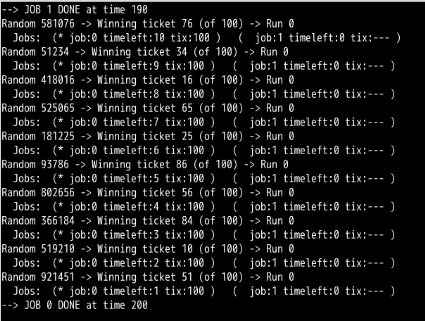
工作0完成时间:192 工作0 完成时间:190
工作1完成时间:200 工作1完成时间 : 200
第3次模拟: 第4次模拟:
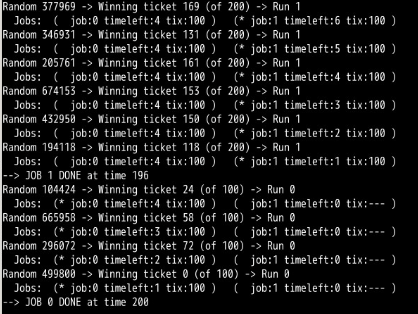
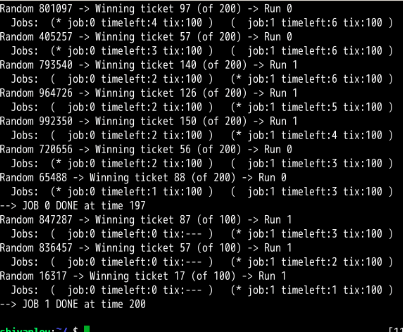
工作0完成时间:200 工作0完成时间:197
工作1完成时间:196 工作1完成时间:200
所以相对来说还是公平的,误差都在10内
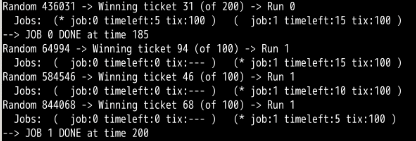
第4题:
-q 为 2 ,此时时间片大小为2,可以看到误差减小了。
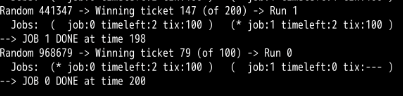
-q 为 3 , 此时误差变大
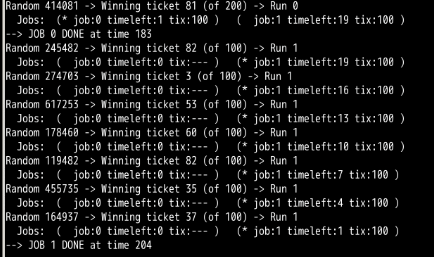
-q 为 4,此时误差变大
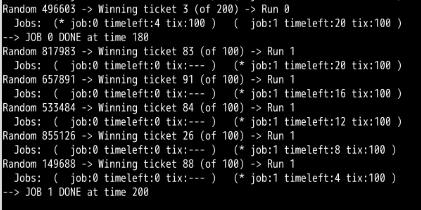
-q 为 5 时:误差变大
第13章:


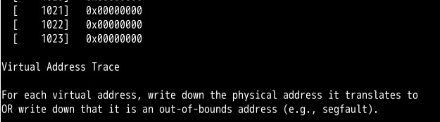
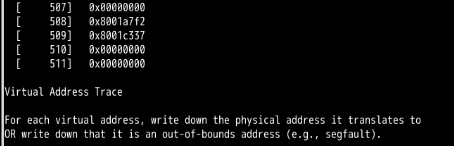
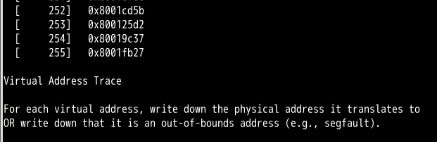
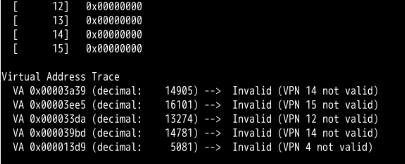
看到的全部都是虚拟地址。
第14章:
忘记分配内存


15章作业:
第1题:

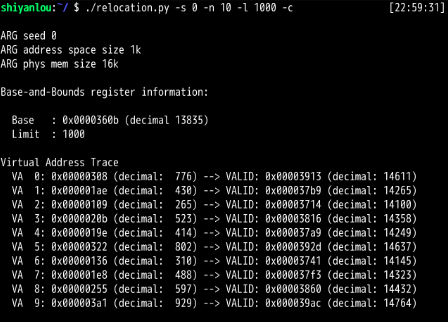
第2题: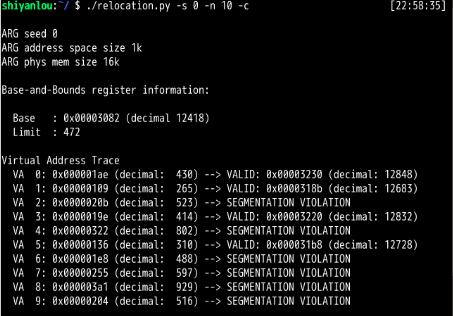
可以看出,为了确保所有生成的虚拟地址都处于边界内,要将界限寄存器设置为1000即可
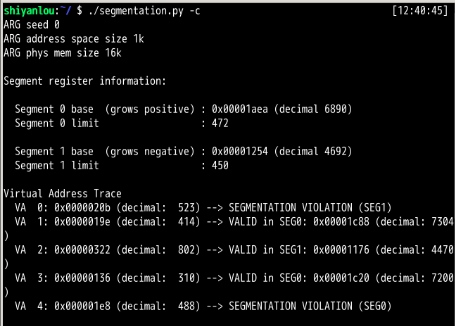
第16章:
、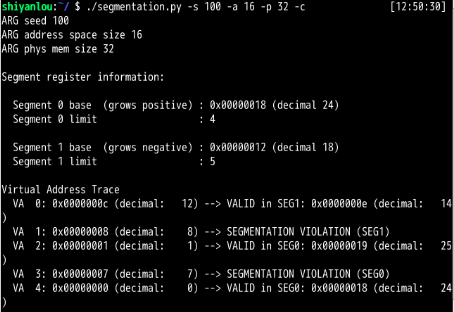
第1题:
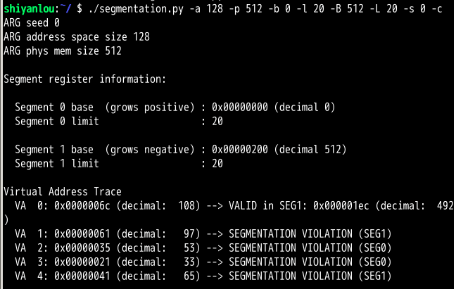

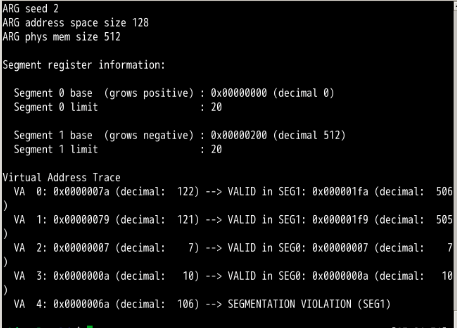
第17章:
作业参考答案:https://github.com/ahmedbilal/OSTEP-Solution/tree/master/Chapter%2017
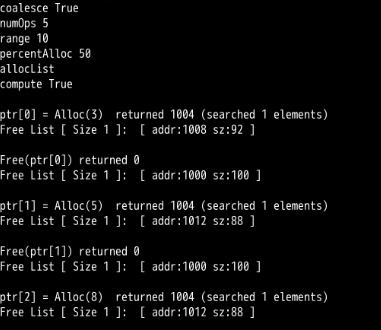
第1题:
First run with the flags -n 10 -H 0 -p BEST -s 0 to generate a few random allocations and frees. Can you predict what alloc()/free() will return? Can you guess the state of the free list after each request? What do you notice about the free list over time?
Yes, it is predictable if we are told the following things in advances
- Base Address = 1000
- Heap Size = 100
Free list become conjested over time with smaller and smaller size of free space block.
Output
ptr[0] = Alloc(3) returned 1000 (searched 1 elements) Free List [ Size 1 ]: [ addr:1003 sz:97 ]
Free(ptr[0]) returned 0 Free List [ Size 2 ]: [ addr:1000 sz:3 ] [ addr:1003 sz:97 ]
ptr[1] = Alloc(5) returned 1003 (searched 2 elements) Free List [ Size 2 ]: [ addr:1000 sz:3 ] [ addr:1008 sz:92 ]
Free(ptr[1]) returned 0 Free List [ Size 3 ]: [ addr:1000 sz:3 ] [ addr:1003 sz:5 ] [ addr:1008 sz:92 ]
ptr[2] = Alloc(8) returned 1008 (searched 3 elements) Free List [ Size 3 ]: [ addr:1000 sz:3 ] [ addr:1003 sz:5 ] [ addr:1016 sz:84 ]
Free(ptr[2]) returned 0 Free List [ Size 4 ]: [ addr:1000 sz:3 ] [ addr:1003 sz:5 ] [ addr:1008 sz:8 ] [ addr:1016 sz:84 ]
ptr[3] = Alloc(8) returned 1008 (searched 4 elements) Free List [ Size 3 ]: [ addr:1000 sz:3 ] [ addr:1003 sz:5 ] [ addr:1016 sz:84 ]
Free(ptr[3]) returned 0 Free List [ Size 4 ]: [ addr:1000 sz:3 ] [ addr:1003 sz:5 ] [ addr:1008 sz:8 ] [ addr:1016 sz:84 ]
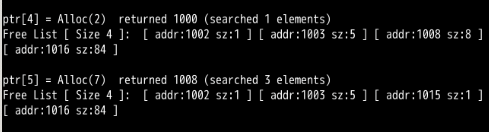
ptr[4] = Alloc(2) returned 1000 (searched 4 elements) Free List [ Size 4 ]: [ addr:1002 sz:1 ] [ addr:1003 sz:5 ] [ addr:1008 sz:8 ] [ addr:1016 sz:84 ]
ptr[5] = Alloc(7) returned 1008 (searched 4 elements) Free List [ Size 4 ]: [ addr:1002 sz:1 ] [ addr:1003 sz:5 ] [ addr:1015 sz:1 ] [ addr:1016 sz:84 ]
空闲列表将会被分割成许多小的段
第二题:

可以看出,最差匹配算法产生的外部碎片比最优匹配还要多。
书上说:大多数研究表明它的表现非常差,导致过量的碎片
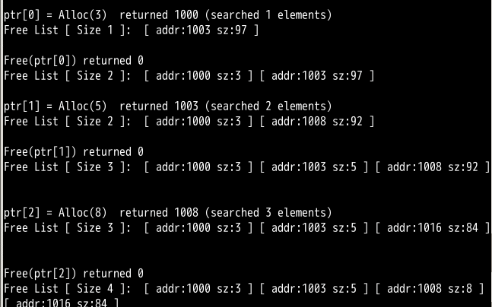
How are the results different when using a WORST fit policy to search the free list (-p WORST)? What changes?
Worst fit policy split and use the largest free memory block. Thus the returned small block were not used until the larger free mem. blocks are not splitted and used.
Output
ptr[0] = Alloc(3) returned 1000 List? [addr:1003, size:97]
Free(ptr[0]) returned 0 List? [(addr:1000, size:3), (addr:1003, size:97)]
ptr[1] = Alloc(5) returned 1003 List? [(addr:1000, size:3), (addr:1008, size:92)]
Free(ptr[1]) returned 0 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1008, size:92)]
ptr[2] = Alloc(8) returned 1008 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1016, size:84)]
Free(ptr[2]) returned 0 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1008, size:8), (addr:1016, size:84)]
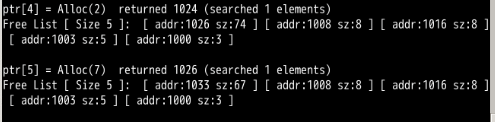
ptr[3] = Alloc(8) returned 1016 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1008, size:8), (addr:1024, size:76)]
Free(ptr[3]) returned 0 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1008, size:8), (addr:1016, size:8)(addr:1024, size:76)]
ptr[4] = Alloc(2) returned 1024 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1008, size:8), (addr:1016, size:8)(addr:1026, size:74)]
ptr[5] = Alloc(7) returned 1026 List? [(addr:1000, size:3), (addr:1003, size:5), (addr:1008, size:8), (addr:1016, size:8)(addr:1033, size:67)]
第3题: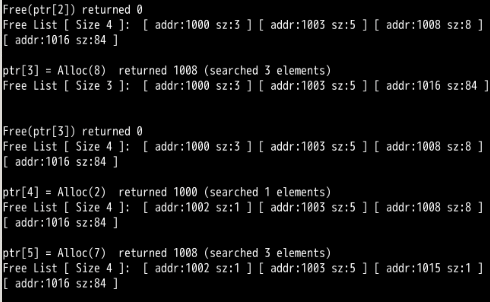
What about when using FIRST fit (-p FIRST)? What speeds up when you use first fit?
The lookup for enough empty space slot speeds up when we use first fit(首次使用时,查找足够的空白空间的速度会加快). Because, we don't have to examine all the available slots. We just allocate the first fitting memory block to the job requestion memory in heap.
第4题:
For the above questions, how the list is kept ordered can affect the time it takes to find a free location for some of the policies. Use the different free list orderings (-l ADDRSORT, -l SIZESORT+, -l SIZESORT-) to see how the policies and the list orderings interact.
Time remain unaffected in both best and worst fit policy because these have to scan the whole list. However, in first fit only sizesort- (descending order) decrease the time to find a free location because first fit chooses the appropriate size free location that come first. So, if the largest free memory location is head of list then all allocation are from this free mem. block because it fulfills the requirement of first fit policy.(
时间对最佳和最差策略均不受影响,因为它们必须扫描整个列表。
但是,在首次试穿时,只有sizesort-(降序)会减少找到空闲位置的时间,因为首次试穿会选择先出现的合适的免费尺码。
因此,如果最大的空闲内存位置是列表的头,那么所有分配都来自此空闲内存。
阻止,因为它符合“最适合政策”的要求。
)
递减顺序: 递增顺序:
第5题:
Question 5
Coalescing of a free list can be quite important. Increase the number of random allocations (say to -n 1000). What happens to larger allocation requests over time? Run with and without coalescing (i.e., without and with the -C flag). What differences in outcome do you see? How big is the free list over time in each case? Does the ordering of the list matter in this case?
Larger allocation requests failed in free mem. mechanism without coalescing because in that case free list would be filled with small free mem. blocks. Without coalescing the free list became conjested with a lot of small free memory blocks. This conjestion also increase look up time in nearly all free mem. lookup policies. The ordering of the list matters only in first fit free mem. location policy.
Question 6
What happens when you change the percent allocated fraction -P to higher than 50? What happens to allocations as it nears 100? What about as it nears 0?
Than Most heap operation would be allocation operation. When we increase the percent allocated fraction to near 100 or 100. Then nearly all operations would be allocation operations. If we approach 0 the allocations and free operation are done in 50%. Because, we can't free memory that isn't allocated. So, to free mem. we have to allocate some first.
比大多数堆操作将是分配操作。
当我们将百分比分配分数增加到接近100或100时,几乎所有操作都是分配操作。
如果我们接近0,则分配和自由操作将完成50%。
因为,我们无法释放未分配的内存。
因此,要释放内存。
我们必须先分配一些。
Question 7
What kind of specific requests can you make to generate a highly fragmented free space? Use the -A flag to create fragmented free lists, and see how different policies and options change the organization of the free list.
./malloc.py -n 6 -A +1,-0,+2,-1,+3,-2 -c
第18章:
第1题:
Question 1
Before doing any translations, let’s use the simulator to study how linear page tables change size given different parameters. Compute the size of linear page tables as different parameters change. Some suggested inputs are below; by using the -v flag, you can see how many page-table entries are filled. First, to understand how linear page table size changes as the address space grows:
paging-linear-translate.py -P 1k -a 1m -p 512m -v -n 0
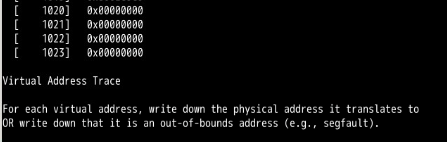
paging-linear-translate.py -P 1k -a 2m -p 512m -v -n 0
paging-linear-translate.py -P 1k -a 4m -p 512m -v -n 0
Then, to understand how linear page table size changes as page size grows:
paging-linear-translate.py -P 1k -a 1m -p 512m -v -n 0
paging-linear-translate.py -P 2k -a 1m -p 512m -v -n 0
paging-linear-translate.py -P 4k -a 1m -p 512m -v -n 0
页的大小不应该太大,因为每个进程使用的内存不是太多,如果分配给每个进程太大的页,则会造成内存浪费。
Before running any of these, try to think about the expected trends. How should page-table size change as the address space grows? As the page size grows? Why shouldn’t we just use really big pages in general?
Page table size increases as the address space grows because we need more pages to cover the whole address space. When Page sizes increases the page table size decreases because we need less pages (because they are bigger in size) to cover the whole address space.
We should not use really big pages in general because it would be a lot of waste of memory. Because, most processes use very little memory.
第2题:
Question 2
Now let’s do some translations. Start with some small examples, and change the number of pages that are allocated to the address space with the -u flag . For example:
paging-linear-translate.py -P 1k -a 16k -p 32k -v -u 0
paging-linear-translate.py -P 1k -a 16k -p 32k -v -u 25

paging-linear-translate.py -P 1k -a 16k -p 32k -v -u 50
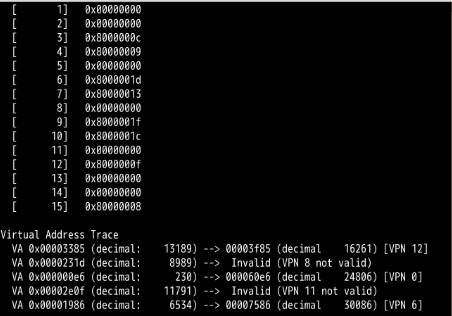
paging-linear-translate.py -P 1k -a 16k -p 32k -v -u 75
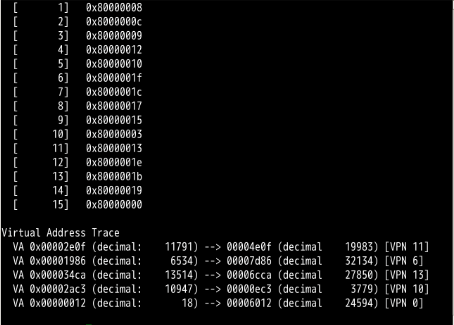
paging-linear-translate.py -P 1k -a 16k -p 32k -v -u 100
What happens as you increase the percentage of pages that are allocated in each address space?
地址空间越来越被充分利用,空闲空间越来越少
As, the percentage of pages that are allocated or usage of address space is increased more and more memory access operations become valid however free space decreases
第3题:
Now let’s try some different random seeds, and some different (and sometimes quite crazy) address-space parameters, for variety:
paging-linear-translate.py -P 8 -a 32
-p 1024 -v -s 1
paging-linear-translate.py -P 8k -a 32k -p 1m
-v -s 2
paging-linear-translate.py -P 1m -a 256m -p 512m -v -s 3
Which of these parameter combinations are unrealistic? Why?
- Too Small Size、、
第4题:
Question 4
Use the program to try out some other problems. Can you find the limits of where the program doesn’t work anymore? For example, what happens if the address-space size is bigger than physical memory?
It won't work when
- page size is greater than address-space.
- address space size is greater than the physical memory.
- physical memory size is not multiple of page size.
- address space is not multiple of page size.
- page size is negative.
- physical memory is negative.
- address space is negative.
2019-11-02
17:00:02
第19章:
https://github.com/xxyzz/ostep-hw/tree/master/19
第21章:
第22章:

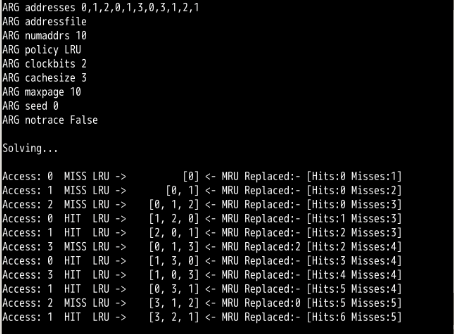


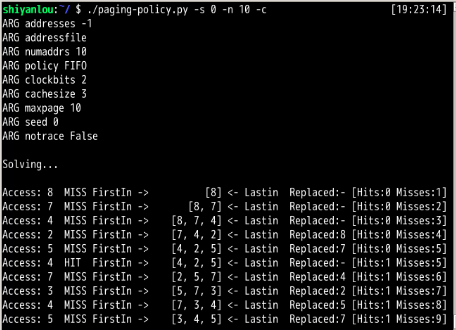




./paging-policy.py --addresses=0,1,2,3,4,5,0,1,2,3,4,5 --policy=FIFO --cachesize=5 -c
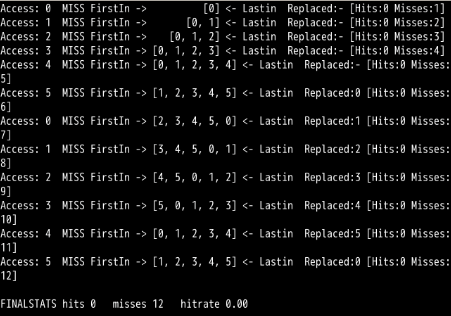
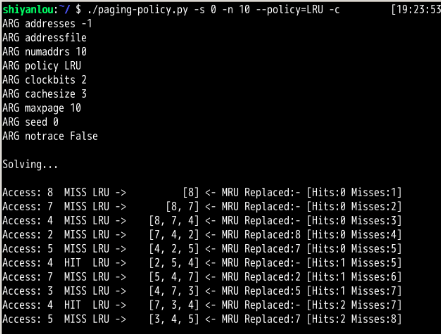
./paging-policy.py --addresses=0,1,2,3,4,5,0,1,2,3,4,5 --policy=LRU --cachesize=5 -c
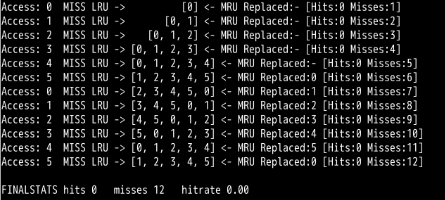
可以看到循环工作负载时,LRU出现最差情况
./paging-policy.py --addresses=0,1,2,3,4,5,4,5,4,5,4,5 --policy=MRU --cachesize=5 -c
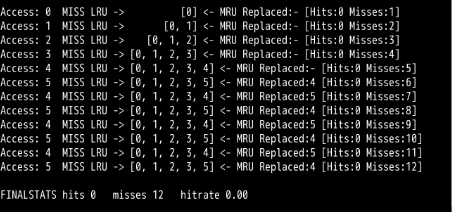
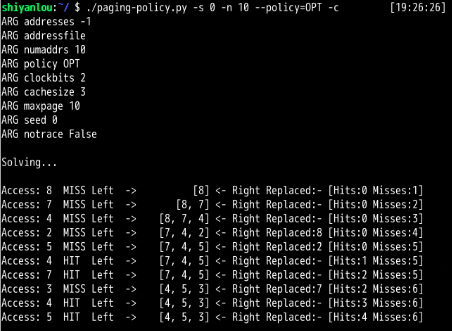
需要的缓存增大1,才能大幅提高性能,并接近OPT。
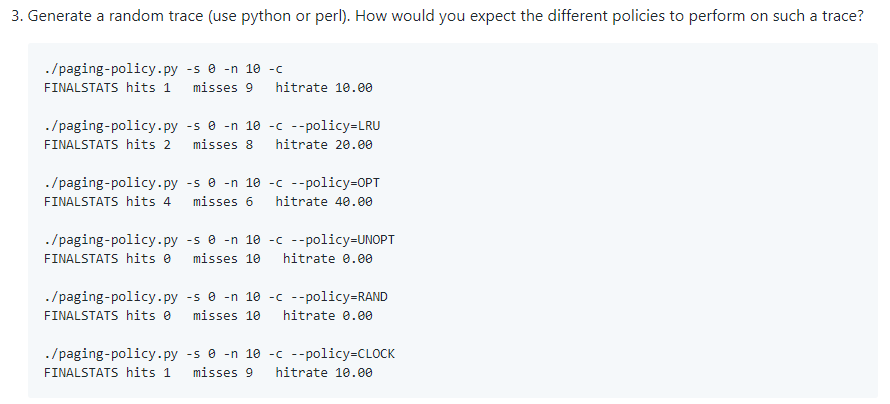


$ ./generate-trace.py [3, 0, 6, 6, 6, 6, 7, 0, 6, 6] $ ./paging-policy.py --addresses=3,0,6,6,6,6,7,0,6,6 --policy=LRU -c FINALSTATS hits 6 misses 4 hitrate 60.00 $ ./paging-policy.py --addresses=3,0,6,6,6,6,7,0,6,6 --policy=RAND -c FINALSTATS hits 5 misses 5 hitrate 50.00 $ ./paging-policy.py --addresses=3,0,6,6,6,6,7,0,6,6 --policy=CLOCK -c -b 2 Access: 3 MISS Left -> [3] <- Right Replaced:- [Hits:0 Misses:1] Access: 0 MISS Left -> [3, 0] <- Right Replaced:- [Hits:0 Misses:2] Access: 6 MISS Left -> [3, 0, 6] <- Right Replaced:- [Hits:0 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:1 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:2 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:3 Misses:3] Access: 7 MISS Left -> [3, 6, 7] <- Right Replaced:0 [Hits:3 Misses:4] Access: 0 MISS Left -> [3, 7, 0] <- Right Replaced:6 [Hits:3 Misses:5] Access: 6 MISS Left -> [7, 0, 6] <- Right Replaced:3 [Hits:3 Misses:6] Access: 6 HIT Left -> [7, 0, 6] <- Right Replaced:- [Hits:4 Misses:6] FINALSTATS hits 4 misses 6 hitrate 40.00 $ ./paging-policy.py --addresses=3,0,6,6,6,6,7,0,6,6 --policy=CLOCK -c -b 0 Access: 3 MISS Left -> [3] <- Right Replaced:- [Hits:0 Misses:1] Access: 0 MISS Left -> [3, 0] <- Right Replaced:- [Hits:0 Misses:2] Access: 6 MISS Left -> [3, 0, 6] <- Right Replaced:- [Hits:0 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:1 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:2 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:3 Misses:3] Access: 7 MISS Left -> [3, 0, 7] <- Right Replaced:6 [Hits:3 Misses:4] Access: 0 HIT Left -> [3, 0, 7] <- Right Replaced:- [Hits:4 Misses:4] Access: 6 MISS Left -> [3, 7, 6] <- Right Replaced:0 [Hits:4 Misses:5] Access: 6 HIT Left -> [3, 7, 6] <- Right Replaced:- [Hits:5 Misses:5] FINALSTATS hits 5 misses 5 hitrate 50.00 $ ./paging-policy.py --addresses=3,0,6,6,6,6,7,0,6,6 --policy=CLOCK -c -b 1 Access: 3 MISS Left -> [3] <- Right Replaced:- [Hits:0 Misses:1] Access: 0 MISS Left -> [3, 0] <- Right Replaced:- [Hits:0 Misses:2] Access: 6 MISS Left -> [3, 0, 6] <- Right Replaced:- [Hits:0 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:1 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:2 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:3 Misses:3] Access: 7 MISS Left -> [3, 0, 7] <- Right Replaced:6 [Hits:3 Misses:4] Access: 0 HIT Left -> [3, 0, 7] <- Right Replaced:- [Hits:4 Misses:4] Access: 6 MISS Left -> [3, 7, 6] <- Right Replaced:0 [Hits:4 Misses:5] Access: 6 HIT Left -> [3, 7, 6] <- Right Replaced:- [Hits:5 Misses:5] FINALSTATS hits 5 misses 5 hitrate 50.00 $ ./paging-policy.py --addresses=3,0,6,6,6,6,7,0,6,6 --policy=CLOCK -c -b 3 Access: 0 MISS Left -> [3, 0] <- Right Replaced:- [Hits:0 Misses:2] Access: 6 MISS Left -> [3, 0, 6] <- Right Replaced:- [Hits:0 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:1 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:2 Misses:3] Access: 6 HIT Left -> [3, 0, 6] <- Right Replaced:- [Hits:3 Misses:3] Access: 7 MISS Left -> [3, 6, 7] <- Right Replaced:0 [Hits:3 Misses:4] Access: 0 MISS Left -> [6, 7, 0] <- Right Replaced:3 [Hits:3 Misses:5] Access: 6 HIT Left -> [6, 7, 0] <- Right Replaced:- [Hits:4 Misses:5] Access: 6 HIT Left -> [6, 7, 0] <- Right Replaced:- [Hits:5 Misses:5] FINALSTATS hits 5 misses 5 hitrate 50.00