0. 参考
1. 分析
1.1 定位目标元素
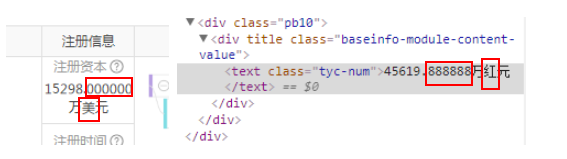
1.2 查看网页源代码

1.3 requests 请求提取得到大量错误信息
对比猫_眼_电_影抓取到unicode编码,天_眼_查混合使用正常字体和自定义字体,难点在于如何从 '红' 转化为 '美'。
一开始认为一定有js进行了转化,最后发现直接通过 FontCreator 搜索 '红' 返回结果为 '美' 。。。
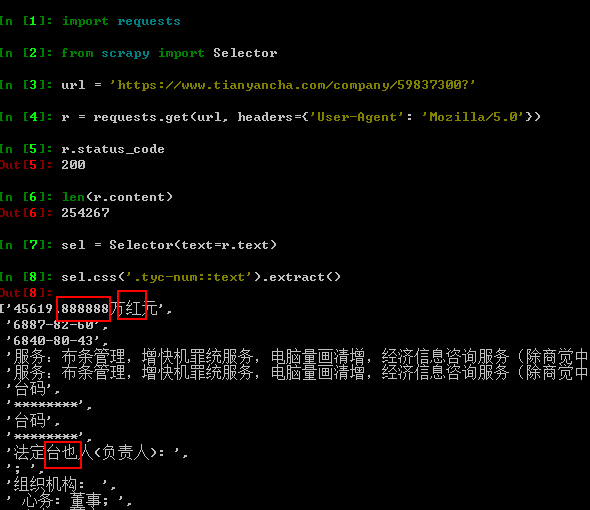
1.4 查看目标元素 CSS Computed 信息,使用了网络请求字体
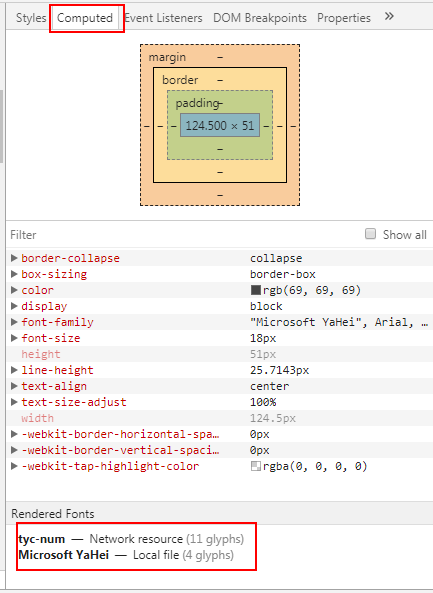
1.5 查看 字体文字 请求
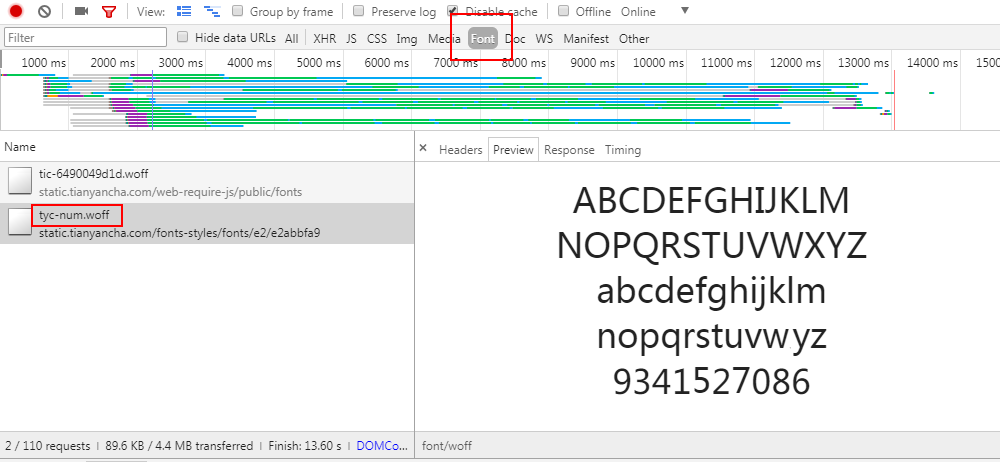
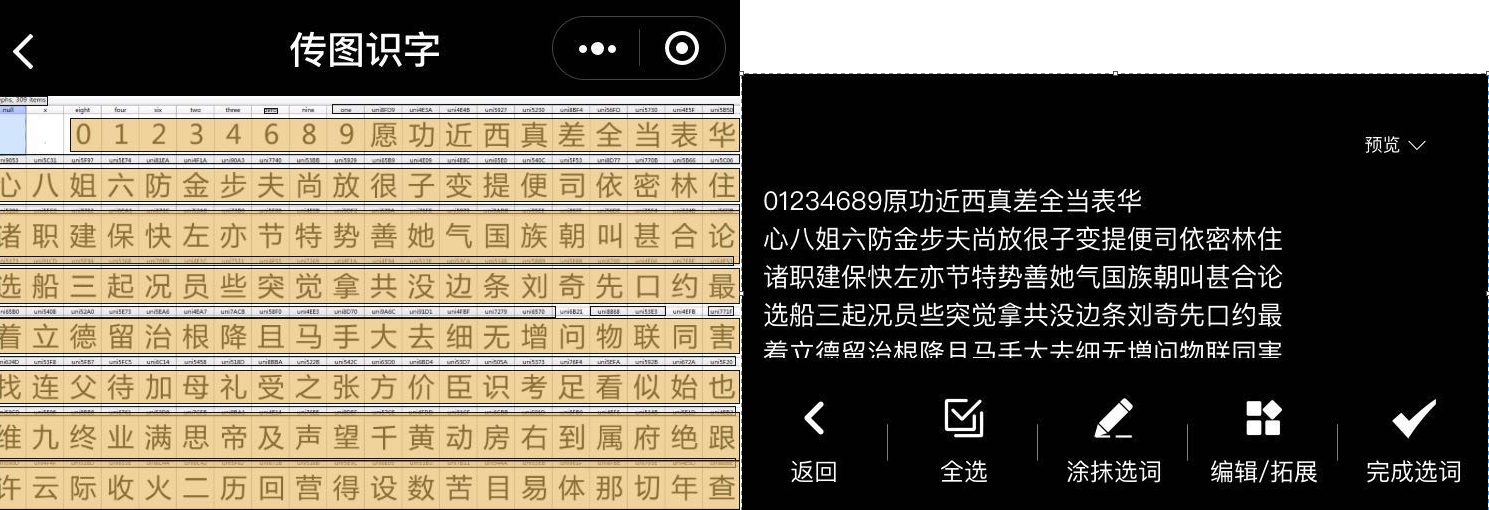
1.6 使用 FontCreator 打开字体文件 {'eight': 0, 'four': 1} 能够解密上文的数字映射
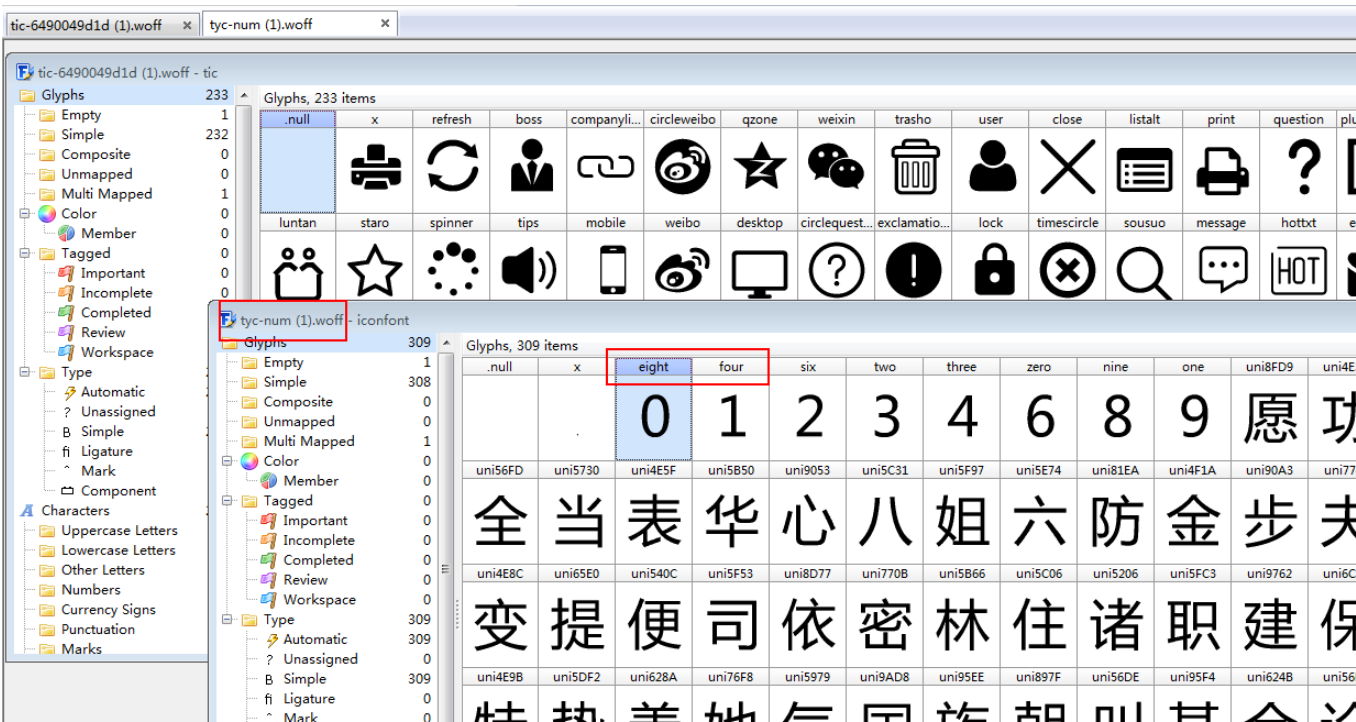
1.7 ctrl + f 搜索 ‘红’ 出现对应的 '美',注意 hex(ord('红')) 结果为 '0x7ea2' ,也可搜索十进制的unicode编码 32418
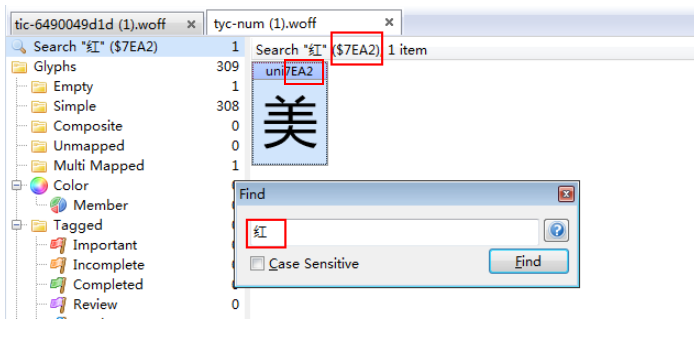
1.8 全局搜索 tyc-num
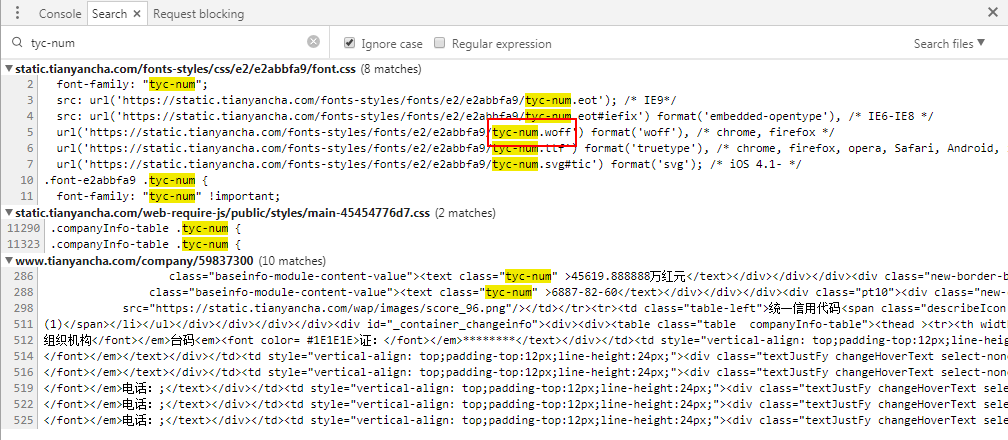
1.9 全局搜索 tyc-num.woff

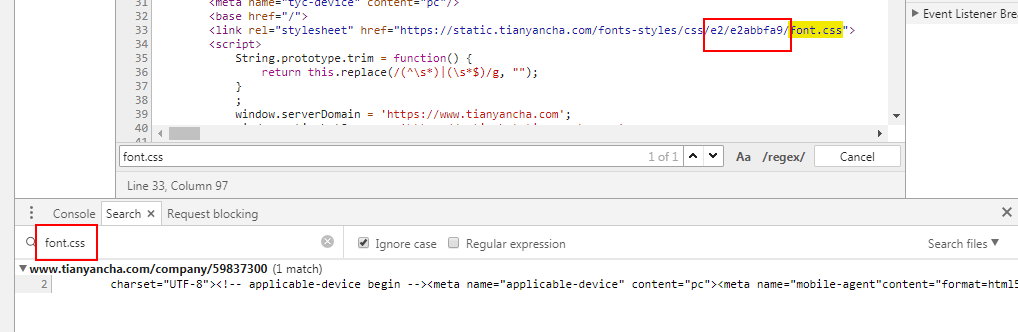
1.10 全局搜索 font.css 看起来是动态生成文件(每天一更,使用不同的中文字集合)
2. JS分析
线索:全局搜索 .tyc-num tyc-num
根据下文 xml 文件信息考虑搜索 0x, 也可以考虑搜索 js 将中文转为 unicode 的方法关键字, 以及 65535/65536
另外不经意看到 'code point' 相关代码
最终还是找不到如何从 '红' 转 '美' 的相关 js 代码
考虑到上文 FontCreator 搜索 '红' 返回结果为 '美',似乎可以直接绕开 js 解密。。。
3. 字体文件分析
3.1 字体文件 woff 转 xml
详见参考文章
对比前后两天下载的 woff 字体文件,应该是批量生成的历史文件
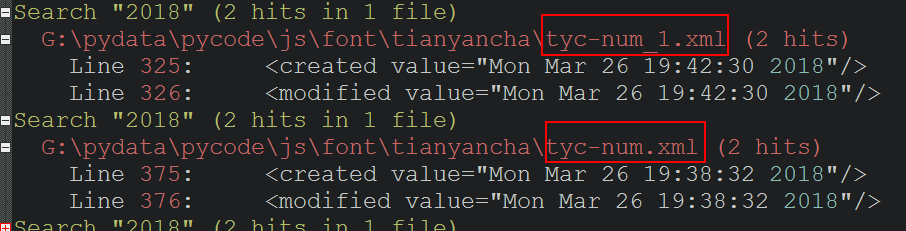
3.2 根据步骤 1.7 搜索 '7ea2' 结果集中在 <cmap>
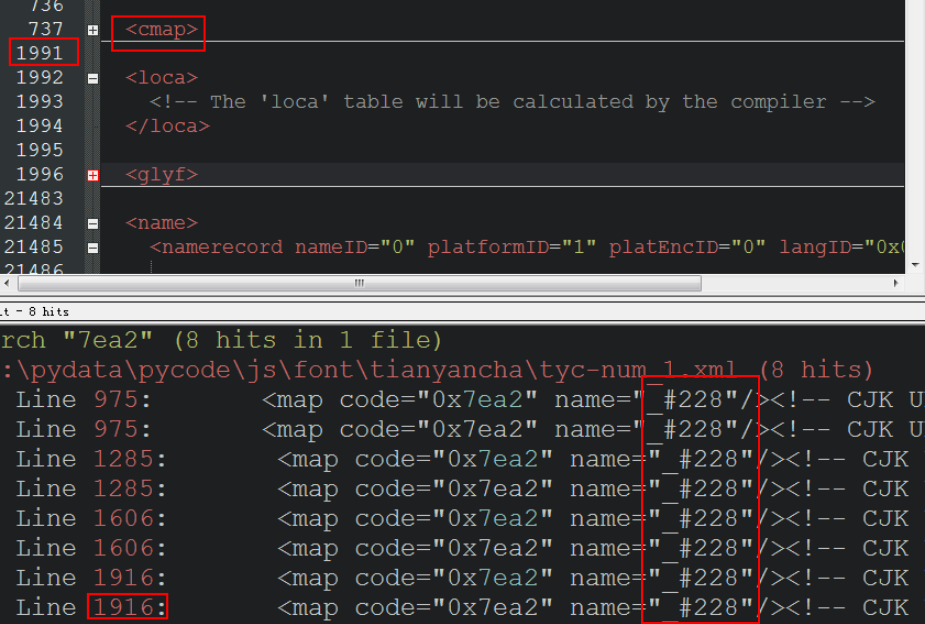
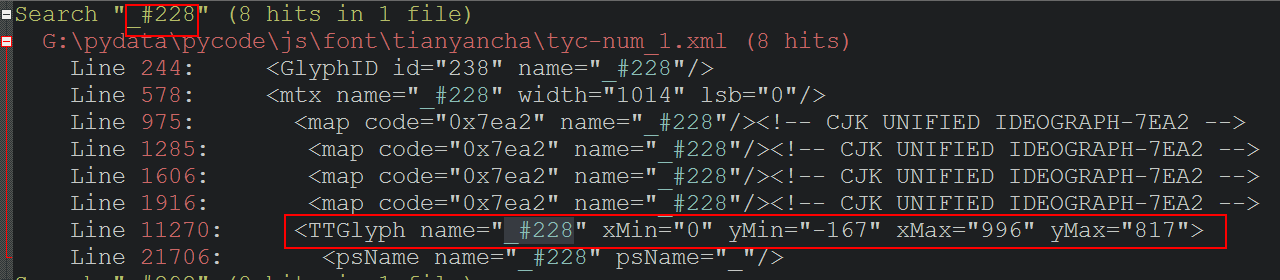
3.3 根据上图继续搜索 '_#228', 根据参考文章可知,下图方框的 name="_#228" 对应于某个字形定义,用于渲染显示
4. 使用 python 实现 '红' >>> '美'
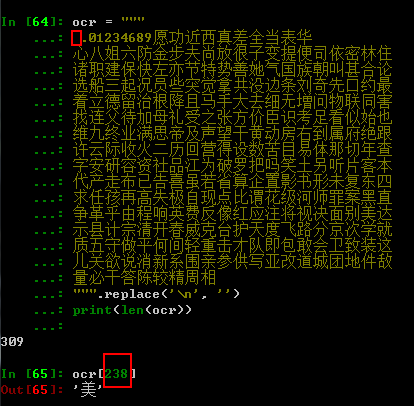
思路:提取 '红',计算unicode编码,根据 <cmap> 匹配到name='_#228', 再使用 '_#228' 根据 <glyf> 到某一字形定义'美'
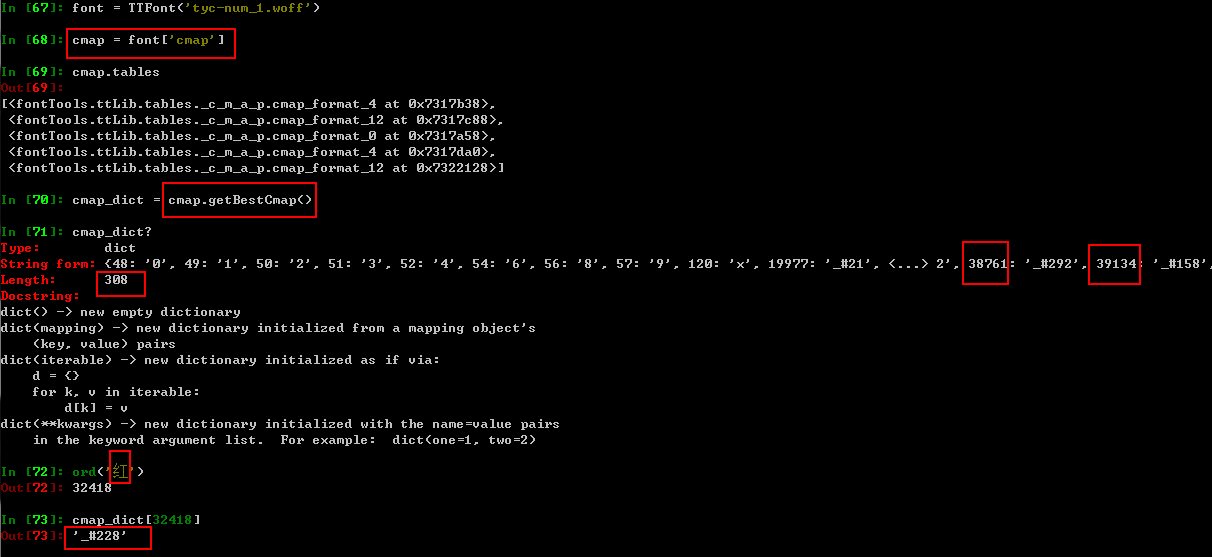
4.1 fontTools 读取 <cmap> 字典 {十进制的unicode编码: '_#xxx', ...}
4.2 fontTools 读取 <glyf> name 列表 ['_#xxx', ...]

4.3 手动建立真实字符列表
使用微信小程序识别效果令人惊叹
成功对应
5. 完整代码


import requests from scrapy import Selector from fontTools.ttLib import TTFont url = 'https://www.tianyancha.com/company/59837300?' ocr = """ .01234689愿功近西真差全当表华 心八姐六防金步夫尚放很子变提便司依密林住 诸职建保快左亦节特势善她气国族朝叫甚合论 选船三起况员些突觉拿共没边条刘奇先口约最 着立德留治根降且马手大去细无増问物联同害 找连父待加母礼受之张方价臣识考足看似始也 维九终业满思帝及声望干黄动房右到属府绝跟 许云际收火二历回营得设数苦目易体那切年查 字安研容资社品江为破罗把吗笑土另听片客本 代产走布已告喜虽若省算企置影书形未复东四 求任孩再高失极自现点比谓花级河师罪案黑直 争革乎由程响英费反像红应注将视决面别美达 示县计宗清开春威克台护天度飞路分京次学就 质五守做平何间轻重击才队即包敢会卫致装这 儿关欲说消新系围亲参供写亚改道城团地件敌 量必干答陈较精周相 """.replace('\n', '') print(len(ocr)) font = TTFont('tyc-num_1.woff') cmap = font['cmap'] cmap_dict = cmap.getBestCmap() print(len(cmap_dict)) glyf_list = list(font['glyf'].keys()) print(len(glyf_list)) r = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}) print(r.status_code, len(r.content)) sel = Selector(text=r.text) # text = '45619.888888万红元 6887-82-60' # 15298.000000万美元 2007-03-26 for text in sel.css('.tyc-num::text').extract(): result = [] for t in text: code = ord(t) #红:32418 name = cmap_dict.get(code, None) #_#228 if name is not None: index = glyf_list.index(name) #238 rst = ocr[index] #美 else: rst = t result.append(rst) print(text, ' >>> ', ''.join(result)) print('#'*10)
6.运行结果
