1 . 什么是 AJAX ?
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 AJAX)如果需要更新内容,必需重载整个网页面。
几个常见的用到ajax的场景。
比如你在逛知乎,你没有刷新过网页,但是你却能看到你关注的用户或者话题有了新动态的消息提示。
还比如,我们在看视频时,可以看到下面的评论没有完全全部加载出来,而是你向下拖动一点,它给你加载一点。
为什么要用到ajax呢?
从上述场景你应该也可以发现它的优点,
第一,方便与用户的交互,不用重新加载整个网页,就可以实现刷新,不用中断用户的行为。你正在看程序员如何找对象呢,此时来个消息推送,整个网页被刷新了,你说你气不气!
第二个呢,还是你在看程序员如何找对象,但是此时通信状况不好啊。回答加载不出来,页面就空白的卡那了,回答加载不出来,你说急不急!那这样咯,先给你看几个回答,在你看的时候我再悄悄的加载其它的数据,那不就解决了吗?就跟吃饭一个道理,你点了一桌子菜,难道菜全做好了再给你上吗?肯定不会的呀,做好一道上一道嘛,对不对。
第三,从服务端的发送过来的ajax数据,体积比较小。浏览器知道怎么渲染它,这样就减轻了服务端的压力,让客户端,也就是浏览器承担了一些任务。
Ajax技术的核心是XMLHttpRequest对象(简称XHR),可以通过使用XHR对象获取到服务器的数据,然后再通过DOM将数据插入到页面中呈现。虽然名字中包含XML,但Ajax通讯与数据格式无关,所以我们的数据格式可以是XML或JSON等格式。
XMLHttpRequest对象用于在后台与服务器交换数据,具体作用如下:
- 在不重新加载页面的情况下更新网页
- 在页面已加载后从服务器请求数据
- 在页面已加载后从服务器接收数据
- 在后台向服务器发送数据
2. Ajax对爬虫有什么影响?
还是对应着上述的场景,我爬虫肯定要爬取一个完整数据。但是你一次就只教我两种找对象的方法。还不够我举一反三呢,万一其中还有几个段子,那这样的数据不具有完整性,不够全面。但是不滑动浏览器,数据不出来怎么办?
更坑爹是什么,ajax加载出来的数据是通过浏览器渲染给我们的呀,源代码不一定能找到我们要的数据。那该肿么办!浏览器知道怎么加载, 我们不知道呀!
3.如何爬取这样的ajax动态加载的网页。
1. Selenium + PhantomJs
PhantomJS是一个无界面的,可脚本编程的WebKit浏览器引擎。它原生支持多种web 标准:DOM 操作,CSS选择器,JSON,Canvas 以及SVG。它的作用是和浏览器类似,可以渲染js处理的页面。
selenium是什么呢?它本来是个自动化测试工具,但是被广泛的用户爬虫啊。它是一个工具,这个工具可以用代码操作浏览器。比如控制浏览器的下滑之类。不过我并不是很熟悉,以前了解过一点。
不过,我没用这种方法。为啥呢,因为慢。操作浏览器的时间加起来好多好多了呗,而且又不是没有更好的办法。
2. 自己找,找真实请求。
只要是有数据发送过来,那肯定是有发送到服务器的请求的吧。我们只需找出它悄悄加载出的页面的真实请求在哪发送的。
寻找实例:爬取杭州萧山机场一天的航班信息。
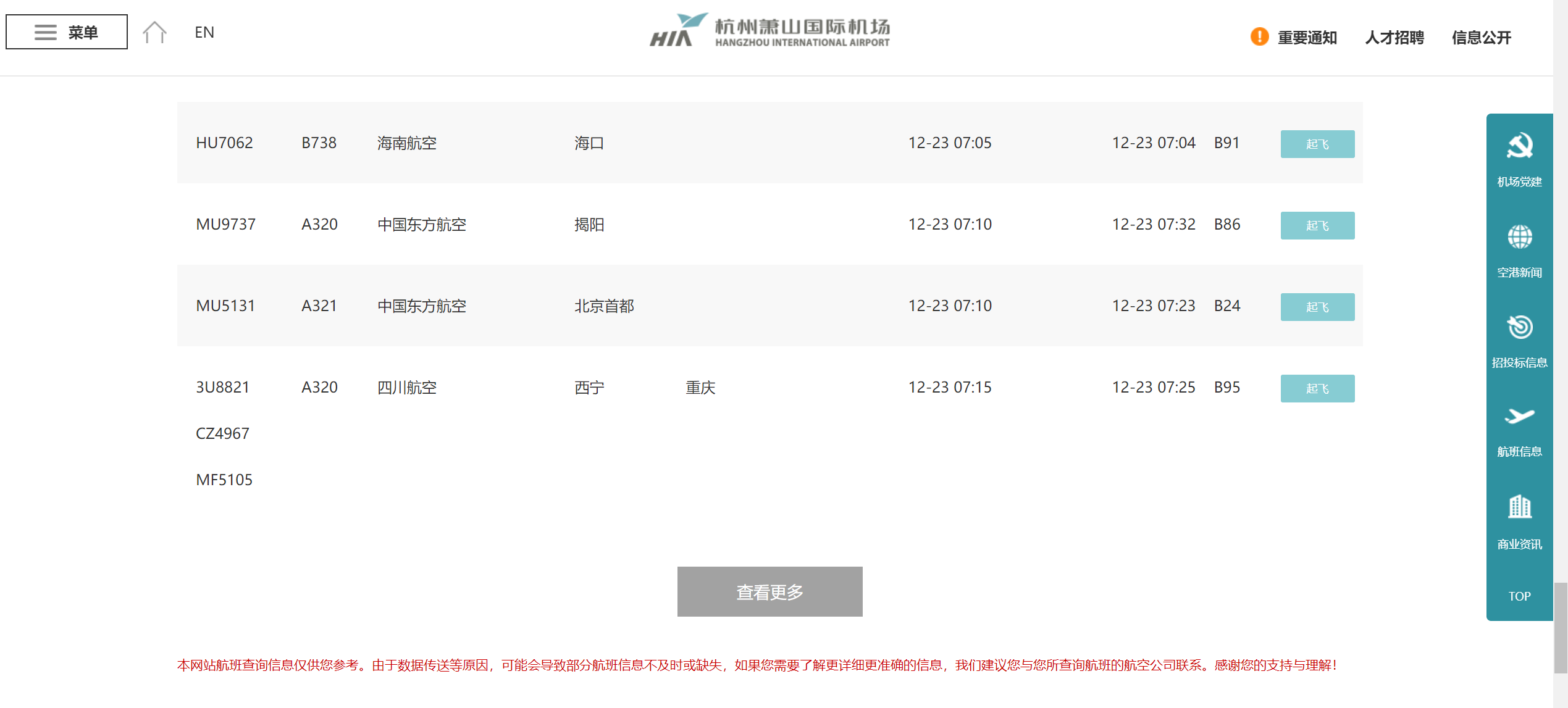
1)右键单击查看网页源码,发现点击“查看更多”之后的页面源码里没有新出现的航班信息,所以猜测它是使用了Ajax技术。用Wireshark抓个包先。
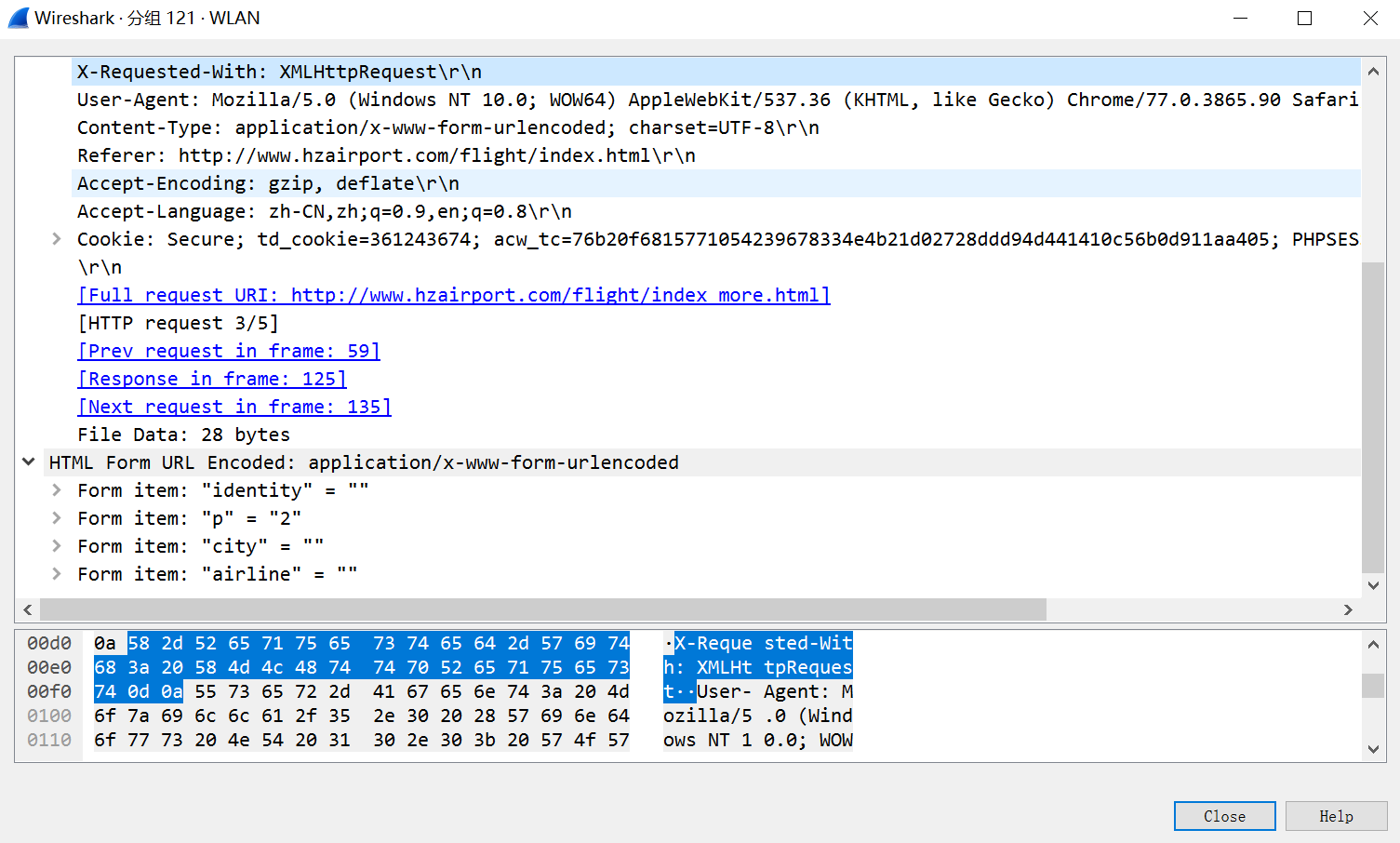
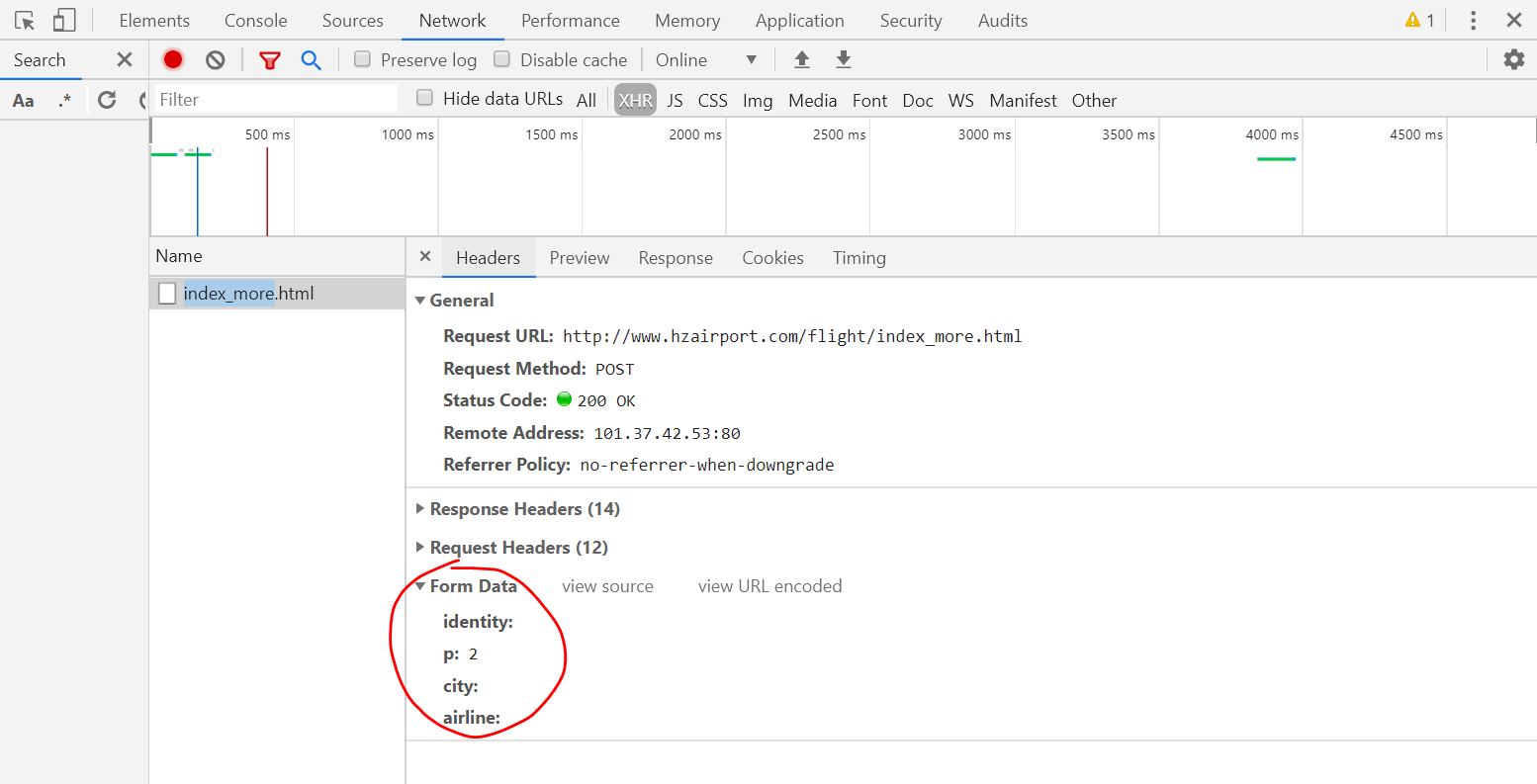
2.寻找传送XMLHttpRequest对象的参数。目测服务器是依据这个p值来选择传送的数据。
json格式检测:http://www.bejson.com/