- 待整理
- 字典
- 定义 Dictionary<string, string> openWith = new Dictionary<string, string>();
- 添加元素 openWith.Add("dib", "paint.exe");
- 取值 Console.WriteLine("For key = \"rtf\", value = {0}.", openWith["rtf"]);
- 更改值 openWith["rtf"] = "winword.exe";
- 遍历key foreach (string key in openWith.Keys)
- 遍历value foreach (string value in openWith.Values)
- 遍历字典 foreach (KeyValuePair<string, string> kvp in openWith)
- 添加存在的元素 catch (ArgumentException)
- 删除元素 openWith.Remove("doc");
- 判断键存在 if (openWith.ContainsKey("bmp")) // True
-

- 数组
- 1、数组[]特定类型、固定长度 string[] str1 = new string[3];
- 2.二维数组 int[,] intArray = new int[2, 3];
- 3多维数组 int[, ,] intArray1 = new int[,,]
- 4. 交错数组即数组的数组 int[][] intArray2 = new int[4][];intArray2[1] = new int[] { 2, 22 };
- 常用:
- Length属性:所有维数中元素的总和
- Rank属性:表示数组中的维数
- Sort方法:对一维数组排序,Array类的静态方法 Array.Sort(name);
- Reverse方法:反转一维数组 Array.Reverse(name);
- List
- 创建
- var intlist1 = new List<string>();
- var intlist2 = new List<int>(){1,2,3};//创建了一个列表,里面的初始值有三个分别为 1 2 3
- 添加元素
- mList.Add("John");
- string[] temArr = {"Ha","Hunter","Tom","Lily","Jay","Jim","Kuku","Locu"};mList.AddRange(temArr)
- Insert(intindex, T item); //在index位置添加一个元素
- 删除元素
- List. Remove(T item)
- List. RemoveAt(intindex); //删除下标为index的元素
- List. RemoveRange(intindex,intcount); //从下标index开始,删除count个元素
- mList.Contains("Hunter")
- List.Sort()
- 给List里面元素顺序反转:List.Reverse ()
- List清空 : List.Clear()
- 获得List中元素数目:List.Count() //返回int值
- if (coverWnds.Exists(p=>p.Index == strartNum))
- add.Find(delegate(stup) { return p.Name == "abc" && p.age==15; });//使用委托
- FindLastIndex、FindIndex、FindAll、Find
- 两个列表合并
- listA.AddRange(listB );//把集合A.B合并
- List<int> Result = listA.Union(listB).ToList<int>(); //剔除重复项
- List<int> Result = listA.Concat(listB).ToList<int>(); //保留重复项
- listA.BinarySearch("1");//判断集合中是否包含某个值.如果包含则返回0
- 创建
- 元组
- 创建
- var ValueTuple = (1, 2); // 使用语法糖创建元组 ValueTuple
- var tuple1 = new Tuple<int,int>(1,2);
- var named = (first: 1, second: 2);
- 取值
- var u = unnamed.Item1;//1
- var o = named.first;//1
- 作为返回值
- return new Tuple<int, int>(i, j);
- 创建
- String类型转换成int
- (1) int.TryParse(string);
- (2) Convert.Toint32(string);
- (3) (int)string;
- 文件读写
- (一) 读取文件
- 如果你要读取的文件内容不是很多,可以使用 File.ReadAllText(FilePath) 或指定编码方式 File.ReadAllText(FilePath, Encoding)的方法。

- 当文本的内容比较大时,我们就不要将文本内容一次读完,而应该采用流(Stream)的方式来读取内容。.Net为我们封装了StreamReader类。初始化StreamReader类有很多种方式。下面我罗列出几种

- 假如我们需要一行一行的读,将整个文本文件读完,下面看一个完整的例子:

- 如果你要读取的文件内容不是很多,可以使用 File.ReadAllText(FilePath) 或指定编码方式 File.ReadAllText(FilePath, Encoding)的方法。
- (二) 写入文件
- 写文件和读文件一样,如果你要写入的内容不是很多,可以使用File.WriteAllText方法来一次将内容全部写如文件。如果你要将一个字符串的内容写入文件,可以用File.WriteAllText(FilePath) 或指定编码方式 File.WriteAllText(FilePath, Encoding)方法。

- 当要写入的内容比较多时,同样也要使用流(Stream)的方式写入。.Net封装的类是StreamWriter。初始化StreamWriter类同样有很多方式:

- 同样,StreamWriter对象使用完后,不要忘记关闭。sw.Close(); 最后来看一个完整的使用StreamWriter一次写入一行的例子:
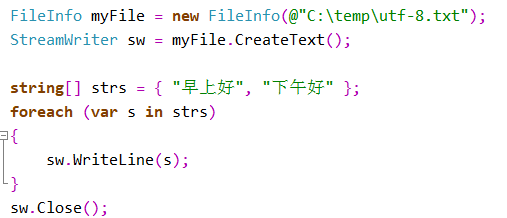
- 写文件和读文件一样,如果你要写入的内容不是很多,可以使用File.WriteAllText方法来一次将内容全部写如文件。如果你要将一个字符串的内容写入文件,可以用File.WriteAllText(FilePath) 或指定编码方式 File.WriteAllText(FilePath, Encoding)方法。
- FileStream

- 随机文件读写
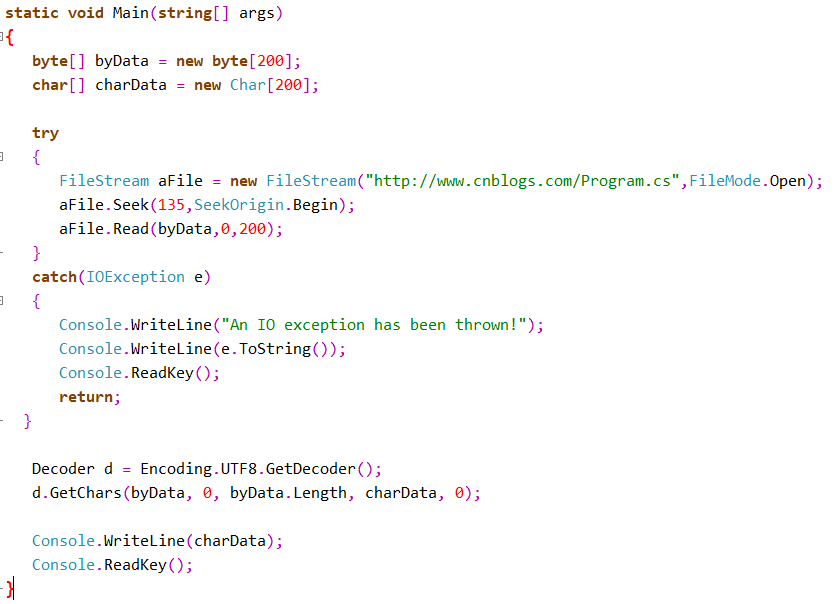
- 随机文件读写
- (一) 读取文件
- 格式化输出
-
- foreach(var xx in xxs)
尤其用于字典 和Linq查询结果的遍历. - if(int .TryParse("9",out y))
- 属性Property和字段Field
- 比较
- 字段(成员变量)
- a.字段主要是为类的内部做数据交互使用,字段一般是private。
- b.字段可读可写。
- c.当字段需要为外部提供数据的时候,请将字段封装为属性,而不是使用公有字段(public修饰符),这是面向对象思想所提倡的。
- 属性(方法)
- a.属性一般是向外提供数据,主要用来描述对象的静态特征,所以,属性一般是public。
- b.属性具备get和set方法,可以在方法里加入逻辑处理数据,灵活拓展使用。
- 字段(成员变量)
- 语法糖 自动属性
p.Name="小王";//为姓名属性赋值。 -
- 比较
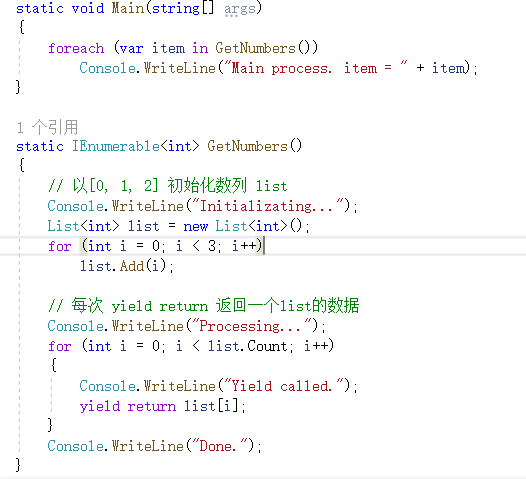
- yield return
- 作用 : 在 return 时,保存当前函数的状态,下次调用时继续从当前位置处理。
- 代码:
- 反面范例

- 使用方法解析:这个函数在处理循环时可以每生成一个数据就返回一个数据让主函数进行处理。在单线程的程序中,由于不需要等所有数据都处理好再返回,所以可以减少对内存占用。比如说有3个数据,如果一次性处理好返回,需要占用3个内存单位,而一个个返回,只需要占用1个内存单位。在多线程的处理程序中,还可以加快程序的处理速度。当数据处理以后,主程序可以进行处理,而被调用函数可以继续处理一下个数据。一个经典的应用是Socket,主线程处理对Socket接收到的数据进行处理,而另外一个线程负责读取Socket的内容。当接收的数据量比较大时,两个线程可以加快处理速度。
- 类和结构体的区别
- ① 语法上的区别在于,定义类要使用关键词class,而定义结构体则使用关键词struct。
- ② 结构体中不可对声明字段进行初始化,但类可以。
- ③ 如果没有为类显式地定义构造函数,c#编译器会自动生成一个无参数的实例构造函数,称之为隐式构造函数;
- 与此不同的是,在结构体中,无论你是否显式地定义了构造函数,隐式构造函数都是一直存在的。
- ④ 结构体中不能显式地定义无参数的构造函数,这也说明无参构造函数是一直存在的,所以不能在显式地为结
- 构体添加一个无参的构造函数;而类中则可以显式地定义一个无参数的构造函数。
- ⑤ 在结构体的构造函数中,必须要为结构体中的所有字段赋值。
- ⑥ 创建结构体对象可以不使用new关键字,但此时结构体对象中的字段是没有初始化值的,而类必须适应new关键词来创建对象。
- ⑦ 结构体不能继承结构或者类,但可以实现接口;而类可以继承类但不能继承结构,它也可以实现接口。
- ⑧ 类是引用类型,而结构体是值类型。
- ⑨ 结构体不能定义析构函数,而类可以有析构函数。
- ⑩ 不能用abstract和sealed关键字修饰结构体,而类可以。
- foreach迭代器
-

-

- 泛型

-
- IComparable接口、IComparer接口和CompareTo(Object x)方法、Compare()方法
list内元素的排序,我们一般使用 实现IComparable接口或者IComparer接口的方式来进行排序-
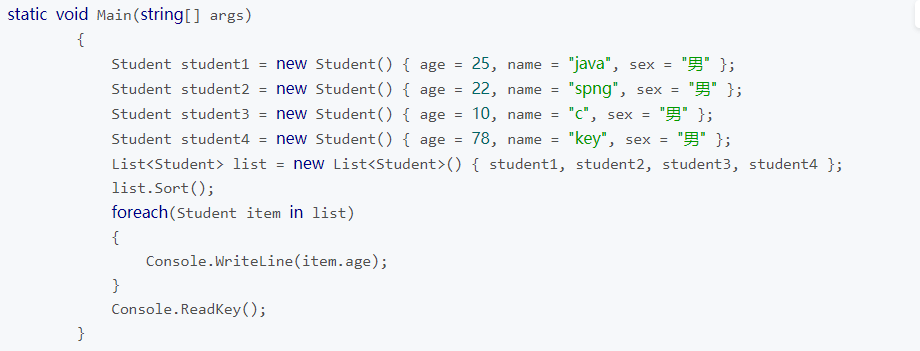
- 1.IComparable接口
- 排序的条件只有一个时我使用IComparable接口进行排序
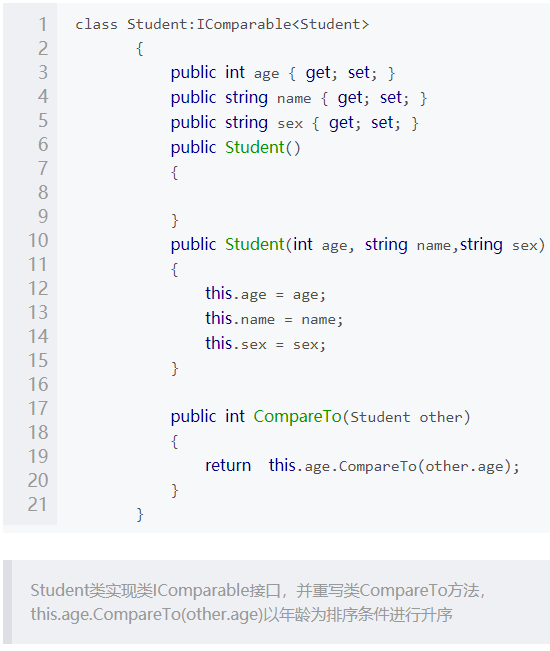
- 排序的条件只有一个时我使用IComparable接口进行排序
- 2.IComparer接口
- list.Sort(new AgeASC());
-

-
- 反射
- 0.获取Type

- 1.如何从一个字符串实例化一个类
- Type type = Type.GetType("Person",true);
- Person p = (Person)System.Activator.CreateInstance(type);
使用Activator.CreateInstance(类型,构造函数对应个数的值);\用重载,其中一个重载,可以在t后面加上true,false(选择是否只调用公共的构造函数)---true为可以调用private
- 2.如何通过一个字符串调用某个对象的某个方法
-
- 3.通过属性名称字符串获取某个对象的字段值
-
- 0.获取Type
- 方法签名
- 通过指定方法的访问级别(例如 public 或private)、可选修饰符(例如abstract 或sealed)、返回值、名称和任何方法参数,可以在类或 结构中声明方法。这些部分统称为方法的“签名”。
- 为进行方法重载,方法的返回类型不是方法签名的一部分。
- 但是,在确定委托和委托所指向方法之间的兼容性时,返回类型是方法签名的一部分。
- 委托是一种定义方法签名的类型。
- 集合类的声明和初始化

- using 释放资源

- var 类型推断

- 单问号和双问号的使用

- 两个问号表示左边的变量如果为 null 则值为右边的变量,否则就是左边的变量值,如:

- 两个问号表示左边的变量如果为 null 则值为右边的变量,否则就是左边的变量值,如:
- 类型实例化

- 扩展方法

- 匿名类

- Dynamic 相当于object
Dynamic被编译后,实际是一个object类型,只不过编译器会对dynamic类型进行特殊处理,让它在编译期间不进行任何的类型检查,而是将类型检查放到了运行期- 定义数据

- 使用

- if (d is int)
- d = (dynamic)i;
- d = i as dynamic;
- int i = d1;
- 定义数据
- Attribute
- 特性(Attribute)是用于在运行时传递程序中各种元素(比如类、方法、结构、枚举、组件等)的行为信息的声明性标签。您可以通过使用特性向程序添加声明性信息。一个声明性标签是通过放置在它所应用的元素前面的方括号([ ])来描述的。
- 特性(Attribute)用于添加元数据,如编译器指令和注释、描述、方法、类等其他信息。.Net 框架提供了两种类型的特性:预定义特性和自定义特性。
- [Obsolete("Don't use OldMethod, use NewMethod instead", true)]
- 这个预定义特性标记了不应被使用的程序实体。它可以让您通知编译器丢弃某个特定的目标元素。例如,当一个新方法被用在一个类中,但是您仍然想要保持类中的旧方法,您可以通过显示一个应该使用新方法,而不是旧方法的消息,来把它标记为 obsolete(过时的)。
- [Conditional("DEBUG")]
- 这个预定义特性标记了一个条件方法,其执行依赖于指定的预处理标识符。 它会引起方法调用的条件编译,取决于指定的值,比如 Debug 或 Trace。例如,当调试代码时显示变量的值。
- [AttributeUsage(AttributeTargets.Class | AttributeTargets.Constructor | AttributeTargets.Field | AttributeTargets.Method | AttributeTargets.Property, AllowMultiple = true)]
- 预定义特性 AttributeUsage 描述了如何使用一个自定义特性类。它规定了特性可应用到的项目的类型。
- 装箱与拆箱
- 装箱 就是把“值类型”转换成“引用类型”(Object);
- 为何需要装箱?
- 类型不确定时,或者可以传入任意类型时。
- 调用一个含类型为Object的参数的方法,该Object可支持任意为型,以便通用。
- 一个非泛型的容器,将元素类型定义为Object,以便通用。
- 拆箱 就是把“引用类型”转换成“值类型”;
- 举例

- 装箱 就是把“值类型”转换成“引用类型”(Object);
- 字典
- class 4
- 正则表达式
- 经常使用的类
- Regex类,这是一个作用于匹配的类,用来定义一个匹配对象,即以何种规则进行匹配。
- Match()方法:匹配出符合匹配要求的第一个结果,并返回一个Match匹配结果对象。
- Matches()方法:匹配出符合匹配要求的所有结果,形成一个结果集,并返回一个MatchCollection匹配结果集对象
- IsMatch()方法:进行匹配并返回一个布尔型代表是否有匹配的结果,有则返回true,无则返回false。
- 以上三个方法的参数都是要被匹配的字符串,也可以是两个参数,两个参数的第一个参数依然是要匹配的字符串,第二个参数是匹配选项。(匹配选项是一个枚举型,指定是否区分大小写等。下面例举一下匹配的选项。)
- 注意:以上方法都有对应的静态方法,静态方法在这里就只说一个小例子,因为静态方法和动态的方法差不多,只是静态方法是将要匹配的字符串作为第一个参数传入,第二个参数传入参与匹配的正则表达式,第三个是可选参数,指定匹配模式。

- RegexOptions选项的枚举的常用值:
- RegexOptions.IgnorePatternWhitespace:消除匹配正则中的所有非转义空白。
- RegexOptions.IgnoreCase:指定该正则表达式不区分大小写。
- RegexOptions.Multiline:多行模式,使用该模式会改变^和$的含义,^和$将不再是匹配字符串的开头和结尾,而是匹配每行的开头和结尾,系统默认的是单行模式。
- RegexOptions.RightToLeft:匹配从右到左进行,而不是从左到右进行。
- Split()方法:匹配出对应的字符串,并用这些字符串进行分割,返回的是一个string类型的数组。

- Replace()方法:用指定的字符串替换字符串中符合匹配规则的子串,返回替换后的新字符串。

- MatchCollection,这是一个作用于匹配结果集的类,因为既然涉及到匹配那么就可能会匹配出多个结果,这多个结果就可以赋值给匹配结果集(MatchCollection)的对象。
- 对于MatchCollection类的常用属性和方法我们经常用到的只有Count属性。返回MatchCollection集合的Match对象个数,该属性常用于查询符合要求的匹配的个数。
- Match,这是一个匹配结果的类,多个匹配结果(Match)组成一个匹配结果集(MatchCollection)。
- 常用属性:
- Value属性:匹配的的值。前面我们用Console.WriteLine(match);语句输出的其实都是Value属性的值。语句Console.WriteLine(match)等价于Console.WriteLine(match.Value)。
- Groups属性:该属性是一个string类型的集合,保存匹配时候用小括号匹配的内容,用小括号匹配的内容用分组的形式储存在了对应Match对象的Groups属性中作为一个元素储存了。我们可以通过Match对象.Groups[下标]的形式访问分组的数据。
- Length属性:该属性对应匹配到的子串的长度。
- 常用方法:
- Match类对象的常用方法只有一个:
- NextMatch()方法。用来从前面的匹配的位置进行下一个匹配。
- 常用属性:
- Regex类,这是一个作用于匹配的类,用来定义一个匹配对象,即以何种规则进行匹配。
- 举例

- 正则表达式的匹配规则
- 1,正则表达式的通配符。
- 1)"\d"这个符号代表从0-9的数字字符。
- (2)"\w"代表所有单词字符,包括:大小写字母a-z、数字0-9、汉字(其实我认为是各国文字字符都可以但是身为中国人应该只用到了汉字)、下划线。
- (3)"\s"代表任何空白字符,所谓空白字符就是打出来是空白的字符,包括:空格、制表符、换页符、换行符、回车符等等。
- (4)"\D"代表任何非数字字符。
- (5)"\W"代表任何非单词字符。
- (6)"\S"代表任何非空白字符。
- (7)"."代表除换行符(\n)之外的任何字符。
- 注意
- 第一:通配符"."因为代表除\n之外的所有字符,所以我们在匹配的时候如果要匹配到"."就应该用"\."代替,如上面我们匹配邮箱的案例,因为每个邮箱格式肯定是"[email protected]"里面有一个点,这个点我就用"\."代替了,而不是直接用"."。
- 第二:既然我们所用的通配符都有"\"那么在定义正则规则的时候我们肯定要在正则规则字符串前面加@,以表示所有的\都不转义。
- 第三:正则表达式学起来非常容易,但是无论是几年的程序员还是新手,写正则表达式很容易出错,这些错误笔者总结很大部分来源于通配符的使用,因为通配符实在是表示的范围比较广,我们没有办法掌握,所以在实际使用过程中应该尽量减少通配符的使用而使用我下面介绍的(可选字符集)形式。
- 2,可选字符集
- 案例一:[abc],指定这个字符位可以出现a或者b或者c。
- 案例二:[123],指定这个字符位可以出现1或者2或者3。
- 案例三:[a-d],指定这个字符位可以出现a到d的任何字符之一。
- 案例四:[a-zA-Z],指定这个字符位可以出现大小写字符的a-z
- 案例五:[a-t1-7],指定这个字符位可以出现小写字母a-t,数字1-7中的任何一个字符。
- 案例六:[\w\s],指定这个字符位可以出现任何单字字符和任何空白字符之一。
- 备注:所以所谓的可选字符集就是指定一个字符位可以出现哪个字符。
- 3,反向字符集
- 案例一:[^a],指定这个字符位可以出现除a之外的任何字符,注意是任何字符,不止是b-z。
- 案例二:[^abc],指定这个字符位可以出现除小写字母abc之外的任何字符之一。
- 案例三:[^0-9],指定这个字符位可以出现除0到9之外的任何字符之一。
- 案例四:[^#],指定这个字符位可以出现除井号之外的任何字符之一。
- 案例五:[^\w],指定这个字符位可以出现除单词字符之外的任何字符之一。
- 4,“或”匹配
或匹配用来匹配可以出现的某个字符串子串。- 案例一:thanyou|thankher,这个指定匹配出thankyou或者thankher。
- 案例二:(b|tr)ee,这个指定匹配出bee或者tree。
- 案例三:th(i|a)nk,这个指定匹配出thank或者think。
- 案例四:book one|two,这个指定匹配出,book one或者two。注意不是book one或者book two。
- 案例五:book (one|two),这个指定匹配出book one或者book two。
- 5,限定符
限定符用来限定字符(串)出现的次数。- "*"限定符:将前面的(一个字符)字符重复零次到多次。
注意是一个字符:如我们用ds*对字符串进行匹配,匹配的是d后面跟0到n个s,而不是0到n个ds。 - "+"限定符:将前面的(一个字符)字符重复一次到多次。
注意:与*唯一的区别就是重复至少一次。 - "?"限定符:将前面的(一个字符)重复零次到一次。
- "{n}"限定符:将前面的字符重复n次。
- "{n,}"限定符:将前面的字符重复至少n次。
- "{n,m}"限定符:将前面的字符重复n到m次。
- 补充
- 限定符的懒惰修饰符,以上的限定符默认都是重复尽量多,而在以上的符号后面加"?"就重复尽量少。
- 如:"*?"就是将前面的字符尽量少重复。
- 案例一:我们用"5*?"去匹配字符串"25255255525555"匹配出来的结果是:空,因为*后面加了?,这样的匹配规则就是匹配5零次到多次尽量少重复,这样他当然就优先匹配出现零次,这样匹配出来的结果全部是""。
- 案例二:我们用"5*"去匹配字符串"25255255525555"的话匹配出来的结果不是这样了,因为默认是尽量多重复,所以匹配出来的结果是:
- 25、255、2555、25555。
- "*"限定符:将前面的(一个字符)字符重复零次到多次。
- 6,定位符
定位符用来在正则规则中确定匹配对应的字符串的位置。- "^"定位符,^在定位符中代表匹配字符串的开头位置,注意是开头位置,不是字符串的第一个字符,可以理解为字符串第一个位置之前的小空隙。
- "$"定位符,$定位符代表匹配字符串的末尾位置,可以理解为字符串最后一个字符末尾的空隙。
- "\b"定位符,匹配单词的边界位置,也是空隙位置,单词的空隙位置可以是:空格,逗号,句号,开头,末尾,"-"等等。
- 我们要匹配某个字符串开头的四个字符组成的子串
Regex regex=new Regex(@"^\w{4}");
- 7,分组的概念
- 在匹配邮箱的时候我们也可以使用分组的概念,比如,我们要一次将邮箱全址、邮箱用户名都匹配出来,就可以用到分组的概念。
- 此时匹配的正则表达式为:@"([a-zA-Z0-9_]+)@([a-zA-Z0-9])+\.com"。
- 这个正则表达式我们用到了两个括号,这两个括号就是分组,将正则表达式分成了三组,第0组是整个匹配结果,第1组是第一个括号里面的内容,第二组是第二个括号里面的内容,显而易见,第一个括号里面的内容是用户名(即邮箱地址的@前面的字符串是用户名)。
- 这样在匹配结果集的每个结果中都有可以通过访问这些分组来访问里面的数据,通过结果Match对象的Groups属性进行访问。
-

- 8,非捕获分组
- "?:"此符号放在括号中代表非捕获分组,意思是指定的括号不进行分组功能。
- 比如在上面的匹配邮箱地址和邮箱用户名的例子中我们希望括号里面不匹配到用户名的话正则表达式就可以这样改:
- 正则表达式:@"(?:[a-zA-Z0-9_]+)@(?:[a-zA-Z0-9])+\.com
- 9,"正向预查"和"负正向预查"
- "?="正向预查:字符串后面的字符(串)进行限定。指定能够出现的字符(串)。
- "?!"负正向预查:对字符串后面的字符(串)进行限定,指定不能够出现的字符(串)。
- 在实际开发中比如我们有这样的需求:在信息字符串"张三 性别:男 电话号码:13699866695 李四 性别:女 电话号码:13522693356 王五 性别:男 电话号码:13859596459"中匹配出所有男性的姓名。

- 根据上面的例子不难理解正向预查的概念,那么负正向预查也就自然而然的了解了,负正向预查就是限定匹配结果后面不能出现的字符串。
- 10,"反向预查"和"负反向预查"
- "?<="反向预查,限定匹配结果之前的字符串,(指定匹配结果之前的字符串必须是哪些)。
- "?<!"负反像预查,限定匹配结果之前的字符串,(指定匹配结果之前的字符串必须不是哪些)。
- 上面的需求如果我们进行修改,修改成匹配出所有性别为男的人的电话号码,正向预查就解决不了这个问题了,因为正向预查是对匹配内容之后的内容进行限定,而我们要对匹配结果之前的内容进行限定的话就不行了。此时我们就需要用到反向预查的概念。
- Regex regex=new Regex(@"(?<=性别:男\s+\b\w+\b:)\b\w+\b");
- 1,正则表达式的通配符。
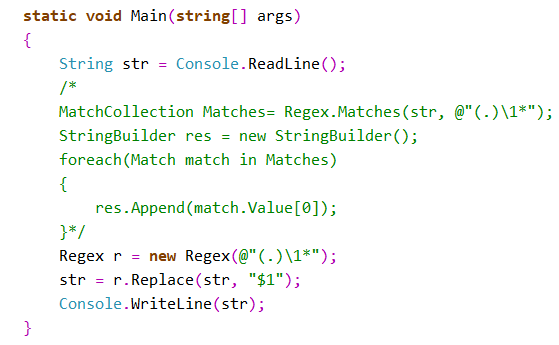
- (.)/1+ replaced by $1
去重
- 经常使用的类
- lambda
- delegate
- 定义 delegate void MyDelegate(string str,int index);
- 实例化MyDelegate md = new MyDelegate(Show);
- 多播代理

- 预置
- Func
- Func至少0个参数,至多16个参数,根据返回值泛型返回。必须有返回值,不可void
- Action
- Action至少0个参数,至多16个参数,无返回值。
- Predict
- Predicate有且只有一个参数,返回值固定为bool
- Point first = Array.Find(points, ProductGT10);
- var result = Array.FindAll(points, predicate);
- StrList.Find , StrList.FindAll , StrList.Exists , StrList.FindLast , StrList.FindIndex
- Func
- Event
- 定义 public event CryHandler DuckCryEvent;
- 事件订阅DuckCryEvent +=new CryHandler(Cry);
- 正则表达式
- class 5
- Linq
语句模式 /方法模式- from n in xx where

- 函数计算

- 排序

- Top(1)

- 跳过前面多少条数据取余下的数据

.Skip(10).Take(10) 分页数据查询 - distinct()
- list.distinct()比较的是getHash()方法
- var distinctProduct = allProduct.Distinct(new ProductIdComparer());

-

-

- 包含,类似like '%%'

- 9.分组group by

- sql中的In

- 内连接 INNER JOIN

- 左连接 LEFT JOIN
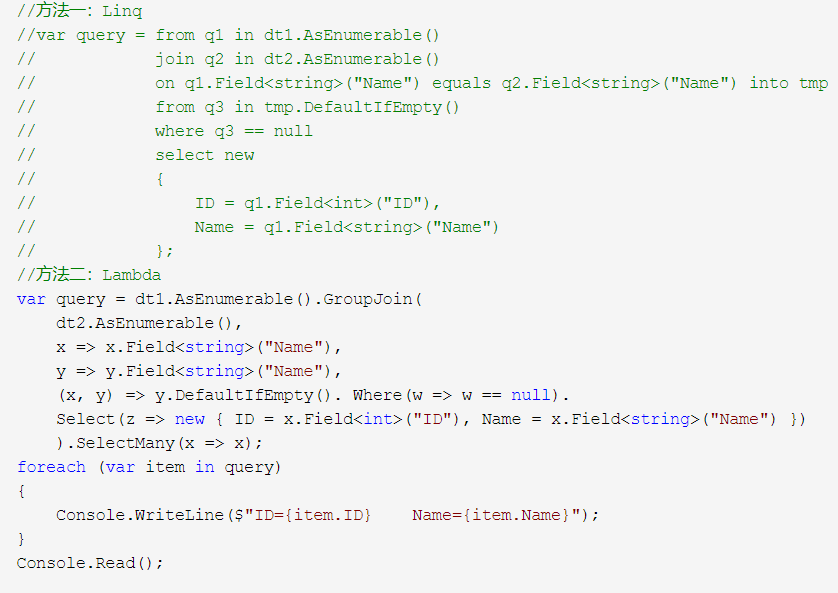
- 尽量用方法而不是语句

- from n in xx where
- Linq
- class 6
- 高级类型
- var=>关键字 类型推导
- dynamic =>动态类型,一种数据类型
- tuple 元组
- 多线程
- Thread
- 创建线程
- 1.Thread类

Thread thread2 = new Thread(new Program().myThreadMethod); Thread thread3 = new Thread(delegate() { Console.WriteLine("匿名委托"); }); Thread thread4 = new Thread(( ) => { Console.WriteLine("Lambda表达式"); }); 为了区分不同的线程,还可以为Thread类的Name属性赋值,代码如下:Thread thread5 = new Thread(()=>{ Console.WriteLine(Thread.CurrentThread.Name); }); thread5.Name = "我的Lamdba"; - 传递参数
thread.Start("通过委托的参数传值"); 要注意的是,如果使用的是不带参数的委托,不能使用带参数的Start方法运行线程,否则系统会抛出异常。但使用带参数的委托,可以使用thread.Start()来运行线程,这时所传递的参数值为null。
- 1.Thread类
- 常用函数
- Thread.Sleep(2000);
- Thread.CurrentThread.ManagedThreadId.ToString()
- 线程同步

- 前台线程:主程序必须等待线程执行完毕后才可退出程序。Thread默认为前台线程,也可以设置为后台线程
- 阻塞主线程
- 创建线程
- 线程池ThreadPool
当处理单个任务时间较短或者需要处理的任务数量比较大的时候要考虑使用线程池- 可以看到,上段代码没有显式创建线程,而是把方法放到了ThreadPool.QueueUserWorkItem()方法中,ThreadPool负责创建和管理线程。当程序刚开始时,ThreadPool第一次被调用,这时线程池里一个线程没有,线程池会创建一个新线程,当程序再次调用线程池时,若线程池忠还有空闲线程,则直接调用空闲线程执行程序;若程序调用线程池时,线程池中没有空闲线程且CPU处于“未饱和”状态,则线程池会创建新线程。实际上,当调用线程池时,相当于把要执行的方法“挂”在线程池的任务队列上,当CPU处于“未饱和”状态,线程池就会调用线程来执行线程池任务队列中的任务。

- 可以看到,上段代码没有显式创建线程,而是把方法放到了ThreadPool.QueueUserWorkItem()方法中,ThreadPool负责创建和管理线程。当程序刚开始时,ThreadPool第一次被调用,这时线程池里一个线程没有,线程池会创建一个新线程,当程序再次调用线程池时,若线程池忠还有空闲线程,则直接调用空闲线程执行程序;若程序调用线程池时,线程池中没有空闲线程且CPU处于“未饱和”状态,则线程池会创建新线程。实际上,当调用线程池时,相当于把要执行的方法“挂”在线程池的任务队列上,当CPU处于“未饱和”状态,线程池就会调用线程来执行线程池任务队列中的任务。
- Task
- 都是后台线程,后台线程:主程序执行完毕后就退出,不管线程是否执行完毕。ThreadPool默认为后台线程
- 线程号可能是一样的,会回收,实际上内部维护了一个线程池
- Task参数
- Task<Int32> task = Task.Run(() => fun("s", 9));
- Task的返回值
- Task<int> t=xxx;t.Reslut
- task对于有返回值的工作函数可以通过访问其Result函数来实现阻塞等待。
- Task有参数有返回值
-
- Task三种创建方式
- Task t2 = new Task(() => {Console.WriteLine("开启一个新任务");});t2.Start();
- Task t = Task.Factory.StartNew(() => {Console.WriteLine("任务已启动....");});
- Task.run(() => {Console.WriteLine("任务已启动....");})
- Run(Action)
- 三种创建方式的区别
- 首先我们说Task.Run和StartNew的区别:
- 1、Task.Run它是将在线程池上运行的指定工作排队,它默认的任务计划(TaskScheduler)是线程池,并且不允许修改任务计划。而StartNew是可以指定任务计划的。
- 2、Run是TaskFactory.StartNew的轻量级实现。Run方法是启动计算密集型任务的建议的方法,StartNew方法仅在需要精细地控制长时间运行的计算密集型任务时使用,这一点应该是这两者最重要的区别了。
- 3、Run方法无法为委托传递输入参数,而StartNew可以。
- 再说一下Run和Start的区别:
- 1、start的重载函数只有2个,一个是在当前的任务计划中执行,一个是指定计划任务执行。其他的参数在Task的构造函数中设置。这个当前的任务计划指的是当前上下文所在的任务计划。
- 2、Start任务可以启动和仅运行一次。 第二次计划的任务的任何尝试都将导致异常。
- 3、Run是一个静态方法,Start是一个实例方法。
- 综上所述,微软推荐的创建线程的方法是Run方法,但是我们需要根据自己的需求选择合适的方法。
- 首先我们说Task.Run和StartNew的区别:
- the parameters and meaning of the factory method
- Action,Func等参数与Run()相似,只是在重载函数里增加了一个TaskCreationOptions 枚举参数,指定可控制任务的创建和执行的可选行为的标志。
- 常用:LongRunning,指定任务将是长时间运行的、粗粒度的操作,涉及比细化的系统更少、更大的组件
- Task的常用方法
- t.wait()
- Task.WaitAll(t1,t2)
- Task.WaitAny()
- t1.ContinueWith(t2)
- 返回值:Task<TResult>,可以通过多种方式创建实例。 最常见的方法是调用静态Task.Run<TResult>(Func<TResult>)或Task.Run<TResult>(Func<TResult>, CancellationToken)方法
- Task<int>.Factory.StartNew(() => negate(6)).ContinueWith(antecendent => action("x")) .ContinueWith(antecendent => negate(7)) .Wait();
- 三者区别
- 首先说Thread、ThreadPool
- 前台线程:主程序必须等待线程执行完毕后才可退出程序。Thread默认为前台线程,也可以设置为后台线程
- 后台线程:主程序执行完毕后就退出,不管线程是否执行完毕。ThreadPool默认为后台线程
Net环境使用Thread建立的线程默认情况下是前台线程,即线程属性IsBackground=false,在进程中,只要有一个前台线程未退出,进程就不会终止。主线程就是一个前台线程。而后台线程不管线程是否结束,只要所有的前台线程都退出(包括正常退出和异常退出)后,进程就会自动终止。 - 线程消耗:开启一个新线程,线程不做任何操作,都要消耗1M左右的内存
- ThreadPool为线程池,其目的就是为了减少开启新线程的消耗(使用线程池中的空闲线程,不必再开启新线程),以及统一管理线程(线程池中的线程执行完毕后,回归到线程池中,等待新任务)
- 总结:ThreadPool性能会好于Thread,但是ThreadPool与Thread对线程的控制都不是很够,例如线程等待(线程执行一段时间无响应后,直接停止线程,释放资源,两者都没有直接的API,只能通过硬编码实现)。同时ThreadPool使用的是线程池全局队列,全局队列中的线程,依旧会存在竞争共享资源的情况,从而影响性能。
- 下面说Task
- Task背后的实现,也是使用的是线程池线程。但是它的性能优于ThreadPool,因为它使用的不是线程池的全局队列,而是使用的是本地队列。是的线程之间竞争资源的情况减少。
- Task提供了丰富的API,开发者可对Task进行多种管理,控制。
- 首先说Thread、ThreadPool
- 同步和互斥
- Thread
- 泛型
- async/await
异步方法:一个程序调用某个方法,在处理完成之前就返回该方法。通过 async/await 我们就可以实现这种类型的方法。- 用法:
- Async 方法有三种可能的返回类型: Task、Task<T> 和 void
- async Task MyMethodAsync() {return t;}自动封包
- async的函数本质上只是包装,与手动返回Task并没有实质区别(Task.ContinueWith(xxxx))。
- 一个返回Task<int>的函数,不只可以用来await,还有很多别的玩法,语言应该给予开发人员解开和不解开的自由
-

- await task;自动解包
- async函数用法:
- Task<T> t=asyncfun() t.Result阻塞!
- 解释
- 在await之前,都是同步执行,await开始才是异步执行,记录阻塞点1,返回async函数的调用点
- await并不创建线程,只有Task会创建线程
- await相当于await东西的回调函数
- async只是为了标记await存在,所以二者总是同步出现,单独的async不起作用
- 实例
-
- 用法:
- 高级类型
- 作业题
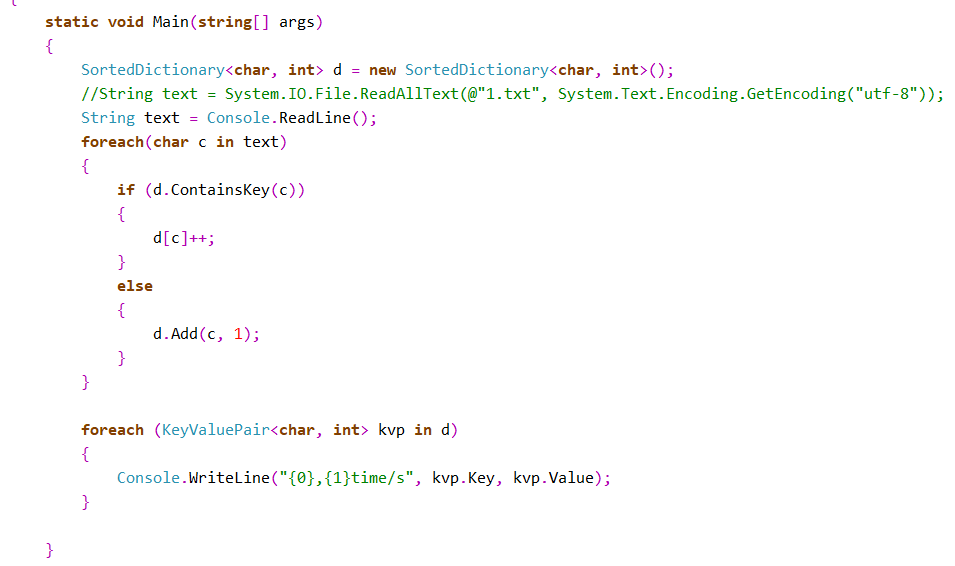
- 作业1.统计字频
- 作业2
- 最小值

- 去重
- 最小值
- 作业3 至少有一个6分
- 老师
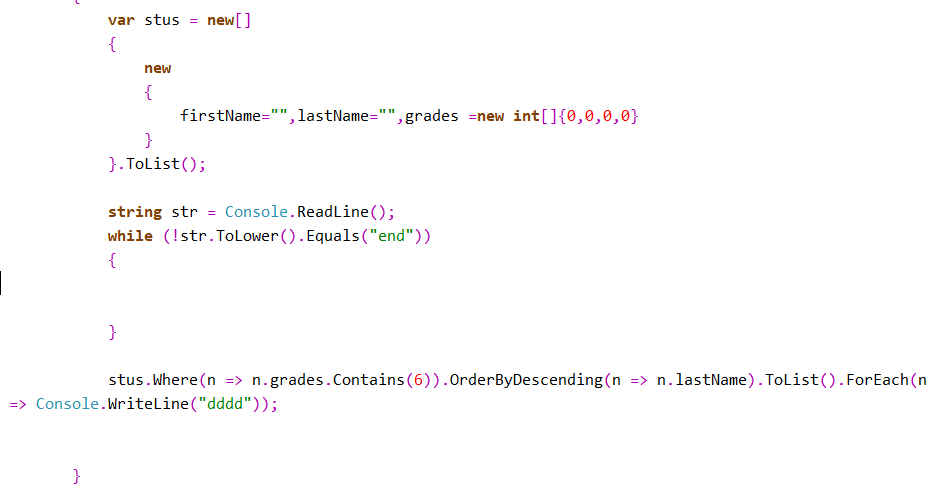
- 我

- 老师
- 作业4 三种创建Task的方式

- 作业5
- 1.类的继承、多态
-
- 2.迭代器
-
- 3.比较
-
- 1.类的继承、多态
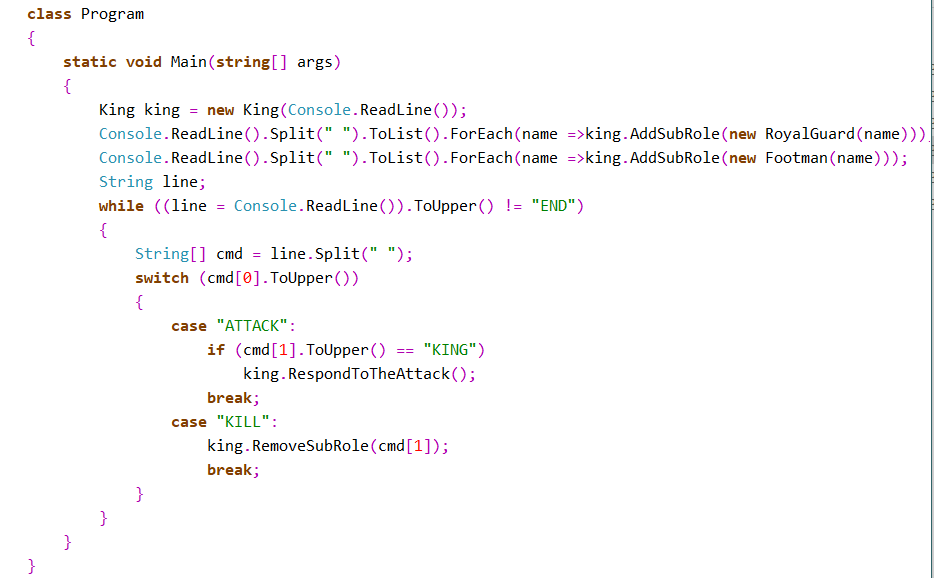
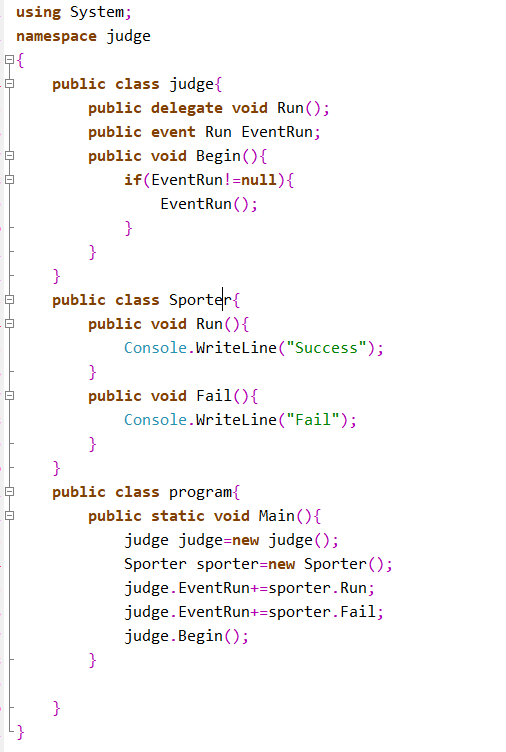
- 作业6
- 事件订阅
-
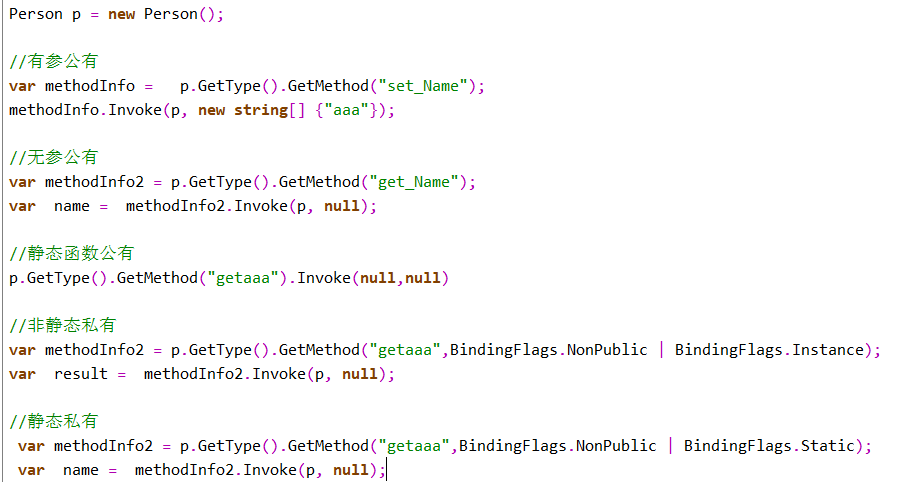
- 反射
-
- 事件订阅
- 作业1.统计字频
C# 高级特性总结
















猜你喜欢
转载自www.cnblogs.com/maxzheng/p/12081597.html
今日推荐
周排行