一、环境准备
所有规划主机(一台master,两台node)均需操作
1、关闭防火墙,selinux
[root@node1 ~]# systemctl stop firewalld [root@node1 ~]# systemctl disable firewalld [root@node1 ~]# setenforce 0 [root@node1 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
2、时间同步服务器
3、关闭swap分区(临时方案)
[root@master ~]# swapoff –a
除了关闭swap外,还可以更改kubelet配置,忽略swap
[root@master ~]# vim /etc/sysconfig/kubelet KUBELET_EXTRA_ARGS="--fail-swap-on=false"
4、host配置
节点之间可以互相解析,host文件配置。
5、ssh等效性配置
Master对node免密登录
6、加载内核模块
配置系统内核参数使流过网桥的流量也进入iptables/netfilter框架,需加载需要的内核模块。
[root@master ~]# modprobe br_netfilter [root@master ~]# modprobe ip_conntrack [root@master ~]# echo -e 'net.bridge.bridge-nf-call-iptables = 1 \nnet.bridge.bridge-nf-call-ip6tables = 1' >> /etc/sysctl.conf [root@master ~]# sysctl -p
7、Yum源配置(base,epel,k8s,docker)
[root@node1 ~]# cd /etc/yum.repos.d/ [root@node1 yum.repos.d]# mkdir bak [root@node1 yum.repos.d]# mv * bak/ [root@node1 yum.repos.d]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo [root@node1 yum.repos.d]# wget -P /etc/yum.repos.d/ http://mirrors.aliyun.com/repo/epel-7.repo [root@node1 yum.repos.d]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 EOF [root@node1 yum.repos.d]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo [root@node1 yum.repos.d]# yum clean all && yum makecache fast
二、集群创建
1、安装kubeadm及相关工具
所有节点都需要操作。
[root@master ~]# yum install docker kubectl kubeadm kubelet -y #默认安装最新版本,可指定版本(yum install docker kubectl-1.10.0 kubeadm-1.10.0 kubelet-1.10.0 -y)
启动相关进程: [root@master ~]# systemctl daemon-reload [root@master ~]# systemctl enable docker && systemctl restart docker [root@master ~]# systemctl enable kubelet
在此处不能直接启动kubelet,启动不了,会不停重启。
2、master init 集群
(不能访问国外仓库的情况下,可指定国内仓库,或在启动配置文件里修改仓库地址)
[root@master ~]# kubeadm init --kubernetes-version=v1.14.0 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --image-repository registry.aliyuncs.com/google_containers # kubeadm config images pull
# kubeadm reset
初始化失败,根据提示查找失败原因。
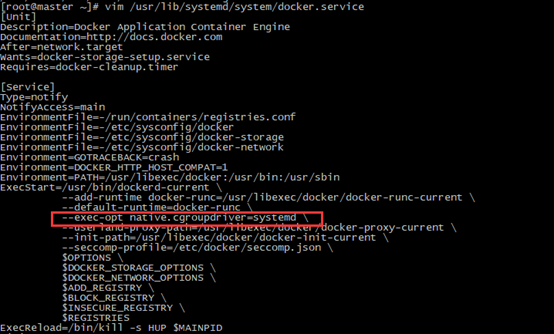
kubelet和docker 的cgroup driver 有2种方式:cgroupfs和systemd.注意保持 2个应用的driver保持一致。(如果docker是cgroupfs的,则修改kubelet :Environment="KUBELET_CGROUP_ARGS=--cgroup-driver=cgroupfs"。如果docker为systemd,则不用更改)
查看docker driver:
[root@master ~]# vim /usr/lib/systemd/system/docker.service
[root@node1 ~]# docker info

查看kubelet driver:
[root@master ~]# vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
[root@master ~]# vim /var/lib/kubelet/kubeadm-flags.env
最终成功实验: docker driver改为cgroupfs ,kubelet 为systemd,kubeadm init成功,但官方建议docker driver为systemd,是否与版本有关,存疑???

3、node 加入集群
准备工作,master节点上操作
[root@master ~]# useradd kubelet
[root@master ~]# passwd kubelet
把kubelet用户加入sudo用户组
[root@master ~]# su - kubelet
[kubelet@master ~]$ mkdir -p $HOME/.kube
[kubelet@msaster ~]$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[kubelet@master ~]$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
在node1上运行join:
[root@node1 ~]# kubeadm join 192.168.42.128:6443 --token vo63m6.gnlukzl3myf1m3v8 \
--discovery-token-ca-cert-hash sha256:5212f47a507fb30cbe8f14b35c1d92748874eda5d9ef60e38efca373a487567a

4、网络配置
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
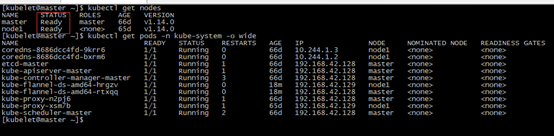
至此,k8s集群搭建成功。结果如下:
4、在已有集群中添加节点:
新节点准备,在各节点上做好主机名,hosts文件映射,ssh等效性配置,关闭swap等初始化操作,安装docker,kubelet并正常启动;
在master上打印出加入集群的命令:
[kubelet@master ~]$ kubeadm token create --print-join-command
在新节点上执行以上命令
执行加入命令时如果报错,报错内容为:error execution phase kubelet-start: error uploading crisocket: timed out waiting for the condition。进行如下操作:

[root@node2 ~]# swapoff -a [root@node2 ~]# kubeadm reset [root@node2 ~]# iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables –X [root@node2 ~]# systemctl daemon-reload [root@node2 ~]# systemctl restart kubelet
遇kubelet报错如下:Failed to get system container

问题产生原因为:kubernetes和docker版本兼容性问题。
三、遇到的问题
默认 kubeadm 创建的集群会在内部启动一个单点的 etcd,当然大部分情况下 etcd 还是很稳定的,但是一旦etcd 由于某种原因挂掉,这个问题会非常严重,会导致整个集群不可用。具体原因是 etcd 存储着 kubernetes 各种元数据信息;包括 kubectl get pod 等等基础命令实际上全部是调用 RESTful API 从 etcd 中获取的信息;所以一但 etcd 挂掉以后,基本等同于 kubectl 命令不可用,此时将变为 ‘瞎子’,集群各节点也会因无法从 etcd 获取数据而出现无法调度,最终挂掉。
此时kube-apiserver因为连接不到etcd,死活启动不起来。然后整个集群就没救了。

单独启动etcd容器也启动不起来,容器会不停的被删除重启,但就是启动不起来,使用
[root@master manifests]# docker logs -f 76797c65b499 #查看日志。


只能重建集群,之前的所有信息都没有了。
四、Tips:
更改docker仓库地址:
[root@master ~]# vim /etc/sysconfig/docker OPTIONS=' --log-driver=journald --registry-mirror=http://xxxx.mirror.aliyuncs.com
K8s和docker要版本兼容,不能直接yum,版本对照参照git文档
# yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo