这篇扫盲而已,根本没有什么高深的知识点,就像对着车讲,这车是靠发动机和轮子跑路的,至于发动机里面是不讲的。
我们前面讲过了树这种非线性表数据结构,今天我们要讲另一种非线性表数据结构,图(Graph)。和树比起来,这是一种更加复杂的非线性表结构。我们知道,树中的元素我们称为节点,图中的元素我们就叫作顶点(vertex)。从我画的图中可以看出来,图中的一个顶点可以与任意其他顶点建立连接关系。我们把这种建立的关系叫作边(edge)。
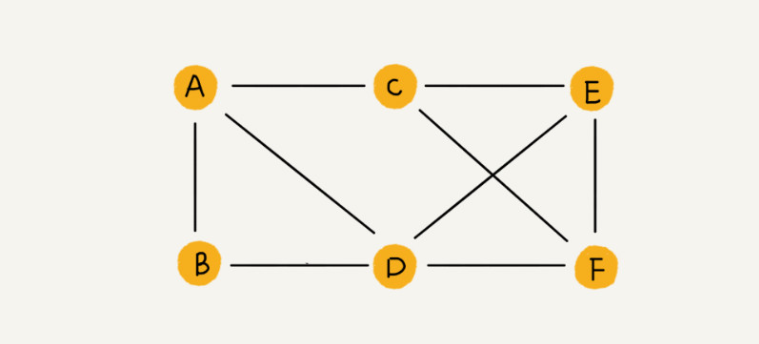
无向图,这里很像qq好友,只要加了就双方都有了。
看起来很像一个社交网,图又分为有向图,无向图,带权图,下面分别举例

如果用户 A 关注了用户 B,我们就在图中画一条从 A 到 B 的带箭头的边,来表示边的方向。如果用户 A 和用户 B 互相关注了,那我们就画一条从 A 指向 B 的边,再画一条从 B 指向 A 的边。我们把这种边有方向的图叫作“有向图”。比如微博推特等的fellow。有入度和出度一说。
QQ 中的社交关系要更复杂的一点。不知道你有没有留意过 QQ 亲密度这样一个功能。QQ 不仅记录了用户之间的好友关系,还记录了两个用户之间的亲密度,如果两个用户经常往来,那亲密度就比较高;如果不经常往来,亲密度就比较低。如何在图中记录这种好友关系的亲密度呢?这里就要用到另一种图,带权图(weighted graph)。在带权图中,每条边都有一个权重(weight),我们可以通过这个权重来表示 QQ 好友间的亲密度。
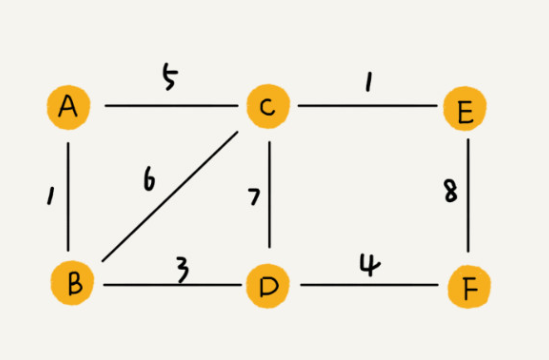
图的存储方式
1.邻接矩阵
邻接矩阵的底层依赖一个二维数组。对于无向图来说,如果顶点 i 与顶点 j 之间有边,我们就将 A[i][j] 和 A[j][i] 标记为 1;对于有向图来说,如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,那我们就将 A[i][j] 标记为 1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,我们就将 A[j][i] 标记为 1。对于带权图,数组中就存储相应的权重。
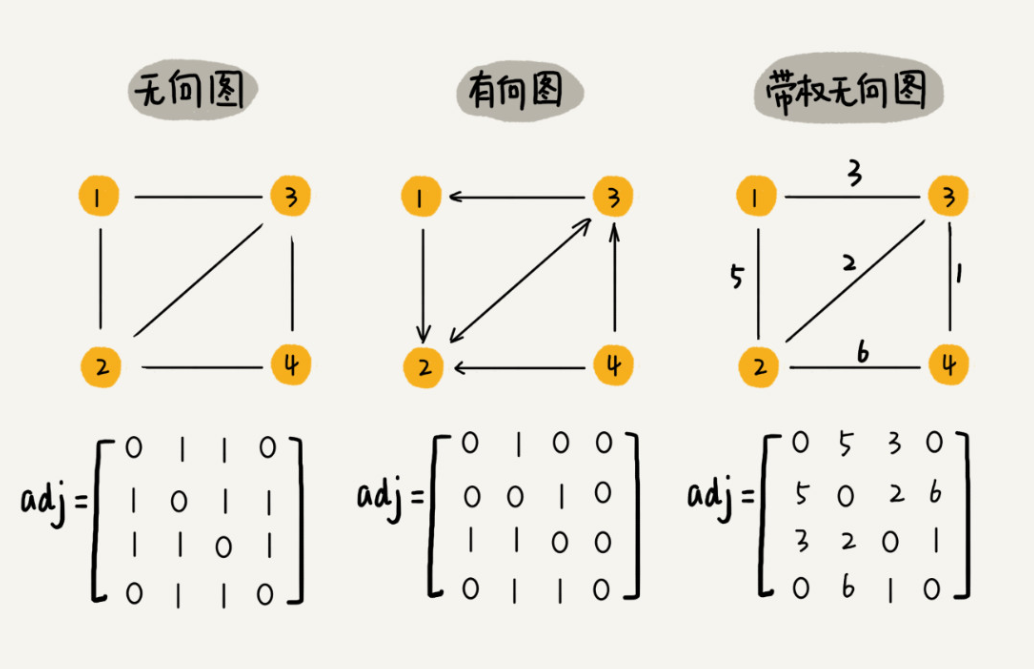
这个存储的有点就是遍历快速,缺点很明显,每个节点都要在,如果twitter有上亿用户则都需要作为度存在,但是每个用户好友肯定没那么多,所有造成了大量的空间浪费,毕竟数组开辟也是消耗性的。
还有,如果我们存储的是稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了。比如微信有好几亿的用户,对应到图上就是好几亿的顶点。但是每个用户的好友并不会很多,一般也就三五百个而已。如果我们用邻接矩阵来存储,那绝大部分的存储空间都被浪费了。
2.邻接表存储
每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。另外我需要说明一下,图中画的是一个有向图的邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。

很像散列表存储,实际上就是。根据守恒定律,这个遍历和各种操作肯定比矩阵存储慢很多。我们可以将邻接表中的链表改成平衡二叉查找树。实际开发中,我们可以选择用红黑树。这样,我们就可以更加快速地查找两个顶点之间是否存在边了。当然,这里的二叉查找树可以换成其他动态数据结构,比如跳表、散列表等。除此之外,我们还可以将链表改成有序动态数组,可以通过二分查找的方法来快速定位两个顶点之间否是存在边。
实际应用-微博用户的fellow list
1.列出需要的操作,也就是算法
判断用户 A 是否关注了用户 B;
判断用户 A 是否是用户 B 的粉丝;
用户 A 关注用户 B;
用户 A 取消关注用户 B;
根据用户名称的首字母排序,分页获取用户的粉丝列表;
根据用户名称的首字母排序,分页获取用户的关注列表。
2.确定是否为稀疏图,肯定是,所以不能用邻接矩阵,确定邻接表。
3.为了使用效率,我们需要多一个逆邻接表。
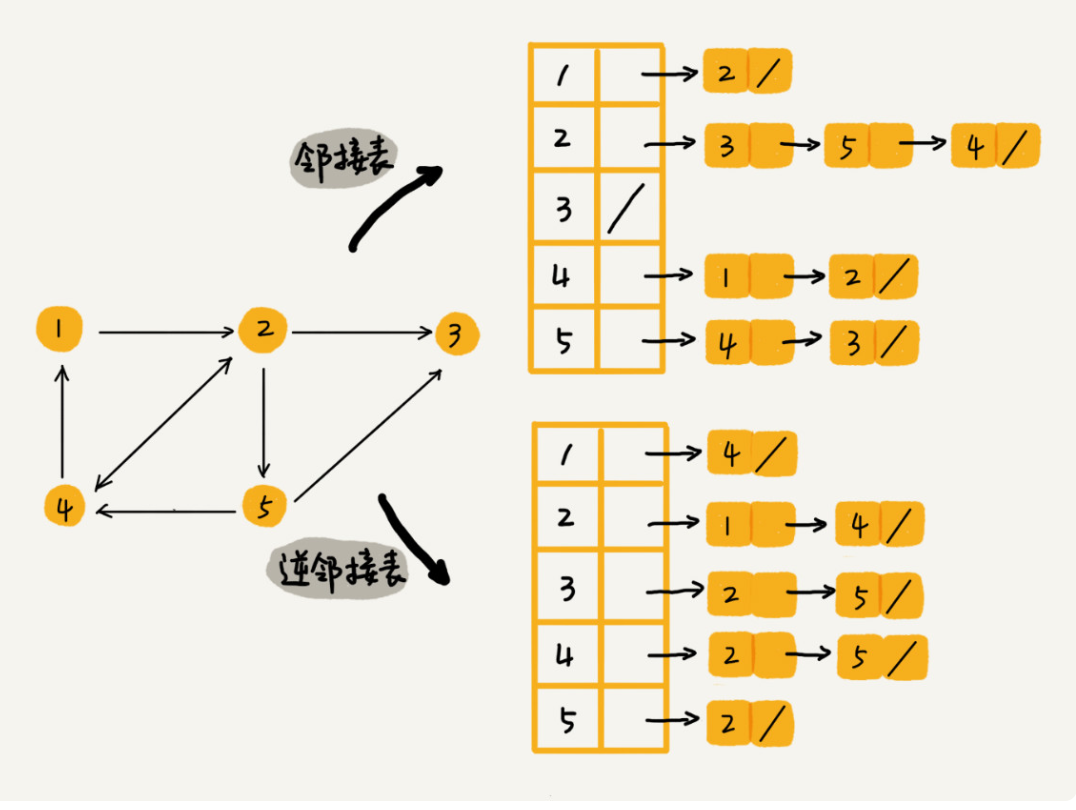
因为我们需要按照用户名称的首字母排序,分页来获取用户的粉丝列表或者关注列表,用跳表这种结构再合适不过了。这是因为,跳表插入、删除、查找都非常高效,时间复杂度是 O(logn),空间复杂度上稍高,是 O(n)。最重要的一点,跳表中存储的数据本来就是有序的了,分页获取粉丝列表或关注列表,就非常高效。
微博这种量级,不可能两个表就放到内存里,所以我们可以通过哈希算法等数据分片方式,将邻接表存储在不同的机器上。你可以看下面这幅图,我们在机器 1 上存储顶点 1,2,3 的邻接表,在机器 2 上,存储顶点 4,5 的邻接表。逆邻接表的处理方式也一样。当要查询顶点与顶点关系的时候,我们就利用同样的哈希算法,先定位顶点所在的机器,然后再在相应的机器上查找。

除此之外,我们还有另外一种解决思路,就是利用外部存储(比如硬盘),因为外部存储的存储空间要比内存会宽裕很多。数据库是我们经常用来持久化存储关系数据的,所以我这里介绍一种数据库的存储方式。我用下面这张表来存储这样一个图。为了高效地支持前面定义的操作,我们可以在表上建立多个索引,比如第一列、第二列,给这两列都建立索引。
这种问题其实可以理解为这类问题,比如商品的关联,在高并发下我们根据分析将部分放在cache级别的确能减轻db很大压力。
生活工作中应用图的例子。很多,互联网上网页之间通过超链接连接成一张有向图;城市乃至全国交通网络是一张加权图;人与人之间的人际关系够成一张图,著名的六度分割理论据说就是基于这个得到的。
常见的处理方式?
1.内存-邻接表
2.持久化-一般数据库
3.大量图操作-专业图数据库