一、前言
本文主要记录了Python学习过程中,基本数据类型str的操作
二、字符串str
字符串可以用单引号‘’、双引号“”、三引号''' '''(主要用于换行字符串)来表示
下面就展示一下字符串的基本操作
通过索引获取元素
s = 'alexwusirritian'
s1 = s[0]
print(s1)
print(type(s1))
输出结果
a
<class 'str'>s3 = s[-1]
print(s3)
输出结果
n切片
s = 'alexwusirritian'
s3 = s[-1]
print(s3)
输出结果
ns = 'alexwusirritian'
s4 = s[0:4]
s4 = s[:4]
print(s4)
输出结果
alexs = 'alexwusirritian'
s5 = s[:]
print(s5)
输出结果
alexwusirritian
s = 'alexwusirritian'
s6 = s[-4:]
print(s6)
输出结果
tian
s = 'alexwusirritian'
# 正序取,步长为正数
s7 = s[:5: 2]
print(s7)
输出结果
aews = 'alexwusirritian'
# 倒序取,步长为负数
s8 = s[-1:-5:-1]
print(s8)
输出结果
naits = 'alexwusirritian'
s9 = s[::-1]
print(s9)
输出结果
naitirrisuwxelas = 'alexwusirritian'
s10 = s[-1:-7:-1]
print(s10)
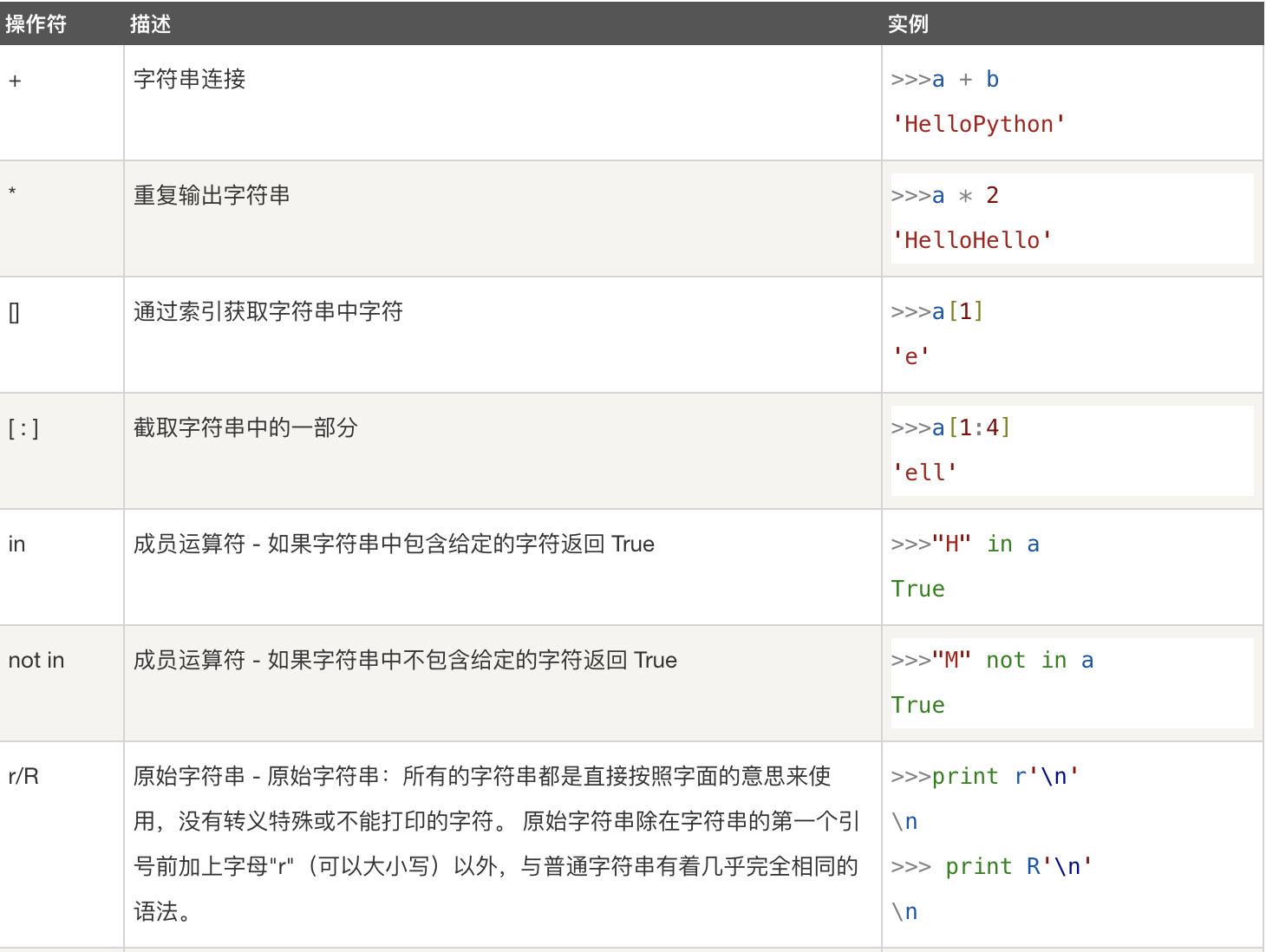
字符串运算符
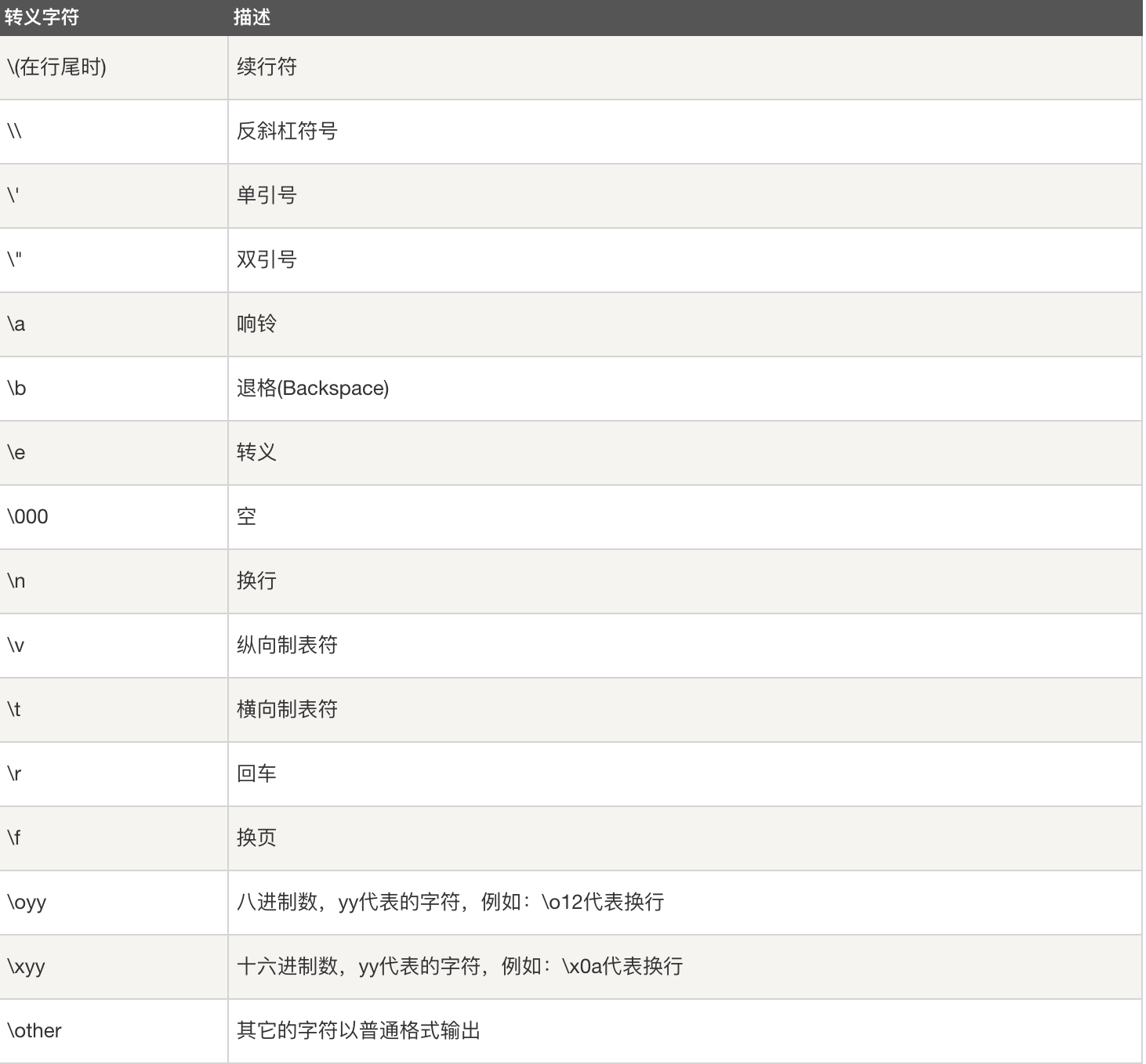
字符转义
字符串常用方法
1、capitalize() 首字母大写,其他小写
s = 'ALEXWUSIR'
s1 = s.capitalize()
print(s1)
Alexwusir2、 swapcase() 大小写翻转
s = 'ALEXwusir'
s2 = s.swapcase()
print(s2)
alexWUSIR3、title() 单词首字母大写
s = 'hello world ! allen'
s3 = s.title()
print(s3)
Hello World ! Allen4、split(str,num) 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则仅分隔 num 个子字符串
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num -- 分割次数。
返回分割后的字符串列表。
s = 'ALEXWUSIR'
res=s.split()
print(res)
输出结果:['ALEXWUSIR']
str = "Line1-abcdef \nLine2-abc \nLine4-abcd"
print str.split( )
print str.split(' ', 1 )
输出结果:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
5、center() 将字符串放到中间,前后使用指定字符补全总长度
a1 = 'hello world'
ret2 = a1.center(20, "*")
print(ret2)
****hello world*****
6、 count() 字符串中的元素出现的个数。可切片
a = 'hello word'
ret3 = a1.count("l",0,4) # 可切片
print(ret3)
27、 startswith 判断是否以...开头 endswith 判断是否以...结尾,返回的是布尔值
扫描二维码关注公众号,回复:
824344 查看本文章

a4 = "dkfjdkfasf54"
ret4 = a4.endswith('jdk', 3, 6) # 顾头不顾腚
print(ret4) # 返回的是布尔值
ret5 = a4.startswith("kfj", 1, 4)
print(ret5)
True
True8、去除指定字符
#strip
name='*egon**'
print(name.strip('*'))
print(name.lstrip('*'))
print(name.rstrip('*'))
egon
egon**
*egon9、replace()替换字符,可以指定替换次数
name = 'alex say :i have one tesla,my name is alex'
print(name.replace('alex', 'SB', 2))
输出结果:SB say :i have one tesla,my name is alex
name = 'alex say :i have one tesla,my name is alex'
print(name.replace('alex', 'SB', 2))
输出结果:SB say :i have one tesla,my name is SB
10、is系列
name='jinxin123'
print(name.isalnum()) #字符串由字母或数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isdigit()) #字符串只由数字组成
输出结果:
True
False
False11、find()、 index()寻找字符串中的元素是否存在
a4 = "dkfjdkfasf54"
ret6 = a4.find("fjdk",1,6)
print(ret6) # 返回的找到的元素的索引,如果找不到返回-1
输出结果: 2
a4 = "dkfjdkfasf54"
ret61 = a4.index("fjdk",4,6)
print(ret61) # 返回的找到的元素的索引,找不到报错。
输出结果:
ValueError: substring not found字符串格式化
字符串%占位符转义使用%
msg = 'name : %s , age : %d, job:%%' % ('allen', 18)
print(msg)
name : allen , age : 18, job:%未指定位置
msg = 'name:{}, age :{},sex:{}'
res = msg.format('allen', 18, '女')
print(res)
name:allen, age :18,sex:女指定位置
msg = 'name:{0}, age :{1},sex:{2}'
res = msg.format('allen', 18, '女')
print(res)通过关键字设置参数
msg = '姓名: {name}, 年龄:{age}, 性别:{sex}'
res = msg.format(name='allen', age=18, sex='女')
print(res)
姓名: allen, 年龄:18, 性别:女
通过字典设置参数
msg = '姓名: {name}, 年龄:{age}, 性别:{sex}'
sit = {'name': 'allen', 'age': 18, 'sex' :'女'}
res = msg.format(**sit)
print(res)
姓名: allen, 年龄:18, 性别:女
通过列表索引设置参数 0是必须的
msg = '姓名: {0[0]}, 年龄:{0[1]}, 性别:{0[2]}'
sit = ['allen', 18, '女']
res = msg.format(sit)
print(res)
姓名: allen, 年龄:18, 性别:女
通过对象设置参数
class AssignValue(object):
def __init__(self, value):
self.value = value
my_value = AssignValue(6)
print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
value 为: 6Unicode 字符串 和 原始字符串
Python中指定Unicode 字符串、原始字符串和普通字符串差不多,唯一区别是在普通字符串前加u,r/R
>>> u'Hello\u0020World !'
u'Hello World !'
>>> r'Hello\u0020World !'
Hello\u0020World !