一、题目要求
获得网页中A-Z所有名字并且爬取名字详情页中的信息,如姓名,性别,,说明等,并存放到csv中(网址:http://www.thinkbabynames.com/start/0/A)
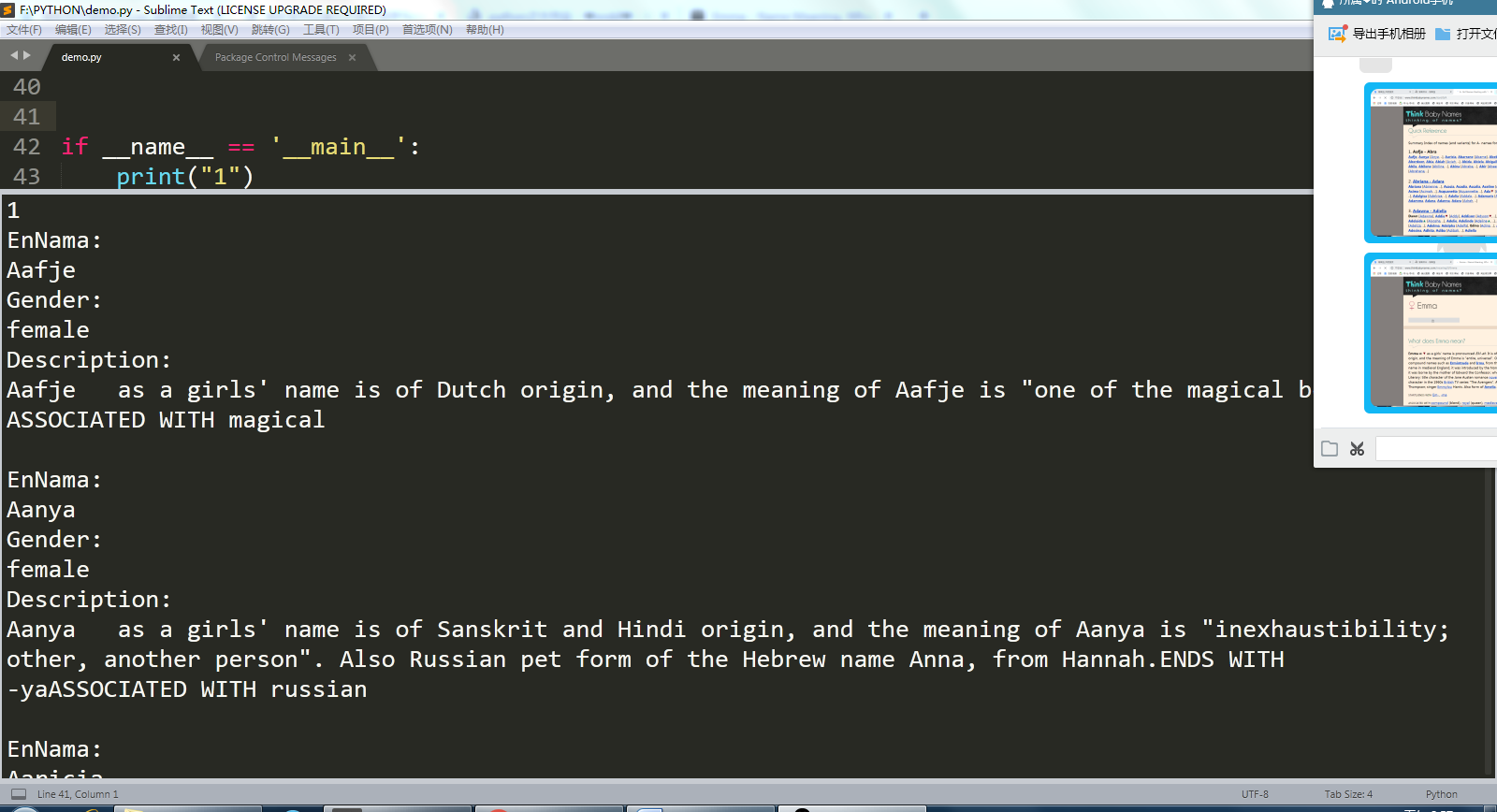
现在得到了所要的信息,但是还没有存入csv中
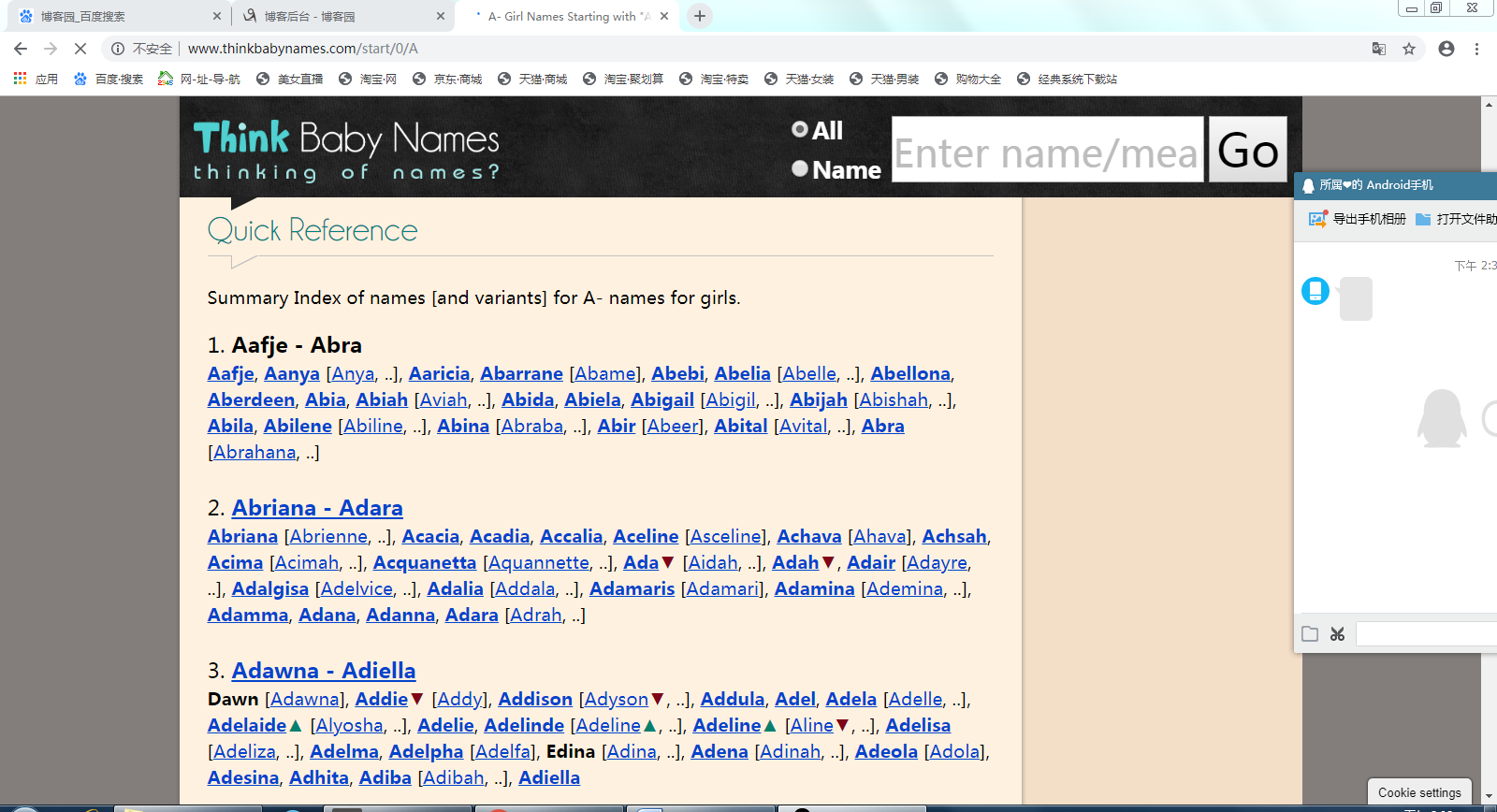
网页截图:

二、题目分析以及解答
首先要获得从A-Z网页连接,规律为只有最后一个字母改变,所以代码如下:
def get_url():#得到A-Z所有网站 urls=[] for i in range(1, 27): i = chr(i+96) urls.append('http://www.thinkbabynames.com/start/0/%s'%i) return urls pass
利用循环得到从A-Z所有网页链接,然后再爬取所有名字,名字详情页的连接以及所需内容,代码如下:
def parse_html(url):#得到所有名字以及连接,爬取所需内容 docx=requests.get(url) soup=BeautifulSoup(docx.content,'html.parser') c_txt1=soup.find('section',{'id':'index'}).findAll('b') url=[] for x in c_txt1: if x.find('a'): i=x.find('a')['href'].split("/")[-1]#使用正则表达式获得所有名字 url.append('http://www.thinkbabynames.com/meaning/0/%s'%i)#获得所有名字详情页链接 r=requests.get('http://www.thinkbabynames.com/meaning/0/%s'%i) result=r.text bs=BeautifulSoup(result,'html.parser') li=bs.find('div',class_='content').find('h1') print("EnNama:") Enname=li.text[8::1]#使用切片语法获得详情页名字(s[x:y:z]x为起始,y为终止,z为步长) print(Enname) print("Gender:") Gender=li.text[1:8:1]#使用切片语法获得详情页名字 print(Gender) li1=bs.find('section',id='meaning').find('p') print("Description:") Description=li1.text print(Description) print() pass
运行结果部分截图:
下一步操作是把爬取到的信息存到csv中,正在努力中。