一、机器学习工作流概念
1.DataFrame
使用Spark SQL中的DataFrame作为数据集,它可以容纳各种数据类型。较之RDD,DataFrame包含了schema 信息,更类似传统数据库中的二维表格。 它被ML Pipeline用来存储源数据。例如,DataFrame中的列可以是存储的文本、特征向量、真实标签和预测的标签等。
2.Transformer
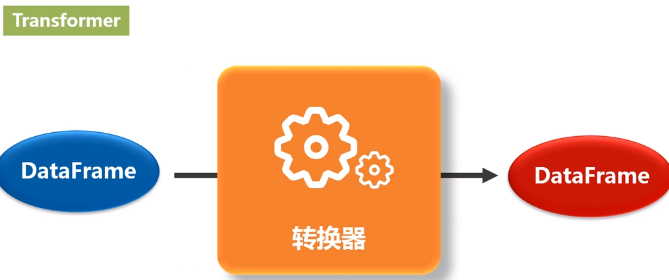
翻译成转换器,是一种可以将一个DataFrame转换为另一个DataFrame的算法。比如一个模型就是一个 Transformer。它可以把一个不包含预测标签的测试数据集 DataFrame 打上标签,转化成另一个包含预测标签的 DataFrame。 技术上,Transformer实现了一个方法transform(),它通过附加一个或多个列将一个DataFrame转换为另一个DataFrame。
3.Estimator
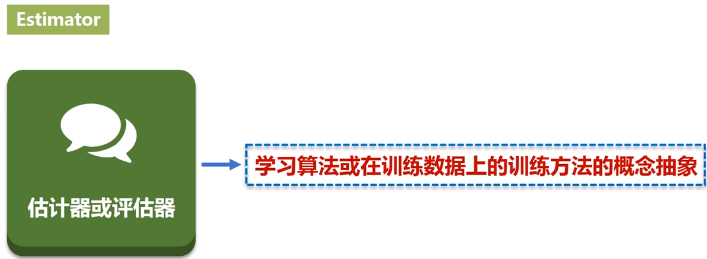
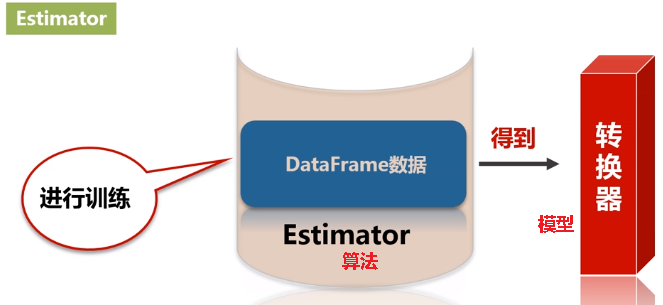
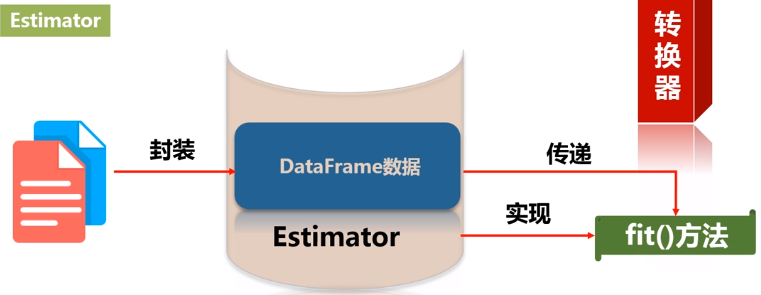
翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据并生成一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。比如,一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
4.Parameter
Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有转换器和估计器可共享用于指定参数的公共API。ParamMap是一组(参数,值)对。
5.PipeLine
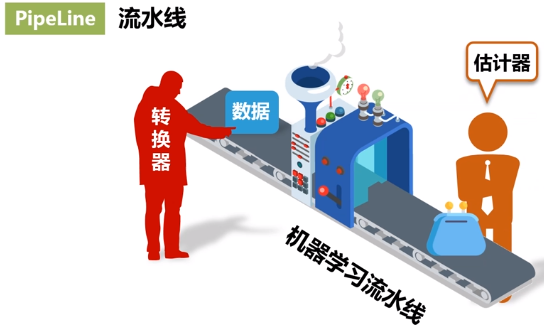
(1)定义
翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
(2)构建一个 Pipeline工作流
首先需要定义 Pipeline 中的各个工作流阶段PipelineStage(包括转换器和评估器),比如指标提取和转换模型训练等。有了这些处理特定问题的转换器和评估器,就可以按照具体的处理逻辑有序地组织PipelineStages 并创建一个Pipeline。

![]()
然后就可以把训练数据集作为输入参数,调用 Pipeline 实例的 fit 方法来开始以流的方式来处理源训练数据。这个调用会返回一个 PipelineModel 类实例,进而被用来预测测试数据的标签
工作流的各个阶段按顺序运行,输入的DataFrame在它通过每个阶段时被转换。
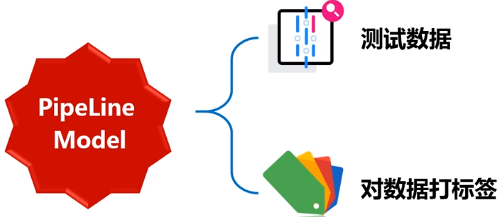

值得注意的是,工作流本身也可以看做是一个估计器(流水线本身是一个评估器)。在工作流的fit()方法运行之后,它产生一个PipelineModel,它是一个Transformer。 这个管道模型将在测试数据的时候使用。
二、构建一个机器学习工作流
以逻辑斯蒂回归为例,构建一个典型的机器学习过程,来具体介绍一下工作流是如何应用的。
任务描述:查找出所有包含"spark"的句子,即将包含"spark"的句子的标签设为1,没有"spark"的句子的标签设为0。
- 需要使用SparkSession对象;
- Spark2.0以上版本的spark-shell在启动时会自动创建一个名为spark的SparkSession对象,当需要手工创建时,SparkSession可以由其伴生对象的builder()方法创建出来。

import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().
master("local").
appName("my App Name").
getOrCreate()
(1)引入要包含的包并构建训练数据集
import org.apache.spark.ml.feature._
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.{Pipeline,PipelineModel}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
scala> val training = spark.createDataFrame(Seq(
| (0L, "a b c d e spark", 1.0),
| (1L, "b d", 0.0),
| (2L, "spark f g h", 1.0),
| (3L, "hadoop mapreduce", 0.0)
| )).toDF("id", "text", "label")
training: org.apache.spark.sql.DataFrame = [id: bigint, text: string, label: double]
(2)定义 Pipeline 中的各个工作流阶段PipelineStage,包括转换器和评估器,具体地,包含tokenizer, hashingTF和lr。
scala> val tokenizer = new Tokenizer().
| setInputCol("text").
| setOutputCol("words") # 输出列
tokenizer: org.apache.spark.ml.feature.Tokenizer = tok_5151ed4fa43e
scala> val hashingTF = new HashingTF().
| setNumFeatures(1000).
| setInputCol(tokenizer.getOutputCol).
| setOutputCol("features")
hashingTF: org.apache.spark.ml.feature.HashingTF = hashingTF_332f74b21ecb
scala> val lr = new LogisticRegression().
| setMaxIter(10).
| setRegParam(0.01)
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_28a670ae952f
(3)按照具体的处理逻辑有序地组织PipelineStages,并创建一个Pipeline。
scala> val pipeline = new Pipeline(). | setStages(Array(tokenizer, hashingTF, lr)) pipeline: org.apache.spark.ml.Pipeline = pipeline_4dabd24db001
现在构建的Pipeline本质上是一个Estimator,在它的fit()方法运行之后,它将产生一个PipelineModel,它是一个Transformer。
scala> val model = pipeline.fit(training) model: org.apache.spark.ml.PipelineModel = pipeline_4dabd24db001
可以看到,model的类型是一个PipelineModel,这个工作流模型将在测试数据的时候使用
(4)构建测试数据
scala> val test = spark.createDataFrame(Seq(
| (4L, "spark i j k"),
| (5L, "l m n"),
| (6L, "spark a"),
| (7L, "apache hadoop")
| )).toDF("id", "text")
test: org.apache.spark.sql.DataFrame = [id: bigint, text: string]
(5)调用之前训练好的PipelineModel的transform()方法,让测试数据按顺序通过拟合的工作流,生成预测结果。
scala> model.transform(test).
| select("id", "text", "probability", "prediction").
| collect().
| foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
| println(s"($id, $text) --> prob=$prob, prediction=$prediction")
| }
(4, spark i j k) --> prob=[0.5406433544851421,0.45935664551485783], prediction=0.0
(5, l m n) --> prob=[0.9334382627383259,0.06656173726167405], prediction=0.0
(6, spark a) --> prob=[0.15041430048068286,0.8495856995193171], prediction=1.0
(7, apache hadoop) --> prob=[0.9768636139518304,0.023136386048169585], prediction=0.0