jmeter脚本包含很多请求,而请求之间很可能存在某种关联。关联即为上下文之间的连接,通过前面请求得到的响应,作为后文的输入,以此根据前文不同的响应,做出不同的处理。
比如登录,登录时获取的token,可通过关联获取得到,后面的各种请求都需要以该token作为参数传送,才能正常访问页面资源。
jmeter关联的方式有三种,分别是正则表达式提取器,Xpath Extractor和JSON Extractor。
1、正则表达式提取器
在取样器(如HTTP请求),选择后置处理器——正则表达式提取器,即可使用。
下面以提取初始token为例,讲述下如何提取所需信息。
先添加一个HTTP请求
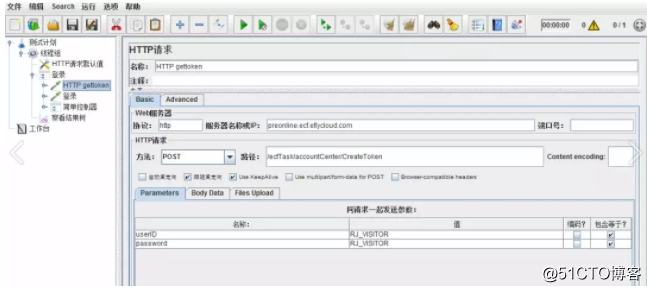
点击运行,在结果树中查看响应信息。本例,我们需要提取的是data的值,作为token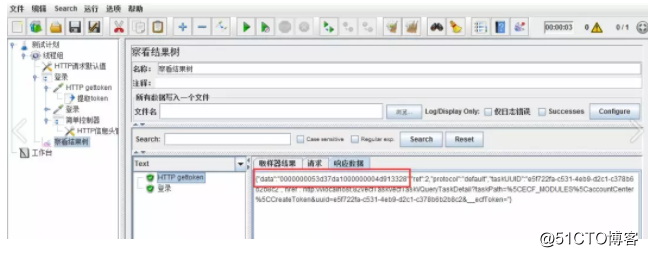
在HTTP gettoken的请求中,添加正则表达式提取器,填入如下信息。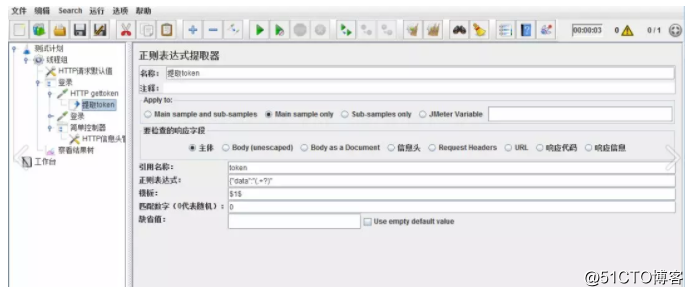
解释:
(1)引用名称:下一个请求要引用的参数名称,如填写token,则可用${token}引用它。
(2)正则表达式:()括起来的部分就是要提取的。此部分需了解正则表达式的方法,在此不细说。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式(由多个括号提取),如$2$,表示解析到的第2个值,$1$表示解析到的第1个值。
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0。
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取。
添加一个新的请求,该请求可获取上面的值作为token。引用格式为{token_g1}。g1表示提取的第一个值(如有多个token,g2表示第二个)。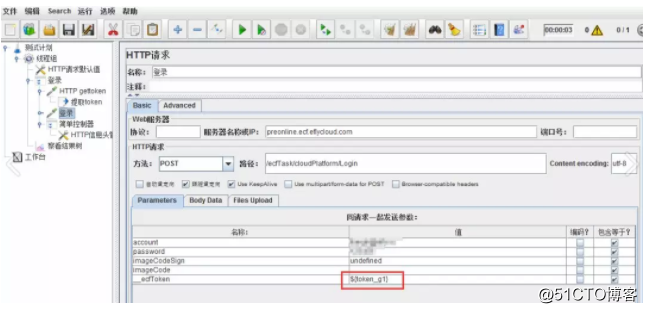
然后点击运行,在结果树可看到,新请求中的token参数值与前文获取的data值一致,表示提取成功。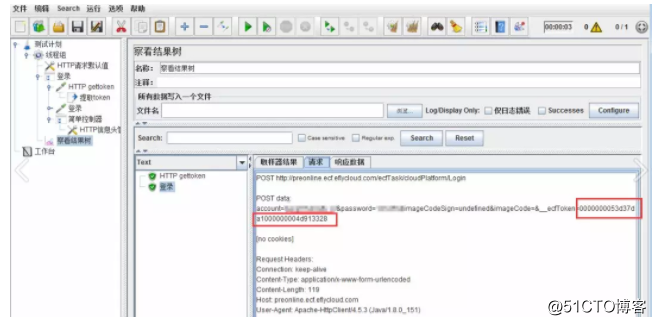
2、Xpath Extractor
XPath Extractor是另一个可被用来提取页面给定内容的Post Processor(后置处理器),XPath Extractor的使用方式与正则表达式处理器类似,只不过需要在该Extractor中指定的不是正则表达式,而是给定的XPath路径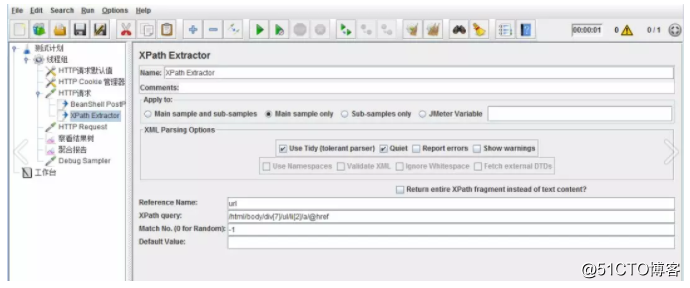
当提取的文本时页面上的元素时,Xpath Extractor比较方便好用。Xpath可在浏览器通过F12,获取所需元素的表达式。
3、JSON Extractor
JSON Extractor与Xpath Extractor很相似,光听名字就知道。对于响应结果为JSON格式的数据,用JSON Extractor进行提取会更为方便和优雅。上一个例子说明下如何使用:
假如需要从下面的url中提取userType的值,响应结果以json格式显示,可清晰的看到层级关系。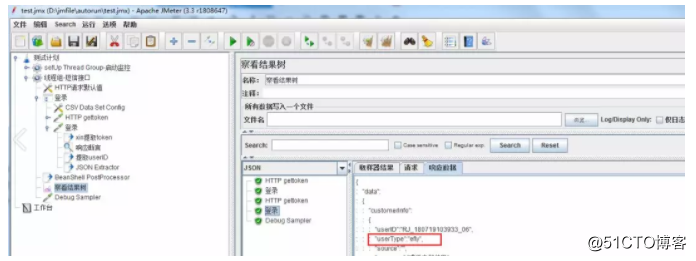

在登录的请求上添加JSON Extractor,Variable names给提取的变量设名称,JSON Path expresstions格式如下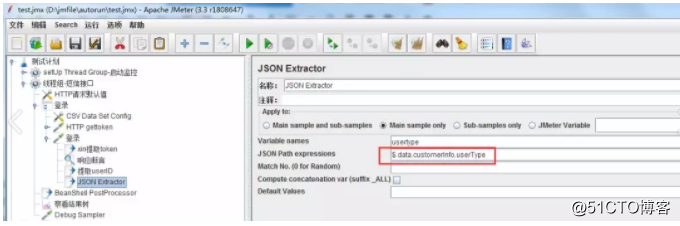
如果该url的响应包含多个customerinfo,要提取第二个customerinfo里面的userType,可用$.data.customerInfo[1].userType的数组形式提取。
注:如需核对是否成功提取所需变量,可在线程组添加一个debug sampler,执行脚本后,查看结果树即可知晓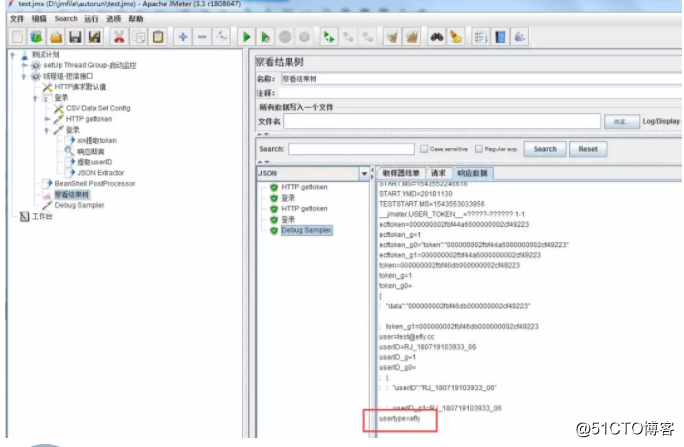
三种关联方式各有其适用范围,都掌握这些使用方法会在编写测试脚本时如鱼得水。
如获取HTML等资源时,选择Xpath Extractor更便捷,可快速提取具体元素的属性值;
如响应格式为JSON,选择JSON Extractor无疑更方便;
若进行接口测试,请求的响应不是页面元素的形式,则应用正则表达式进行提取。