https://www.cnblogs.com/LeftNotEasy/archive/2011/03/07/random-forest-and-gbdt.html
周志华《机器学习》
决策树实际上是将空间用超平面进行划分的一种方法,使得每一个叶子节点都是在空间中的一个不相交的区域。在进行决策的时候,根据输入样本的特征值,一步一步往下,最终使得样本落入其中一个叶子节点。
在集成学习中,期望个体学习器应该“好而不同”,我们可以考虑使用相互有交叠的采样子集。
自助采样法:给定包含
m 个样本的数据集,随机取出一个样本放入采样集,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过m 次采样,最终得到的包含m 个样本的采样集,初始数据集中有的样本在采样集多次出现,有的则从未出现。初始数据集中约有63.2%的样本出现在采样集。
Bagging是并行式集成学习方法最著名的代表。Bagging基本流程:基于自助采样法,采样出
Bagging集成是一个很高效的集成学习算法,另外,Bagging能不经修改地用于多分类、回归等任务。
随机森林(Random Forest,简称RF)
RF是Bagging的一个扩展变体,在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
随机森林由很多决策树组成,每一棵决策树之间没有联系,相互独立。给定一个输入样本,让森林里的每一棵决策树进行判断,最后可以用投票法决定该样本属于哪一类。
随机两字体现在哪里呢?
样本扰动:构建每一棵决策树的时候,对样本采取有放回的方式,意味着在采样得到的样本集合中,可能会有重复的样本,因此每一棵树的输入样本不一定是全部的样本,一定程度上不容易出现over-fitting。假设输入样本为
N 个,那么需要采样N 次,最终的到N 个样本。属性扰动:对于每一棵决策树,随机从样本的所有特征
M 中,选择m(推荐m=log2M) 特征。按照单决策树的构建方式建立出决策树。
RF简单,容易实现,计算开销小,同时在很多现实任务中展现出强大的性能。与Bagging中基学习器的多样性仅通过样本扰动不同,随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间的差异度的增加而进一步提升。
RF与Bagging比较:
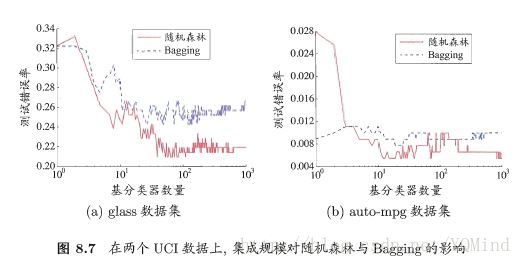
随机森林因为引入属性扰动,当基学习器数量较少时,性能相对较差,然而,随着基学习器数目的增加,随机森林通常会收敛到更低的泛化误差。值得一提的是,RF的训练效率常优于Bagging,因为RF只需考察一个属性子集。