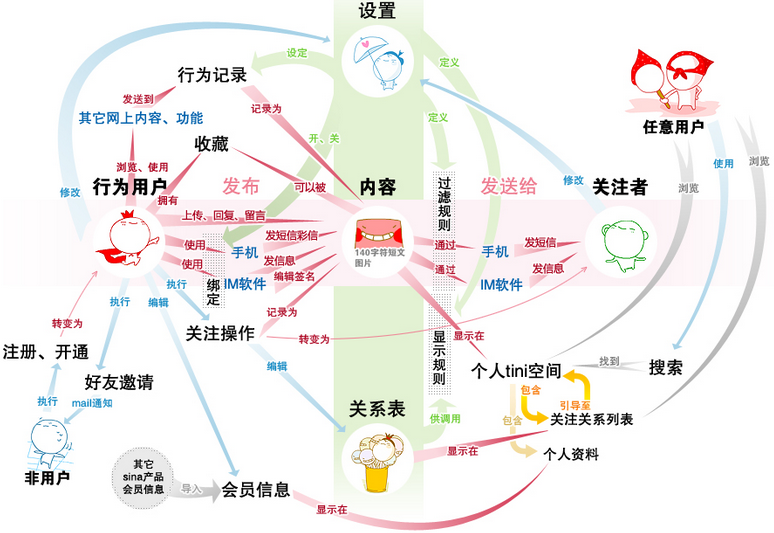
一、微博核心业务图
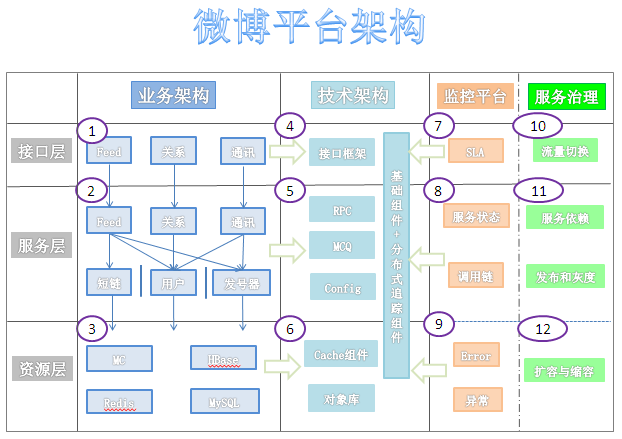
二、微博的架构设计图
三、简述
先来看看Feed流中的一些概念:
- Feed:Feed流中的每一条状态或者消息都是Feed,比如微博中的一条微博就是一个Feed。
- Feed流:持续更新并呈现给用户内容的信息流。每个人微博关注页等等都是一个Feed流。
- Timeline:Timeline其实是一种Feed流的类型,微博,朋友圈都是Timeline类型的Feed流。
- 关注页Timeline:展示其他人Feed消息的页面,比如微博的首页等。
- 个人页Timeline:展示自己发送过的Feed消息的页面,比如微博的个人页等。
Feed流的主要模式:
- 推(Push)
- 拉(Pull)
- 推拉结合(Hybrid)
推模式
又称写扩散。该方式为每个用户维护一个订阅列表,记录该用户订阅的消息索引(一般为消息ID、类型、发表时间等元数据)。每当用户发布消息时,都会去更新其关注者的订阅列表。
优点:存储空间可能不是很大,用户查询自己关注的所有人Feed时,速度快,性能非常高。
缺点:
1. 推送量会非常大。比如微博红人何炅(粉丝1亿+)发一篇微博,如果采用推模式,就会产生一亿+条数据。
2. 资源浪费。试想,一个大量用户的微博系统如果使用推模式,是不是会产生非常巨大的数据呢?更何况活跃用户只有几千万,剩下几个亿的用户他们可能是半年来一次,或者说更短如两周过来一次;这些数据推给他可能根本没有机会看到,存在很大的资源浪费。
拉模式
又称读扩散。该方式为每个用户维护一个Feed列表,记录该用户所有关注的动态索引。只需要用户发表微博时,存储一条微博数据到Feed表中。用户每次查询Feed时都会去查询Feed表,产生:
优点:这种模式实现起来比较简单,只是在查询的时候需要多考虑下缓存的结构;
缺点:
1. 当用户登陆时,必须很快返回数据的时候,运算量非常大。Feeds表会产生很大的压力,对于一个大系统,Feed表会产生比较大的数据,如果粉丝人数比较多,数据库的压力就会非常大。
2. 一般在线的用户,客户端都会定期扫描,又会增加很大的压力,这在查询性能上没有推模式的效率高。
共性问题:不管推模式还是拉模式都存在如果关注数量或者粉丝数量过多,会导致遍历时间太长的问题。综合所有考虑,因为我们要做的是一个要求实时度很高的系统,把不必要系统开销去掉。怎么去解决 ?
推拉结合模式
这是一种折中的解决方案:在线推、离线拉。用户发布状态时,即便微博大V,同时在线的粉丝可能只有几万甚至几千。推拉模式只推给在线的粉丝,离线的粉丝上线后手动拉取状态即可同步内容。同时,每个用户都会维护一个类似发件箱与收件箱的东西,来保存自己发过的状态和Feed状态,以完成推和拉。
微博是一个广场,所有人都可以关注、发送、转载等,相比较限制人数为5000人的朋友圈,其复杂程度高于朋友圈的timeline,因此考虑到时效性和内存的代价,应该会把用户分为热用户和冷用户,并针对不同用户采取不同的方式。
参考文章:
https://www.cnblogs.com/zl0372/articles/feed_6.html
https://juejin.im/entry/5b166320f265da6e61788a25
https://www.cnblogs.com/sunli/archive/2010/08/24/twitter_feeds_push_pull.html