雪球是一个什么样的网站?
雪球股票,聪明的投资者都在这里 - 雪球提供沪深港美股票实时行情、实战交流、实盘交易。
雪球的Feed流样式
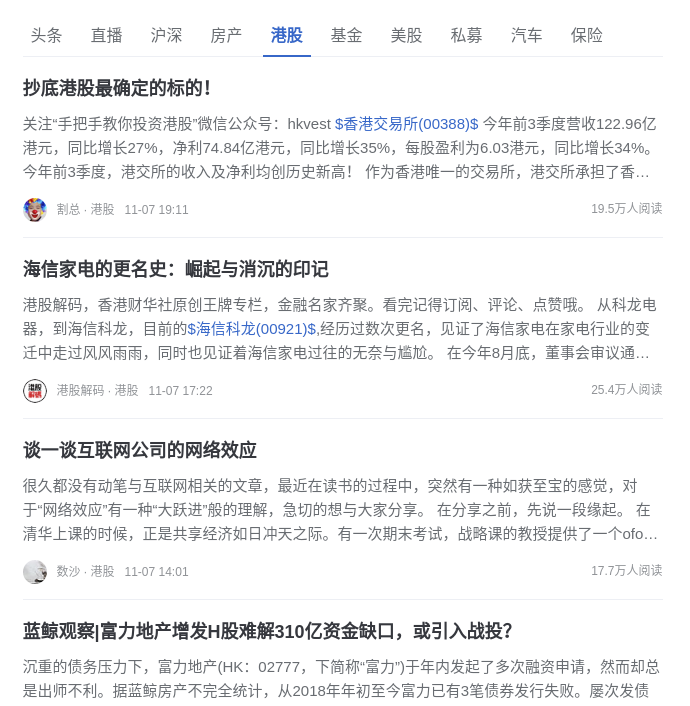
如上图所示为用户为从雪球首页截取出来的信息流,从图中可以看出雪球的信息流包含如下几个模块:
- 头条
- 直播
- 沪深
- 房产
- 港股
- 基金
- 美股
- 私募
- 汽车
- 保险
雪球首页的信息流采用XML请求进行数据的异步加载,其请求地址为 feed流请求地址,该请求中包含着几个重要的参数,分别如下:
- since_id : 信息流数据所请求的新闻起始id
- max_id : 信息流数据所请求的新闻的最大id
- count : 本次请求的数据条数
- category : 请求分类 下图所示为通过开发者工具截取的信息流异步请求过程:
 对于网站来说,通常这种接口数据需要较为复杂的权限认证才可以进行数据的抓取,而笔者在实验过程当中发现,只要在请求时在请求头部附带会话的Cookie即可,(当用户访问雪球首页的时候,雪球的服务器会自动将Cookie发回给浏览器)。 使用Scrapy抓取雪球的信息流时的步骤如下:
对于网站来说,通常这种接口数据需要较为复杂的权限认证才可以进行数据的抓取,而笔者在实验过程当中发现,只要在请求时在请求头部附带会话的Cookie即可,(当用户访问雪球首页的时候,雪球的服务器会自动将Cookie发回给浏览器)。 使用Scrapy抓取雪球的信息流时的步骤如下:
- 枚举雪球信息流所有的分类,如下:
_category = {
'-1': "头条",
'6': "直播",
'105': "沪深",
'111': "房产",
'102': "港股",
'104': "基金",
'101': "美股",
'113': "私募",
'114': "机车",
'110': "保险"
}2. 定义雪球的首页url并设置其为启动地址
_host_url = 'https://xueqiu.com/'
start_urls = (
_host_url,
)3. 定义雪球信息流接口url,这里我们设置每次请求抓取20条数据(count=2),我们不设置抓取的起始位置(since_id=-1),max_id与category这两个参数在爬虫执行过程中自动赋值。
_topic_url = \
"https://xueqiu.com/v4/statuses/public_timeline_by_category.json \
?since_id=-1&max_id={}&count=20&category={}"4. 编写爬虫的启动地址响应处理逻辑。 在对雪球首页所返回的响应处理函数中我们并没有对response进行处理,而是请求信息流数据。
def parse(self, response):
for code in self._category:
topic_url = self._topic_url.format(-1, code)
yield Request(topic_url,
meta={'code': code},
callback=self.parse_request)5. 编写信息流接口响应handler
def parse_request(self, response):
try:
json_data = json.loads(response.text)
next_max_id = json_data.get('next_max_id', -1)
topic_list = json_data.get('list', [])
code = response.meta['code']
print code
if next_max_id == -1 or topic_list == []:
return
# 此处编写接口请求数据的存储逻辑
yield Request(topic_brief_url, callback=self.parse_response) # 发出请求
yield Request(self._topic_url.format(next_max_id, code),
meta={'code': code},
callback=self.parse_request)
except:
raise 6. 编写信息流内容存储函数
def parse_response(self, response):
"""解析文章内容"""
target = urlparse(response.url).path # 获取文章地址
topic_info_item = TopicInfoItem()
topic_info_item['target'] = target
topic_info_item['text'] = response.text
yield topic_info_item # 存储文章内容7. 雪球信息流接口返回的数据如下:

其中关键字段如下:
- list
- addition
- tip
- next_max_id 下一条信息流的最大id
- next_id 下一条信息流的id
- data 存储改次返回的信息流数据
关键配置:
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False 该行要注释掉,这样每次请求的头部才会附带Cookie
USER_AGENT = "Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1" # 设置用户代理
回复 “雪球” 获取 爬虫完整代码

往期精选▼
Spark Shuffle调优之调节map端内存缓冲与reduce端内存占比
Flink中Checkpoint和Savepoint 的 3 个不同点