前面的多个redis节点,都是一个节点存储一个分片的信息,如果单个节点宕机,会导致这个分片的数据未命中,这就需要实现单个分片的高可用,通过配置多个从节点来backup主节点。另外主从节点之间是没有一个监听者的,主节点宕机后,从节点不会知道自己有上位的机会,redis提供的哨兵就是一个监听者的角色,它可以实现主从的故障转移。
单个分片高可用
实现单个分片高可用,需要实现主从复制,即配置一个主节点,多个从节点,主节点上的数据可以复制到从节点上。redis有一主多从,和多级主从的结构,主从结构不宜复杂,这样会让数据同步的路径更多,会有不稳定的风险。
一主多从,企业常用,一般配置1主6从。
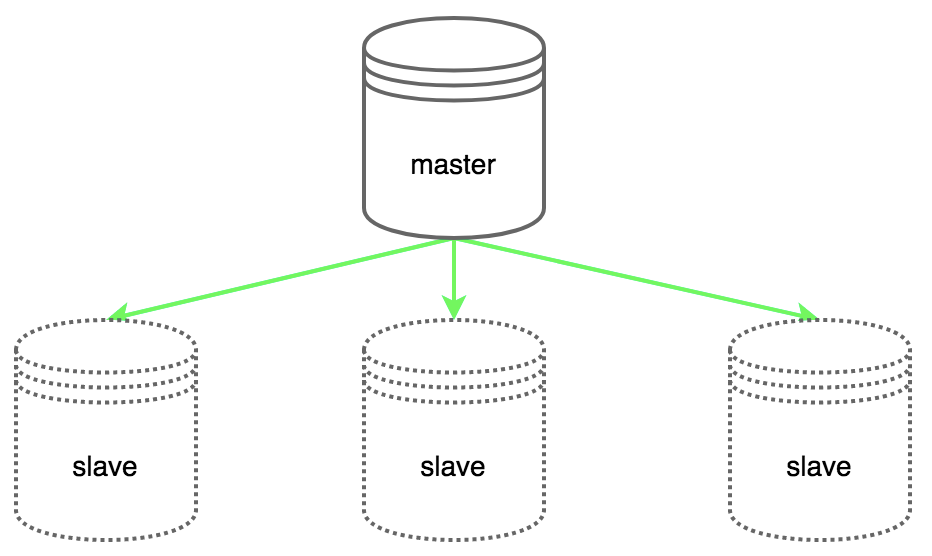
多级主从结构示意

下面在单台centos服务器中,配置一主两从的结构,实现主从复制。
(1)准备3个redis.conf文件,启动时加载用,里面修改端口号为6382、6383和6384,其他配置参考https://www.cnblogs.com/youngchaolin/p/11983705.html。
# 三个文件以端口号来区分,启动加载时不容易出错
-rw-r--r--. 1 root root 46750 Dec 8 05:05 redis6382.conf -rw-r--r--. 1 root root 46750 Dec 8 05:06 redis6383.conf -rw-r--r--. 1 root root 46750 Dec 8 05:06 redis6384.conf
(2)redis-server redisXXXX.conf来启动三个redis节点,使用info命令选一个来查看信息,发现都是默认自己就是master主节点,并且从节点数为0。
启动redis-server。
[root@node01 /home/software/redis-3.2.11]# redis-server redis6382.conf [root@node01 /home/software/redis-3.2.11]# redis-server redis6383.conf [root@node01 /home/software/redis-3.2.11]# redis-server redis6384.conf [root@node01 /home/software/redis-3.2.11]# ps -ef|grep redis root 8828 1 0 05:09 ? 00:00:00 redis-server *:6382 root 8832 1 0 05:09 ? 00:00:00 redis-server *:6383 root 8836 1 0 05:09 ? 00:00:00 redis-server *:6384 root 8869 5351 0 05:11 pts/1 00:00:00 grep redis You have new mail in /var/spool/mail/root
info replication命令查看节点信息。
# 参考了文末博文
127.0.0.1:6382> info replication # Replication role:master #角色主节点,slave就是从节点 connected_slaves:0 #连接的从节点数为0 master_repl_offset:0 # 主节点复制偏移量 repl_backlog_active:0 #复制积压缓冲区是否开启 repl_backlog_size:1048576 #复制积压缓冲区大小 repl_backlog_first_byte_offset:0 #复制积压缓冲区偏移量大小 repl_backlog_histlen:0 #等于master_repl_offset - repl_backlog_first_byte_offset,该值不会超过repl_backlog_size的大小
(3)将6383和6384的从节点挂接到6382主节点,有两种方式来实现,分为临时和永久两种方式,重启服务后临时方式的主从关系将消失,永久方式的主从启动后就有。
a.临时挂接,需要登录到6383和6384的客户端,使用slaveof master的IP master的端口来实现,完成后登录6382来使用info replication继续查看信息。
[root@node01 /home/software/redis-3.2.11]# redis-cli -p 6383
# 挂接 127.0.0.1:6383> slaveof 127.0.0.1 6382 OK 127.0.0.1:6383> quit [root@node01 /home/software/redis-3.2.11]# redis-cli -p 6384
# 挂接 127.0.0.1:6384> slaveof 127.0.0.1 6382 OK 127.0.0.1:6384> quit [root@node01 /home/software/redis-3.2.11]# redis-cli -p 6382
# 查看信息,发现发生了变化 127.0.0.1:6382> info replication # Replication role:master # 角色依然为主 connected_slaves:2 # 有两个从节点,下面就是从节点信息 slave0:ip=127.0.0.1,port=6383,state=online,offset=43,lag=0 slave1:ip=127.0.0.1,port=6384,state=online,offset=43,lag=0 master_repl_offset:43 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:42
查看从节点信息。
[root@node01 /home/software/redis-3.2.11]# redis-cli -p 6383 127.0.0.1:6383> info replication # Replication role:slave # 从节点 master_host:127.0.0.1 # master ip master_port:6382 # master 端口 master_link_status:up # 与master的同步状态,up代表连接,down代表断开 master_last_io_seconds_ago:9 # 主节点多少秒没发送数据到从节点 master_sync_in_progress:0 # 主节点是否和从节点在同步 slave_repl_offset:323 # 从节点复制偏移量 slave_priority:100 # 从节点的优先级,默认100,可以修改 slave_read_only:1 # 从节点是否只读,1代表只读,代表只能查看不能删除修改数据 connected_slaves:0 # 连接的从节点个数 master_repl_offset:0 # 主节点复制偏移量 repl_backlog_active:0 # 同上 repl_backlog_size:1048576 # 同上 repl_backlog_first_byte_offset:0 # 同上 repl_backlog_histlen:0 # 同上
b.永久挂接,需要修改从节点redis.conf配置文件,启动服务后,使用上面命令查看,自动就是主从关系,重启后依然是主从关系。
# 添加永久配置
# slaveof <masterip> <masterport> slaveof 192.168.200.140 6382
(4)主节点写入数据,查看从节点,发现成功的同步了主节点的数据。
# 主节点添加一个hash类型数据
127.0.0.1:6382> hmset messi score 11 assist 10 shoot 5 OK 127.0.0.1:6382> hmget messi score assist shoot 1) "11" 2) "10" 3) "5" 127.0.0.1:6382> quit You have new mail in /var/spool/mail/root
# 6383从节点有复制到数据 [root@node01 /home/software/redis-3.2.11]# redis-cli -p 6383 127.0.0.1:6383> keys * 1) "messi" 127.0.0.1:6383> hmget messi score assist shoot 1) "11" 2) "10" 3) "5" 127.0.0.1:6383> quit
# 6384从节点也有复制到数据 [root@node01 /home/software/redis-3.2.11]# redis-cli -p 6384 127.0.0.1:6384> keys * 1) "messi"
另外从节点默认配置是只读的,想删除上面的数据会报错提示只读,只能主节点来删除数据。
127.0.0.1:6384> flushdb (error) READONLY You can't write against a read only slave.
从redis2.6开始,配置文件里从节点默认是只读。

哨兵集群原理
在上面配置了主从关系后,如果将6382主节点宕机掉,查看从节点信息,发现依然显示是从节点。这样只实现了主从复制,不能实现主从故障转移和替换,即不能实现主节点挂掉,从节点顶上去的功能,如果使用SharedJedisPool来连接,还需要修改连接的ip和端口,这样会很麻烦。
127.0.0.1:6383> info replication # Replication role:slave master_host:127.0.0.1 master_port:6382 master_link_status:down # 主节点宕机了,从节点依然是从节点 ...省略
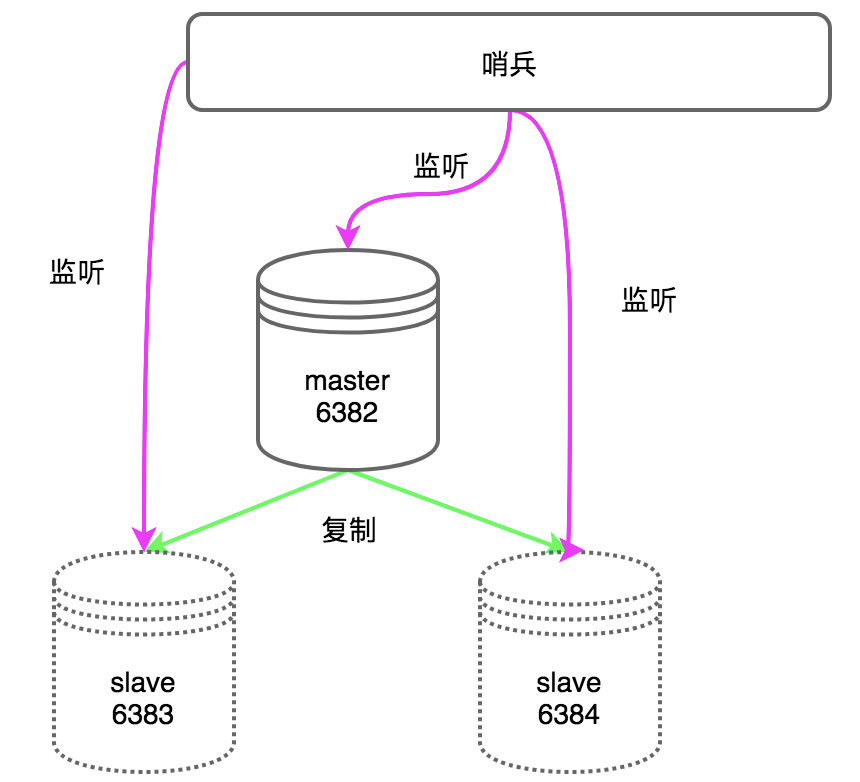
这样就需要一个监听者来管理这些节点,redis提供了这样的角色,就是哨兵sentinal,以下是它的原理图。
(1)master和slave之间实现主从复制
(2)哨兵启动后,会连接master,通过info命令来获取master和slave的信息,保存到内存后持久化到sentinal配置文件中。
(3)哨兵(这里只有一个)监听所有的master和slave,会通过每秒一次的rpc心跳,确认master和slave是否还正常运行着。
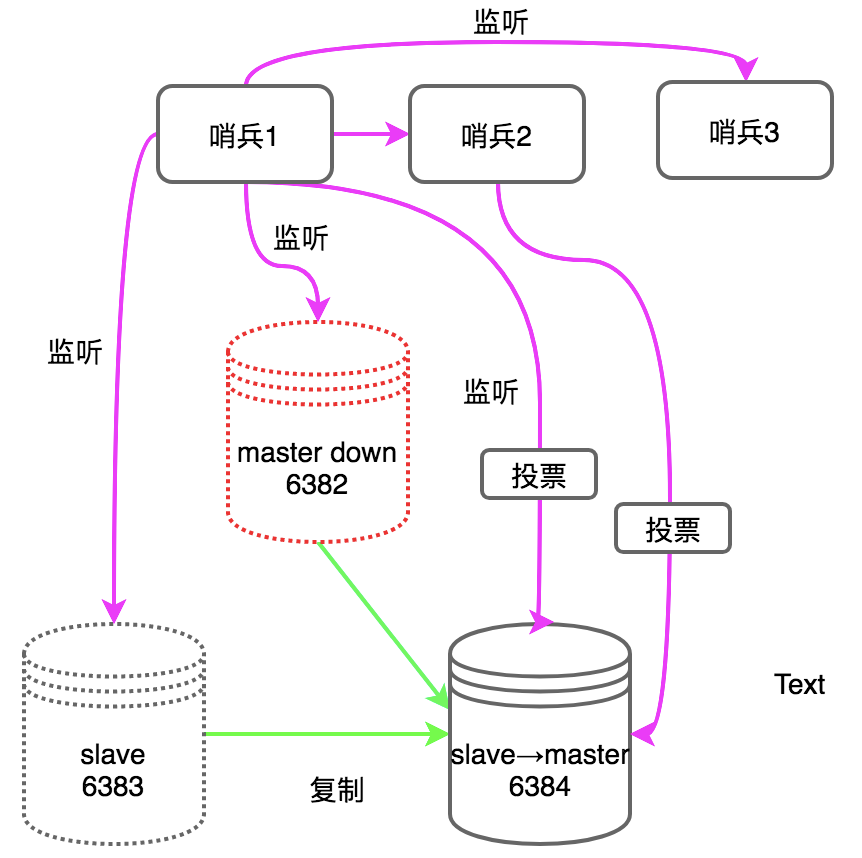
(4)当master宕机后,哨兵会对slave进行投票选举选取新的slave,一般一个哨兵可能会发生判断失误,如果master没宕机,只是网络问题导致心跳检测失效判断宕机显然是不行的,因此哨兵也需要配置成集群,最少是配置3个,可以容许宕机一个哨兵,这一点和zookeeper很像。
(5)当一个哨兵检测到master宕机后,会被认为是sdown,即subjective down(主观宕机),当哨兵集群中的大多数(过半)认为master down,才会认为是odown,即objective down(客观宕机,真的宕机),这个时候就需要投票选举新的master了。
(6)哨兵会对剩下的slave进行投票选举,采取的是过半机制,只要过半哨兵同意选举它,salve就会荣升master,并获得master的权限。
(7)当master恢复过来,会作为salve挂接到新的master上。
配置哨兵集群
下面在上面主从复制功能的基础上,添加哨兵集群、实现对一个分片的高可用 。
(1)准备sentinal.conf文件,修改端口号,保护模式设置为no,并设置sentinal monitor。
# 先准备三份配置文件
[root@node01 /home/software/redis-3.2.11]# cp sentinel.conf sentinel26379.conf [root@node01 /home/software/redis-3.2.11]# cp sentinel.conf sentinel26380.conf [root@node01 /home/software/redis-3.2.11]# cp sentinel.conf sentinel26381.conf
以26379的哨兵为例,除了修改保护模式为no,端口号修改为对应端口号外,还需要配置监听主节点逻辑。
sentinal monitor:代表这个参数的key;
mymaster:代表master的代号;
ip:master的ip;
redis-port:master的端口号,这里的初始主节点是6382;
quorum:主观投票下限次数,如果是3个哨兵集群,则是2,如果是5个哨兵集群,则是3,采取过半机制
# 保护模式设置为no
protected-mode no # 端口号 # port <sentinel-port> # The port that this sentinel instance will run on port 26379 # 配置监听主节点 # sentinel monitor <master-name> <ip> <redis-port> <quorum>
# ip写主机的实际ip,写127.0.0.1后面使用api会连不上 sentinel monitor mymaster 192.168.200.140 6382 2
(2)在master和slave都启动的情况下,启动一个哨兵,观察控制台情况。发现哨兵启动后,就通过master,获取到了两个salve的信息,这是因为底层调用了info命令。
[root@node01 /home/software/redis-3.2.11]# redis-sentinel sentinel26379.conf 1680:X 09 Dec 13:10:11.322 * Increased maximum number of open files to 10032 (it was originally set to 1024). _._ _.-``__ ''-._ _.-`` `. `_. ''-._ Redis 3.2.11 (00000000/0) 64 bit .-`` .-```. ```\/ _.,_ ''-._ ( ' , .-` | `, ) Running in sentinel mode |`-._`-...-` __...-.``-._|'` _.-'| Port: 26379 | `-._ `._ / _.-' | PID: 1680 `-._ `-._ `-./ _.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | http://redis.io `-._ `-._`-.__.-'_.-' _.-' |`-._`-._ `-.__.-' _.-'_.-'| | `-._`-._ _.-'_.-' | `-._ `-._`-.__.-'_.-' _.-' `-._ `-.__.-' _.-' `-._ _.-' `-.__.-' 1680:X 09 Dec 13:10:11.324 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
# 生成的myid会持久化到配置文件中
1680:X 09 Dec 13:10:11.326 # Sentinel ID is 6d9373993f231a33686485a7e3baf205ff98d7b7
# 监听6382的节点 1680:X 09 Dec 13:10:11.326 # +monitor master mymaster 192.168.200.140 6382 quorum 2
# 通过6382 master主节点调用info命令获取到slave节点的信息 1680:X 09 Dec 13:10:11.326 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1680:X 09 Dec 13:10:11.329 * +slave slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382
配置文件中新增myid

(3)开启另外两个哨兵,发现启动后,26379启动的控制台里会添加提示获取到其它两台的哨兵的信息,其它两台也是如此。
26379的关于哨兵的日志
1931:X 09 Dec 13:25:48.461 * +sentinel sentinel 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 192.168.200.140 26380 @ mymaster 192.168.200.140 6382 1931:X 09 Dec 13:25:55.809 * +sentinel sentinel 2b402bba6fde9ba010a8f7cd9b2106356aad17cc 192.168.200.140 26381 @ mymaster 192.168.200.140 6382
26380的部分日志
1934:X 09 Dec 13:25:46.323 # Sentinel ID is 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 1934:X 09 Dec 13:25:46.323 # +monitor master mymaster 192.168.200.140 6382 quorum 2 1934:X 09 Dec 13:25:46.323 * +slave slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:25:46.324 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:25:46.975 * +sentinel sentinel 6d9373993f231a33686485a7e3baf205ff98d7b7 192.168.200.140 26379 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:25:55.809 * +sentinel sentinel 2b402bba6fde9ba010a8f7cd9b2106356aad17cc 192.168.200.140 26381 @ mymaster 192.168.200.140 6382
26381的部分日志
1937:X 09 Dec 13:25:53.763 # Sentinel ID is 2b402bba6fde9ba010a8f7cd9b2106356aad17cc 1937:X 09 Dec 13:25:53.763 # +monitor master mymaster 192.168.200.140 6382 quorum 2 1937:X 09 Dec 13:25:53.765 * +slave slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1937:X 09 Dec 13:25:53.767 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1937:X 09 Dec 13:25:54.715 * +sentinel sentinel 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 192.168.200.140 26380 @ mymaster 192.168.200.140 6382 1937:X 09 Dec 13:25:55.159 * +sentinel sentinel 6d9373993f231a33686485a7e3baf205ff98d7b7 192.168.200.140 26379 @ mymaster 192.168.200.140 6382
可以看到哨兵通过连接主节点6382,获取到了从节点的信息,并且还获取到其它哨兵的信息,获取到的信息会持久化到配置文件中,添加到文件尾部,以26379为例。

(4)将6382主节点宕机,观察每个哨兵控制台情况。
26379的部分日志
1931:X 09 Dec 13:32:56.471 # +sdown master mymaster 192.168.200.140 6382 1931:X 09 Dec 13:32:56.595 # +new-epoch 1 1931:X 09 Dec 13:32:56.596 # +vote-for-leader 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 1 1931:X 09 Dec 13:32:56.934 # +config-update-from sentinel 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 192.168.200.140 26380 @ mymaster 192.168.200.140 6382 1931:X 09 Dec 13:32:56.934 # +switch-master mymaster 192.168.200.140 6382 192.168.200.140 6384 1931:X 09 Dec 13:32:56.934 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6384 1931:X 09 Dec 13:32:56.934 * +slave slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384 1931:X 09 Dec 13:33:26.983 # +sdown slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384
26380的部分日志
1934:X 09 Dec 13:32:56.490 # +sdown master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.591 # +odown master mymaster 192.168.200.140 6382 #quorum 2/2 1934:X 09 Dec 13:32:56.591 # +new-epoch 1 1934:X 09 Dec 13:32:56.591 # +try-failover master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.593 # +vote-for-leader 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 1 1934:X 09 Dec 13:32:56.596 # 2b402bba6fde9ba010a8f7cd9b2106356aad17cc voted for 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 1 1934:X 09 Dec 13:32:56.596 # 6d9373993f231a33686485a7e3baf205ff98d7b7 voted for 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 1 1934:X 09 Dec 13:32:56.669 # +elected-leader master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.669 # +failover-state-select-slave master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.728 # +selected-slave slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.728 * +failover-state-send-slaveof-noone slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.787 * +failover-state-wait-promotion slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.885 # +promoted-slave slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.885 # +failover-state-reconf-slaves master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:56.934 * +slave-reconf-sent slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:57.739 # -odown master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:57.951 * +slave-reconf-inprog slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:57.951 * +slave-reconf-done slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:58.042 # +failover-end master mymaster 192.168.200.140 6382 1934:X 09 Dec 13:32:58.042 # +switch-master mymaster 192.168.200.140 6382 192.168.200.140 6384 1934:X 09 Dec 13:32:58.042 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6384 1934:X 09 Dec 13:32:58.042 * +slave slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384 1934:X 09 Dec 13:33:28.092 # +sdown slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384
26381的部分日志
1937:X 09 Dec 13:32:56.563 # +sdown master mymaster 192.168.200.140 6382 1937:X 09 Dec 13:32:56.595 # +new-epoch 1 1937:X 09 Dec 13:32:56.596 # +vote-for-leader 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 1 1937:X 09 Dec 13:32:56.639 # +odown master mymaster 192.168.200.140 6382 #quorum 3/2 1937:X 09 Dec 13:32:56.639 # Next failover delay: I will not start a failover before Mon Dec 9 13:38:56 2019 1937:X 09 Dec 13:32:56.935 # +config-update-from sentinel 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 192.168.200.140 26380 @ mymaster 192.168.200.140 6382 1937:X 09 Dec 13:32:56.935 # +switch-master mymaster 192.168.200.140 6382 192.168.200.140 6384 1937:X 09 Dec 13:32:56.935 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6384 1937:X 09 Dec 13:32:56.935 * +slave slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384 1937:X 09 Dec 13:33:26.968 # +sdown slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384
发现master从6382换成了6384,目前有6383一个从节点。
[root@node01 /home/software/redis-3.2.11]# redis-cli -p 6384 127.0.0.1:6384> info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.200.140,port=6383,state=online,offset=26451,lag=0 master_repl_offset:26741 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:26740
(5)将6382节点恢复,发现它会作为从节点挂接到新的主节点6383上。
1931:X 09 Dec 13:36:10.239 * +convert-to-slave slave 192.168.200.140:6382 192.168.200.140 6382 @ mymaster 192.168.200.140 6384
继续登录6384,发现6382变成了salve。
[root@node01 /home/software/redis-3.2.11]# redis-cli -p 6384 127.0.0.1:6384> info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.200.140,port=6383,state=online,offset=49089,lag=1 slave1:ip=192.168.200.140,port=6382,state=online,offset=49234,lag=0 master_repl_offset:49234 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:49233
哨兵API的操作
有了哨兵了,可以通过连接JedisSentinelPool,来连接哨兵集群,然后通过它来获取到Jedis实例对象,这个对象就是对外提供服务的master节点。
package com.boe; import java.util.HashSet; import java.util.Set; import org.junit.Test; import redis.clients.jedis.HostAndPort; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisSentinelPool; public class SentinelTest { @Test public void sentinel(){ //多个哨兵之间没有监控关系,顺序遍历,哪个能通就走哪个,不通,再检查下一个哨兵 Set<String> sentinels = new HashSet<String>(); sentinels.add(new HostAndPort("192.168.200.140",26379).toString()); sentinels.add(new HostAndPort("192.168.200.140",26380).toString()); sentinels.add(new HostAndPort("192.168.200.140",26381).toString()); JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels); //这一句很有用,能获取到是否有master节点宕机 System.out.println("当前master:" + pool.getCurrentHostMaster()); //通过哨兵获取 jedis 连接的就是master Jedis jedis = pool.getResource(); //jedis.auth("123456"); jedis.set("name", "messi"); System.out.println(jedis.get("name")); } }
现在master节点是6384,它不宕机的情况下,是可以对外提供服务的。

查看redis,数据三个节点均有。
127.0.0.1:6384> get name "messi"
现在把6384给它宕机,继续使用上述哨兵来连接 ,修改代码,将set的key-value做修改,然后尝试连接,发现master变成了6382。

哨兵日志
1931:X 09 Dec 13:40:21.218 # +sdown master mymaster 192.168.200.140 6384 1931:X 09 Dec 13:40:21.302 # +new-epoch 2 1931:X 09 Dec 13:40:21.320 # +vote-for-leader 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 2 1931:X 09 Dec 13:40:21.948 # +config-update-from sentinel 931e5386f5d0e31a70cc14a5aa418d68fb46feb4 192.168.200.140 26380 @ mymaster 192.168.200.140 6384 1931:X 09 Dec 13:40:21.948 # +switch-master mymaster 192.168.200.140 6384 192.168.200.140 6382 1931:X 09 Dec 13:40:21.948 * +slave slave 192.168.200.140:6383 192.168.200.140 6383 @ mymaster 192.168.200.140 6382 1931:X 09 Dec 13:40:21.948 * +slave slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382 1931:X 09 Dec 13:40:52.013 # +sdown slave 192.168.200.140:6384 192.168.200.140 6384 @ mymaster 192.168.200.140 6382
以上是对分片高可用,以及哨兵集群的整理,记录一下后续查看用,后面继续补充redis-cluster的相关内容。
参考博文
(1)https://blog.csdn.net/mysqldba23/article/details/68066322 info replication详解
(2)https://www.cnblogs.com/fu-yong/p/9252837.html 哨兵
(3)https://blog.csdn.net/u012240455/article/details/81843714 哨兵