一.正则表达式的使用场景:
上传文件类型的判断,电子邮件的判断,电话号码的判断,文本的搜索与替换。
二.正则表达式的语法规则:
1.行定位符:
^表示行的开始,$表示行的结尾
^tm
可以匹配 tm equal Tomorrow Moon
不匹配 Tomorrow Moon equal tm
tm$
可以匹配后者
tm
可以匹配任意字符串
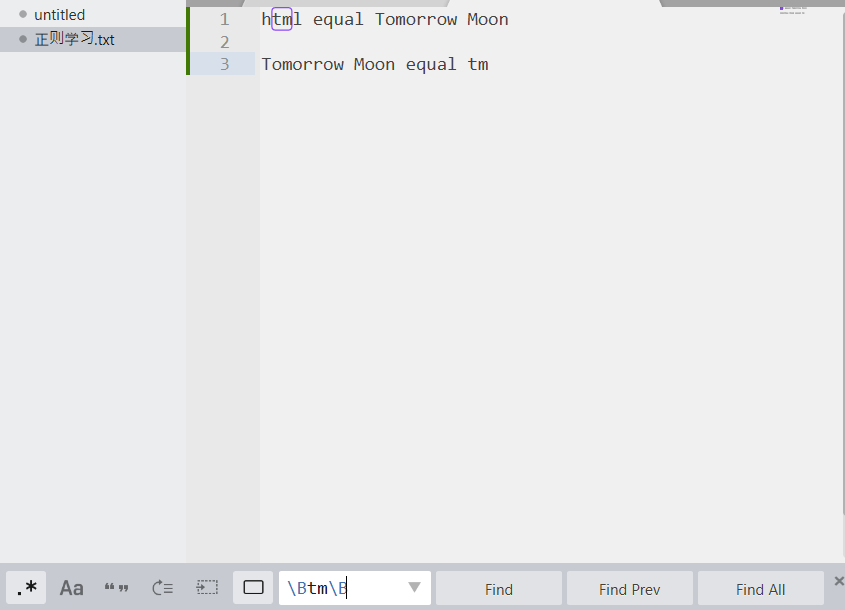
2.单词定界符(\b、\B)
上面的定位符,如果匹配的只是tm,html和utmost也能匹配出来,如果只是要找tm这个单词,使用\b表示查找的是一个完整的单词
\btm\b

大写\B与\b相反,匹配的子串不能是一个完整的单词,而是其他单词或子串的一部分
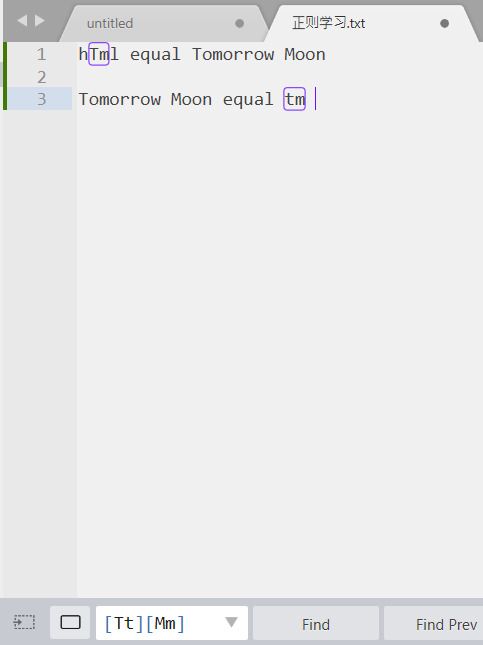
3.字符类([])
正则表达式区分大小写,如果需要忽略的话,可以使用方括号[],一个方括号匹配一个字符,如果
[Tt][Mm]
则可以匹配不区分大小写的tm
POSIX风格的预定义字符类
[[:digit:]] //任何数字 [[:alnum:]] //任何字母和数字 [[:alpha:]] //任何字母 [[:blank:]] //任何空白字符 [[:xdigit:]] //任何十六进制的数字,相当于[0-9a-fA-F] [[:punct:]] //任何标点符号 [[:print:]] //所有的可打印字符,包括空白字符 [[:space:]] //空白字符(空格、换行符、换页符、回车符、水平制表符) [[:graph:]] //所有的可打印字符,不包括空白符 [[:upper:]] //所有大写字母 [[:lower:]] //所有小写字母 [[:cntrl:]] //所有控制字符
PCRE的预定义字符类使用反斜线表示
4.选择字符(|)
[]只能匹配单个字符,|可以匹配任意长度的字符串,使用[]时候,配合连字符-一起使用,比如[a-d]表a或b或c或d,又如T|tM|m,表以字母T或t开头,后面跟一个字母M或m。
5.连字符[-]
[a-e]
可以标志字母的范围,上述表示a到e的字符
[a-zA-Z]
标志a到e的所有大小写
注意: sublime text3编辑器
sublime text3编辑器

atom编辑器
要打开大小写功能。
6.排除字符([^])
正则表达式提供“^”表示不符合的字符,^一般放在[]中
[^a-v]
表示26字母中不包含a到v的字母
[^1-5]
表示不包含1到5的数字
[^a-zA-Z]
表示开头不含字母的匹配项
7.限定符(?*+{n,m})
| 限定符 | 说明 |
| * | 匹配前面子表达式0次或多次,如
zo* 能匹配"z"以及"zoo",猜测是o匹配零次,z匹配也可以,*等价于{0,} |
| + | 匹配前面的子表达式一次或多次。例如'zo+'能匹配"zo”以及"zoo", 但不能匹配"z"。+等价于{1,} |
| ? | 匹配前面的子表达式零次或一次。例如,
do(es)?
可以匹配do或does中的do,?等价于{0,1} |
| {n} | n是一个非负整数。匹配确定的n次。例如, o{2}
匹配确定的n次,如匹配o两次,可以匹配food中的o,但不能匹配pop中的o |
| {n,} | 至少匹配n次,如
o{2,}
不能匹配pop中的o,可以匹配fooooooooood中的所有o,但不能匹配pop中的o |
| {n,m} | m和n都是非负整数,其中n<=m,最少匹配n次,最多匹配m次,如
o{1,3}
将匹配foooooood前三个o, o{0,1}
等价于0? |
8.点字符(.)
.字符可以匹配除了换行符意外任意一个字符,要匹配以s开头t结尾并且中间包含一个字母的单词,格式如下:
^s.t$
要匹配一个单词,第一个字母为r,第3个字母为s,最后一个字母为t。
正确的正则表达式为
^r.s.*t$
9.转义字符(\)
就是将" " " ," ' " ,"\" , "?" 变为普通的字符
[0-9]{1,3}(\.[0-9]{1,3}){3} // 匹配127.0.0.1
10.反斜线(\)
\a 警报
\b 退格
\c Escape 即<ESC>
\cx 匹配由x指明的控制字符
\f 匹配一个换页符
\n 匹配一个换行符
\r 匹配一个回车符
\t 匹配一个制表符
\v 匹配一个垂直制表符
\xhh 十六进制代码
\ddd 八进制代码
\d 任意一个十进制数字
\D 任意一个非十进制数字
\s 匹配任何空白字符,包括空格,制表符,换页符
\S 匹配任何非空白字符
\w 任何一个单词字符
\W 任何一个非单词字符
\b 单词定界符
\B 单词边界之外匹配
\A 匹配字符串起始位置
\Z 匹配字符串的末尾位置或字符串末尾的换行符之前的位置
\z 只匹配字符串的末尾,不考虑任何换行符
\G 从偏移字符的起始位置开始进行匹配,这个偏移地址与传递给preg_match()函数的偏移位置相同
11.圆括号字符(())
作用:
改变限定符()
(my|your)body,没有(),匹配的是my或yourbody
分组,{\.[0-9]{1,3}}{3},分组操作3次
12.反向引用
暂时没搞懂
就这样
2019-12-08 15:32:59