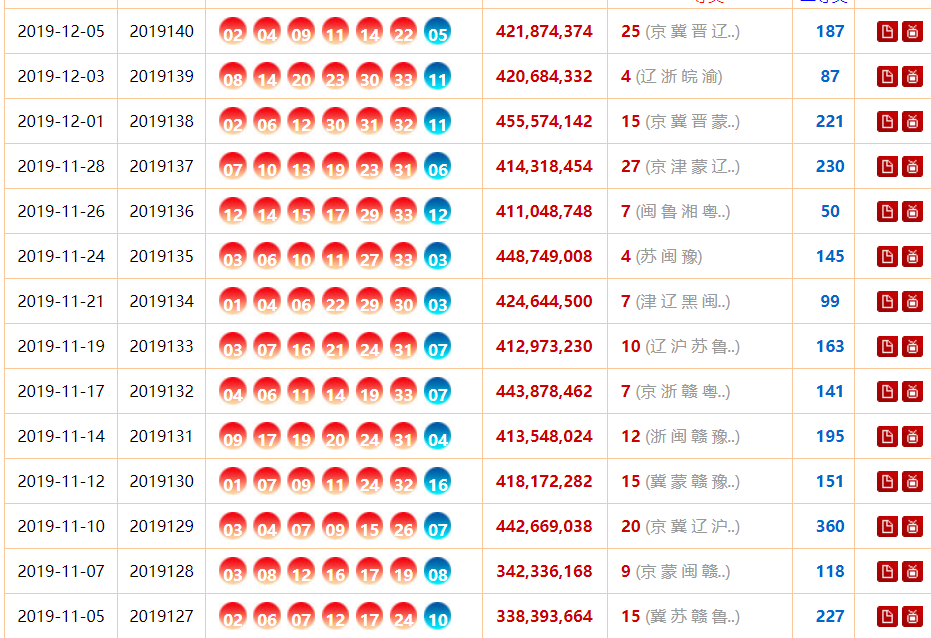
(1) http://www.zhcw.com/ssq/kaijiangshuju/index.shtml?type=0,打开此网址,并通过浏览器中“检查”选项发现此网页数据来源规律;
(2)发现他的这些信息都存在标签<tr>中
(3)代码展示:
爬取 1-5 页的中所有中奖的<开奖时间>、<期号>、<中奖号 码>、<销售额>、 <一等奖>、 <二等奖>信息存储至 CSV 文件。
#将信息爬取出来并存在列表中 form = [] for i in range(1,5): url1 = "http://kaijiang.zhcw.com/zhcw/html/ssq/list_%s.html" %(i) html1 = requests.get(url1).text soup = BeautifulSoup(html1, 'html.parser') tag = soup.find_all('tr') # print(tag) for a in tag[2:len(tag) - 1]: temp = [] for b in a.contents[0:12]: if (b != '\n'): temp += [b.text.strip().replace('\r\n', '').replace(' ', '').replace('\n', ' ')] form.append(temp)
存到csv中:
with open('双色球中奖信息.csv','w',newline='',encoding='utf-8') as f: writer = csv.writer(f) writer.writerow(['开奖日期', '期号', '中奖号码', '销售额(元)', '一等奖', '二等奖']) for a in form: print(a) writer.writerow(a)
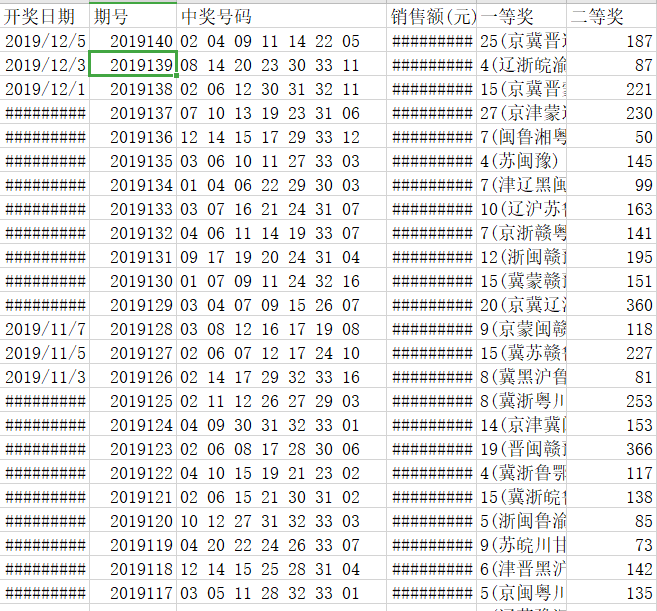
运行结果:
扫描二维码关注公众号,回复:
8106837 查看本文章

总结:
推荐使用lxml解析库,必要时使用html.parser
标签选择筛选功能弱但是速度快
建议使用find()、find_all() 查询匹配单个结果或者多个结果
如果对CSS选择器熟悉建议使用select()
记住常用的获取属性和文本值的方法