一维卷积只在一个维度上进行卷积操作,而二维卷积会在二个维度上同时进行卷积操作。
转载自:https://www.cnblogs.com/LXP-Never/p/10763804.html
一维卷积:tf.layers.conv1d()
一维卷积常用于序列数据,如自然语言处理领域。
tf.layers.conv1d( inputs, filters, kernel_size, strides=1, padding='valid', data_format='channels_last', dilation_rate=1, activation=None, use_bias=True, kernel_initializer=None, bias_initializer=tf.zeros_initializer(), kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, trainable=True, name=None, reuse=None )
参数:[1]
- inputs:张量数据输入,一般是[batch, width, length]
- filters:整数,输出空间的维度,可以理解为卷积核(滤波器)的个数
kernel_size:单个整数或元组/列表,指定1D(一维,一行或者一列)卷积窗口的长度。- strides:单个整数或元组/列表,指定卷积的步长,默认为1
- padding:"SAME" or "VALID" (不区分大小写)是否用0填充,
-
- SAME用0填充;
- VALID不使用0填充,舍去不匹配的多余项。
-
- activation:激活函数
- ues_bias:该层是否使用偏差
- kernel_initializer:卷积核的初始化
- bias_initializer:偏置向量的初始化器
- kernel_regularizer:卷积核的正则化项
- bias_regularizer:偏置的正则化项
- activity_regularizer:输出的正则化函数
- reuse:Boolean,是否使用相同名称重用前一层的权重
- trainable:Boolean,如果True,将变量添加到图collection中
- data_format:一个字符串,一个channels_last(默认)或channels_first。输入中维度的排序。
-
- channels_last:对应于形状的输入(batch, length, channels)
- channels_first:对应于形状输入(batch, channels, length)
-
- name = 取一个名字
返回值:
一维卷积后的张量,
例子
import tensorflow as tf x = tf.get_variable(name="x", shape=[32, 512, 1024], initializer=tf.zeros_initializer) x = tf.layers.conv1d( x, filters=1, # 输出的第三个通道是1 kernel_size=512, # 不用管它是多大,都不影响输出的shape strides=1, padding='same', data_format='channels_last', dilation_rate=1, use_bias=True, bias_initializer=tf.zeros_initializer()) print(x) # Tensor("conv1d/BiasAdd:0", shape=(32, 512, 1), dtype=float32)
解析:
- 输入数据的维度为[batch, data_length, data_width]=[32, 512, 1024],一般输入数据input第一维为batch_size,此处为32,意味着有32个样本,第二维度和第三维度分别表示输入的长和宽(512,1024)
- 一维卷积核是二维的,也有长和宽,长为卷积核的数量kernel_size=512,因为卷积核的数量只有一个,所以宽为输入数据的宽度data_width=1024,所以一维卷积核的shape为[512,1024]
- filteres是卷积核的个数,即输出数据的第三维度。filteres=1,第三维度为1
- 所以卷积后的输出数据大小为[32, 512, 1]
二维卷积常用于计算机视觉、图像处理领域
tf.layers.conv2d( inputs, filters, kernel_size, strides=(1, 1), padding='valid', data_format='channels_last', dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer=None, bias_initializer=tf.zeros_initializer(), kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, trainable=True, name=None, reuse=None )
参数:[4]
inputs:张量输入。一般是[batch, width, length,channel]filters:整数,输出空间的维度,可以理解为卷积核(滤波器)的个数kernel_size:2个整数或元组/列表,指定2D卷积窗口的高度和宽度。可以是单个整数,以指定所有空间维度的相同值。strides:2个整数或元组/列表,指定卷积沿高度和宽度方向的步幅。可以是单个整数,以指定所有空间维度的相同值。- padding:"SAME" or "VALID" (不区分大小写)是否用0填充,
-
- SAME用0填充;
- VALID不使用0填充,舍去不匹配的多余项。
-
data_format:字符串,"channels_last"(默认)或"channels_first"。输入中维度的排序。-
channels_last:对应于具有形状的输入,(batch, height, width, channels)channels_first:对应于具有形状的输入(batch, channels, height, width)
-
activation:激活函数use_bias:Boolean, 该层是否使用偏差项kernel_initializer:卷积核的初始化bias_initializer: 偏置向量的初始化。如果为None,将使用默认初始值设定项kernel_regularizer:卷积核的正则化项bias_regularizer: 偏置矢量的正则化项activity_regularizer:输出的正则化函数trainable:Boolean,如果True,将变量添加到图collection中name:图层的namereuse:Boolean,是否使用相同名称重用前一层的权重
返回:
二维卷积后的张量
例子:
import tensorflow as tf x = tf.get_variable(name="x", shape=[1, 3, 3, 5], initializer=tf.zeros_initializer) x = tf.layers.conv2d( x, filters=1, # 结果的第三个通道是1 kernel_size=[1, 1], # 不用管它是多大,都不影响输出的shape strides=[1, 1], padding='same', data_format='channels_last', use_bias=True, bias_initializer=tf.zeros_initializer()) print(x) # shape=(1, 3, 3, 1)
解析:
- input输入是1张 3*3 大小的图片,图像通道数是5,输入shape=(batch, data_length, data_width, data_channel)
- kernel_size卷积核shape是 1*1,数量filters是1strides步长是[1,1],第一维和第二维分别为长度方向和宽度方向的步长 = 1。
- 最后输出的shape为[1,3,3,1] 的张量,即得到一个3*3的feature map(batch,长,宽,输出通道数)
- 长和宽只和strides有关,最后一个维度 = filters。
卷积层中的输出大小计算
设输入图片大小W,Filter大小F*F,步长为S,padding为P,输出图片的大小为N:
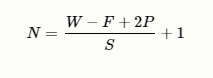
向下取整后再加1。
在Tensoflow中,Padding有2个选型,'SAME'和'VALID' ,下面举例说明差别:
如果 Padding='SAME',输出尺寸为: W / S(向上取整)
import tensorflow as tf input_image = tf.get_variable(shape=[64, 32, 32, 3], dtype=tf.float32, name="input", initializer=tf.zeros_initializer) conv0 = tf.layers.conv2d(input_image, 64, kernel_size=[3, 3], strides=[2, 2], padding='same') # 32/2=16 conv1 = tf.layers.conv2d(input_image, 64, kernel_size=[5, 5], strides=[2, 2], padding='same') # kernel_szie不影响输出尺寸 print(conv0) # shape=(64, 16, 16, 64) print(conv1) # shape=(64, 16, 16, 64)
如果 Padding='VALID',输出尺寸为:(W - F + 1) / S
import tensorflow as tf input_image = tf.get_variable(shape=[64, 32, 32, 3], dtype=tf.float32, name="input", initializer=tf.zeros_initializer) conv0 = tf.layers.conv2d(input_image, 64, kernel_size=[3, 3], strides=[2, 2], padding='valid') # (32-3+1)/2=15 conv1 = tf.layers.conv2d(input_image, 64, kernel_size=[5, 5], strides=[2, 2], padding='valid') # (32-5+1)/2=14 print(conv0) # shape=(64, 15, 15, 64) print(conv1) # shape=(64, 14, 14, 64)