1提取/ 后的数据
sed -e 's=/.*==' do.txt
2
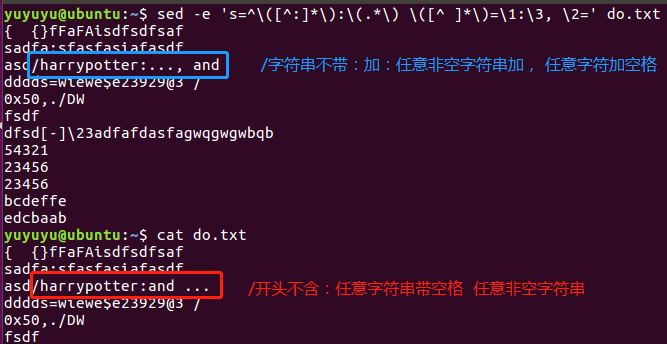
sed -e 's=/.*=='\ -e 's=^\([^:]*\):\(.*\) \([^ ]*\)=\1:\3, \2=' do.txt
第一个-e 的=是区域分割符, 最终这句是把 /后的数据都替换成空

第二个e 是利用三个子模式,来完成排序
's=^\([^:]*\):\(.*\) \([^ ]*\)=\1:\3, \2='
第一个子模式 ^\([^:]*\) 匹配开头的非:字符串
第二个子模式 \(.*\) 匹配任意文字
第三个子模式 \([^ ]*\) 匹配非空白文字
连在一起就是匹配 字符串带:任意文字带 非空白文字
重组排序 \1:\3, \2