目录:
- mongoDB存储引擎
- mongoDB索引
- 索引的属性
- MongoDB查询优化
mongoDB存储引擎:
目前mongoDB的存储引擎分为三种:
1、WiredTiger存储引擎:
a、Concurrency(并发级别):WiredTiger支持文档级别的并发,支持多个客户端同时修改一个文档。
b、Snapshots and Checkpoints(快照与检查点):WiredTiger每60s创建一个检查点(将快照数据写入磁盘),在此之间mongo或服务器宕机便会丢失数据。
c、Journal(检查点中间日志):针对Checkpoint的优化,在创建检查点持久化到磁盘前的数据会先存到Journal上。
若日志空间小于128B则不压缩,大于则启用压缩算法(使用snappy算法压缩数据)。设置压缩算法: storage.wiredTiger.engineConfig.journalCompressor
d、Compression(压缩算法):以消耗CPU资源来减少储空间的消耗。默认使用分块压缩算法压缩集合的数据,snappy算法(前缀压缩)压缩索引。
设置集合压缩算法: storage.wiredTiger.collectionConfig.blockCompressor。
设置索引压缩算法: storage.wiredTiger.indexConfig.prefixCompression。
e、Memory Use(内存使用情况):
在mongo的WiredTiger引擎中有两个内存,(RAM - 1GB) * 0.5、256M;默认使用两者间大的哪一个作为mongo的使用内存。
设置MongoDB可用内存大小单位GB: storage.wiredTiger.engineConfig.cacheSizeGB
2、MMAPv1存储引擎:
a、Journal:同WiredTiger。
b、Record Storage(数据存储):数据连续的存储在磁盘上,当文档需要更大的空间时会涉及数据移动,并且还要更新索引,还会导致磁盘碎片。
c、Memory Use:使用全部内存空间
3、InMemory存储引擎:
a、Concurrency:同WiredTiger。
b、Memory Use:RAM * 0.5 - 1GB
mongoDB索引:
mongoDB的索引主要分为4种:
1、单键索引:在某一特定的属性上建立的索引。
语法:db.collectionName.createIndex({'name':-1}) -1=降序,1=升序
mongoDB的ID就建立了唯一的单键索引,在字段上精确匹配、排序及范围查找都会使用此索引。
2、复合索引:在多个特定的属性上建立的索引。
语法:db.collectionName.createIndex({'name':-1, age:1})
在字段上精确匹配、排序及范围查找都会使用此索引,但与索引的顺序有关。
为了性能考虑,应删除存在与第一个键相同的单键索引。
如:一次查询需要根据name和age查找
若只有name索引,那相同姓名较多的情况也会导致查询效率降低;你可能会说再建一个age的索引不就得嘞,当然不行,因为mongo一次查询只能使用一个索引,所以像这种情况就需要建立复合索引来提升查询效率。
那为啥要删除存在与第一个键相同的单键索引呢,上面说到一次查询只能使用一个索引,而复合索引可以使用前缀查询的方式代替单个的name索引,所以单个的name索引是一个浪费。
3、多键索引:数组上建立的索引。
语法:db.collectionName.createIndex({'address.city':1})
4、哈希索引:
语法:db.collectionName.createIndex({'name':'hashed'})
Hash索引上的入口是均匀分布的,在分片集合中非常有用。
索引的属性:
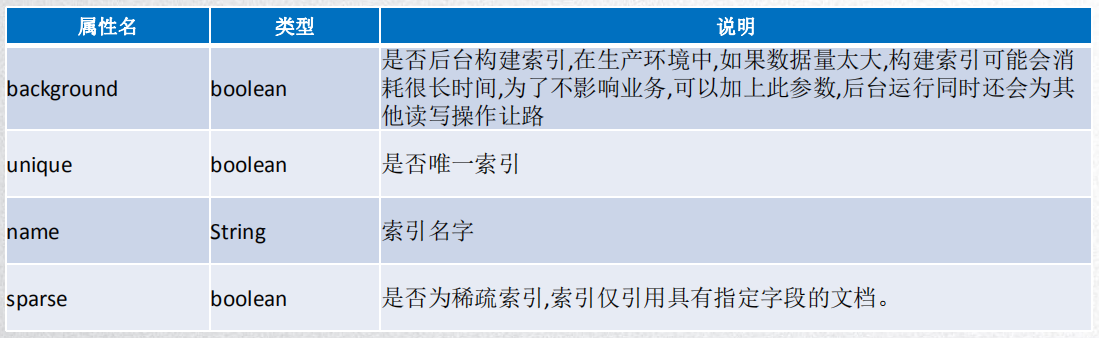
创建索引:
db.collectionName.createIndex( {'name':1}, { 'background':true, 'unique':true, 'name':'indexName', 'sparse':true } )
删除索引:
1、删除指定姓名:db.collectionName.dropIndex('indexName')
2、删除集合上的索引(_id删不掉):db.collectionName.dropIndexs()
3、重建集合上的索引:db.collectionName.reIndex()
4、查询集合上的索引:db.collectionName.getIndexs()
MongoDB查询优化:
1、慢查询定位
开启慢查询:db.setProfilingLevel(n, {m})
n有三个可选值:
- 0;不记录(默认值)。
- 1;记录慢查询日志,为1是必须指定m,也就是查询时间的阀值,单位ms。
- 2;记录所有慢查询日志。
MongoDB的慢查询打开后,日志会存放于system.profile的集合中,其最大分配128K的空间。
可以使用$nartual对慢查询日志排序,如:db.system.profile.find().sort({'$natural':-1}).limit(5)
2、慢查询分析
可通过查询计划explain来分析慢查询,如db.collectionName.find({'age':{'$lt':50}}).explain('executionStats')
explain可选参数:
-
queryPlanner;默认值,表示仅仅展示执行计划信息。
-
executionStats;表示展示执行计划信息同时展示被选中的执行计划的执行情况信息。
-
allPlansExecution;表示展示执行计划信息,并展示被选中的执行计划的执行情况信息,还展示备选的执行计划的执行情况信息。
3、关于索引的使用建议
根据需求建立索引,它有用但也有成本,不要对那些写多读少的建立索引。
尽量保证每个查询的stage都为IXSCAN,追求扫描文档数(totalDocsExamined) = 返回文档数(nReturned)。
MongoDB在一次查询只是用一个索引,如果多条件查询的尽量使用复合索引。
在数据量多的时候建立索引是非常消耗资源的,所以尽量在数据量小的时候就把索引建好。