导语: 磁盘IO利用率是研究存储的同学十分关注的指标,本文介绍了58存储团队在使用rocksdb时针对IO毛刺场景的调优实践,分析了rocksdb compaction限速部分的源码,通过调优,有效地减少IO毛刺,减少对实时读写的影响。
背景
58存储团队自研的分布式KV存储产品WTable采用的存储引擎是开源的rocksdb。rocksdb是LSM Tree的存储结构,在后台进行compaction。
在实践过程中发现,当业务方写入数据量较大,会触发大量的compaction操作,占用较高的IO资源,甚至导致IO 100%,出现IO毛刺,导致实时读写请求延迟变高甚至超时。
本文首先对rocksdb compaction限速部分的源码进行分析,然后介绍WTable在实践中针对IO毛刺场景的调优。
一、源码分析
rocksdb是通过RateLimter类来实现限速功能。RateLimiter有五个参数:
ratebytespersec:每秒flush和compaction的总限速阈值;
refillperiodus:补充token的周期,默认为100ms;
fairness:低优先级请求(compaction)相较高优先级请求(flush)获取token的概率,默认为10;
mode:三个枚举值,读、写、读写,默认是对写请求进行限速;
autotuned:是否开启autotune,默认为不开启。
在普通的rate limiter(autotuned=false)中,token是按照周期分配的,每个周期=refillperiodus,默认值为100ms,则每个周期能分配的token=ratebytespersec100ms/(1000ms)。全局变量availablebytes初始值即为每个周期能分配的token值。请求token时,如果请求的bytes小于availablebytes,直接分配成功并减少相应的availablebytes;如果请求的bytes大于availablebytes,请求进入等待队列,如下图所示,有低优先级请求(low pri)和高优先级请求(high pri)两个待分配token的等待队列,假定每个请求所需的bytes值均为20MB: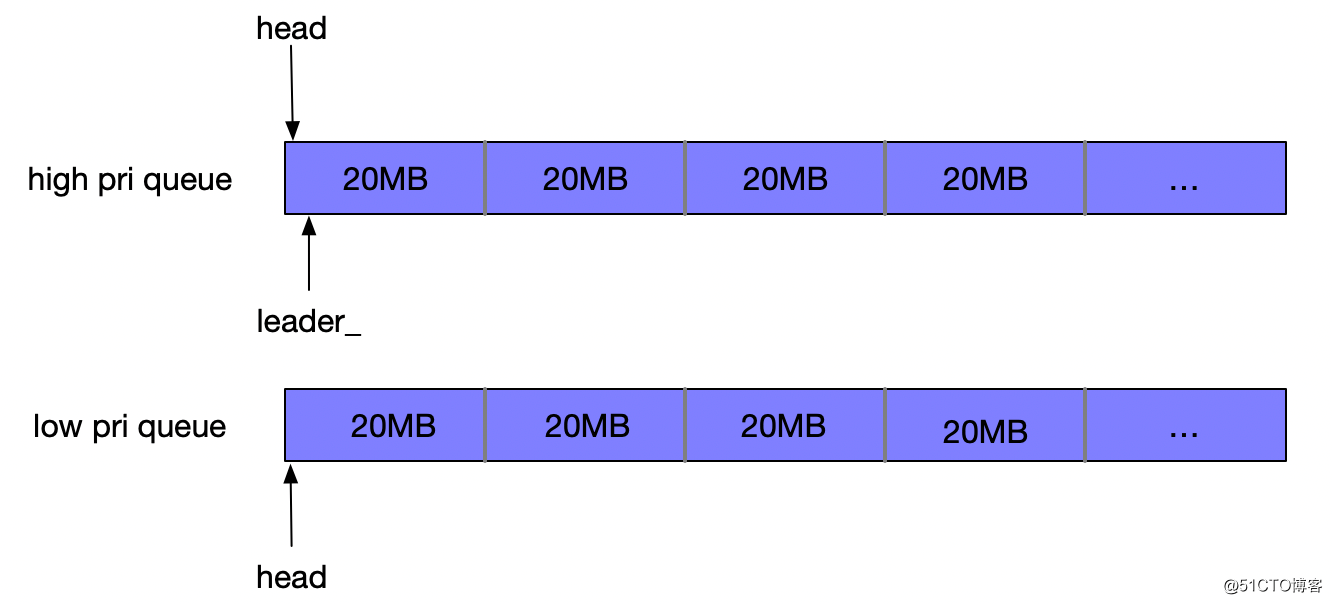
通过竞争,选出一个唯一的leader,非leader的请求进入等待状态;唯一的leader通过变量numdrains记录因availablebytes耗尽而导致等待的周期数量,并等待当前的周期结束,进行refill token操作。
通过上述的流程可以看到,仅有leader请求的线程才能进行refill token操作。在refill流程中,首先更新availablebytes值。并按照fairness概率将token顺序分配给两个队列中等待的请求,low pri queue队列优先获得token分配的概率为1/fairness。每次分配均会减少相应的availablebytes,将对应的请求移出等待队列,并唤起等待的非leader线程成功返回,直至队列清空或availablebytes耗尽。refill流程返回后,需重新竞选leader,新的leader可以是未被分配足够token的旧leader、队列头部未分配token的普通请求(high pri queue头部请求优先)、新来的请求。
假设refill之后,availablebytes更新为50M,并且按照概率选取从high pri queue开始分配token,前两个请求满足条件,分配之后被移出等待队列,availablebytes此时仅剩10M,不满足下一个请求所需的token值,refill流程结束,重新竞选leader,等待下一次refill流程,如下图所示: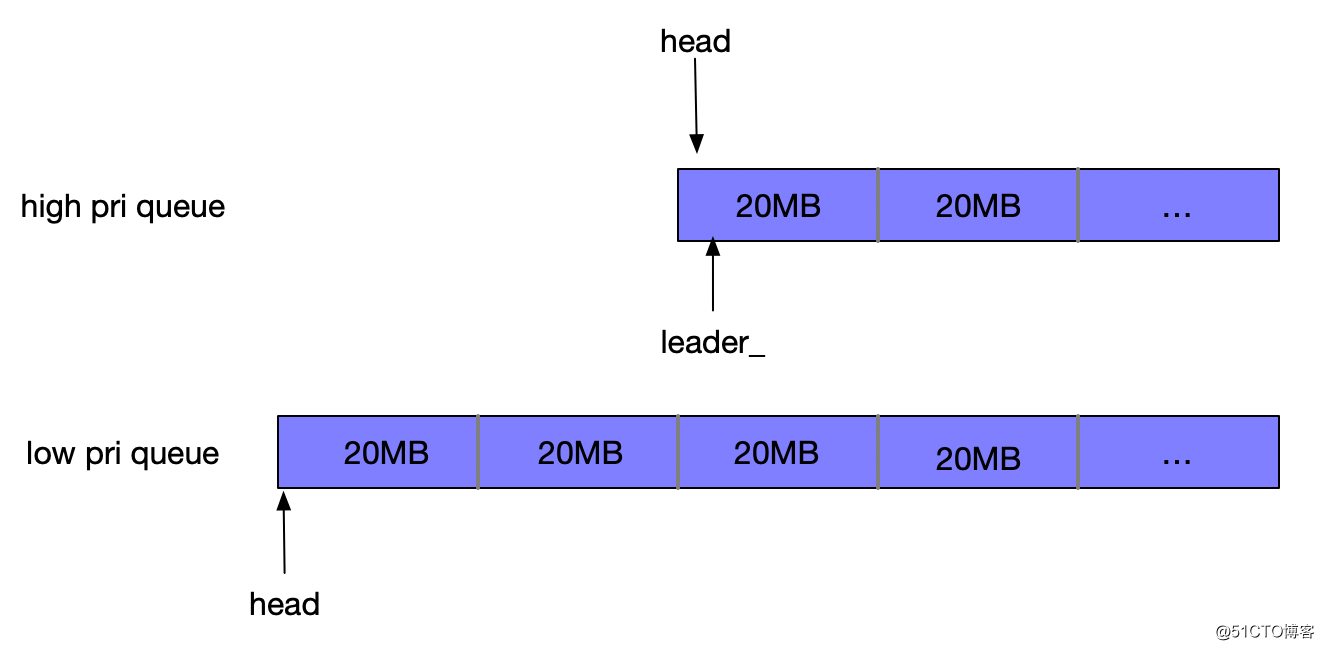
autotune rate limiter在普通rate limiter的基础上,增加了动态调整限速阈值的功能,此时,参数ratebytespersec的含义是限速的上限值。每100个refillperiodus周期调整一次限速阈值,调整的区间为[ratebytespersec/20, ratebytespersec],调整的依据是过去100个周期的因availablebytes耗尽而导致等待的周期的比率(numdrains差值/100 100%),当这个比率低于低水位(50%),限速阈值降低1.05倍,当比率高于高水位(90%),限速阈值上升1.05倍,在高低水位之间,限速阈值不变,如果没有因availablebytes耗尽而导致等待的周期,则限速阈值直接设定为下限值ratebytespersec/20。
二、限速实践
1、普通限速
在初期的实践中,WTable并没有使用autotune模式的rate limiter,仅考虑第一个参数,其他使用默认值。针对某一集群,存在大量离线导入的情况,网卡的流入量如下图所示: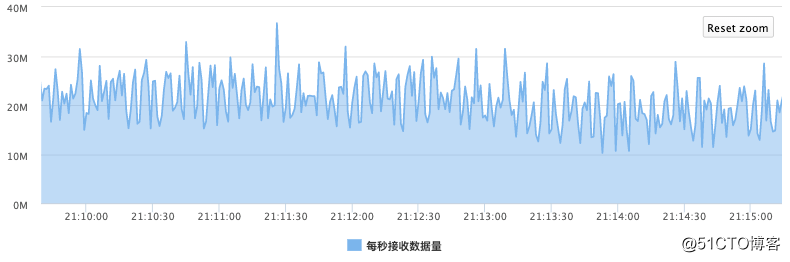
由于写入量较大,rocksdb会生成很多新的sst文件,需要进行大量的compaction,当不进行限速时,经常会出现IO毛刺的情况,如下图所示: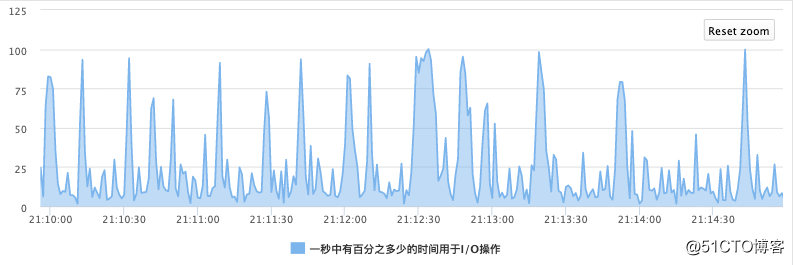
为此,针对该业务的写入场景,进行试验,设定ratebytespersec为250MB时,io毛刺得到明显改善,如下图所示,IO最高在50%左右。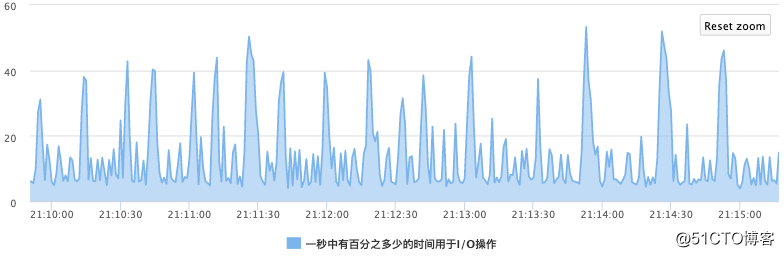
2、auto tune限速
上述设定ratebytespersec为250MB是针对特定集群的实验经验值,并不具备通用性。当业务方的写入量更大时,由于限速的缘故,rocksdb会出现write stall的情况,这对在线读写业务是不能接受的。每个集群都设定一个特定的限速阈值不太现实,也不够通用,为此,进一步测试auto tune方式的限速,希望能在不同集群中使用一套配置。
当开启auto tune(参数autotuned=true)时,参数ratebytespersec的含义是限速的上限值,官方给的参考值是尽量大。
一开始,设定ratebytespersec为2000MB,但是发现并没有起到限速的效果,通过上述的源码分析,发现限速阈值的调整的区间为[ratebytespersec/20, ratebytespersec],
因此当ratebytespersec太大时,限速阈值的下限值仍较大,并不能起到真正的限速作用。在后续的实践中,将ratebytespersec设定为1000M,此时的下限值为50M,既能起到限速的作用,解决了io毛刺的问题,又能动态调整限速阈值,避免write stall。这是一个较为通用的配置,在多种写入场景下均可使用,方便部署运维。
其他
rocksdb的参数非常之多,我们可以从另一个角度来考虑io毛刺的问题:减少compaction次数。比如,配置sst文件大一些,可以一定程度减少compaction的次数,但是compaction不及时也会引起老的数据不能及时清除,导致空间放大,这就需要根据业务方的场景进行取舍了。
另外,我们也在尝试通过直接向rocksdb插入sst文件的方式来减轻大量离线导入对实时读写的影响,敬请期待!
参考文献:https://github.com/facebook/rocksdb/wiki
作者:江守超,58集团高级存储工程师,负责分布式KV存储系统WTable开发与优化。
