HBase的Compaction操作一般都是表粒度的,该操作会将合并HStore下的storefile文件,具体应该合并哪些storefile文件则是由compaction的筛选算法决定的。
解析compact源码时可以看到待合并的文件集合是包装在CompactContext中,compact请求会包装成requestCompact,经层层调用后,在CompactSplitThread的requestCompactionInternal中完成compactContext的构造并提交线程池去执行。
从requestCompactionInternal中开始跟读代码,可以看到CompactionContext的构造以HStore为粒度,在HStore的requestCompaction中完成,把与compact文件筛选相关的逻辑列出如下:
public CompactionContext requestCompaction(int priority, CompactionRequest baseRequest)
throws IOException {
CompactionContext compacion = storeEngine.createCompaction();
CompactionRequest request = null;
this.lock.readLock().lock();
try {
synchronized (filesCompacting) {
//处理coprocessor;
if (!compaction.hasSelection()) {
try {
compaction.select(this.filesCompacting, isUserCompaction, mayUseOffPeak
forceMajor && filesCompacting.isEmpty());
} catch (IOException e) {
.......
}
}
request = compaction.getRequest();
final Collection<StoreFile> selectedFiles = request.getFiles();
if (selectedFiles.isEmpty()) {
return null;
}
addToCompactingFiles(selectedFiles);
} finally {
this.lock.readLock().unlock();
}
}
return compaction;
}介绍这两个算法前,首先说明每个storefile文件中都定义了一个sequence id,用于标识该文件的“新旧”,越新创建出来的storefile,其sequence id值越大,反之亦然。
所谓的compaction筛选算法可以建模为以下的一个问题:
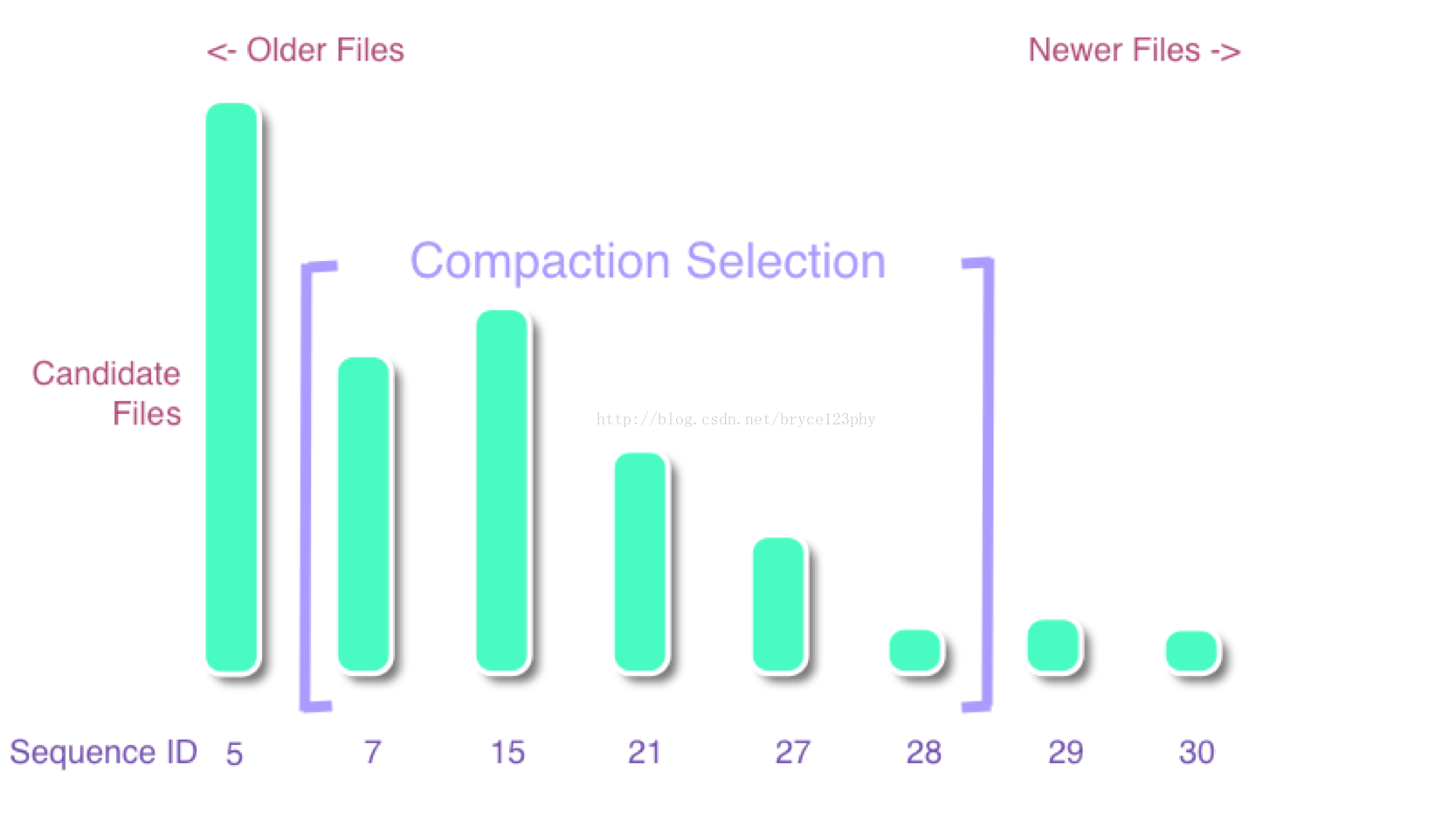
图中的每个数字表示了文件的sequence id,数字越大,则文件越新,很有可能刚刚flush而成,意味着文件size也可能越小。这样的文件是compact时优先选择,因此store下的storefile文件会依据sequence从小到大排序,依次标记为f[0]、f[1]。。。。f[n-1],筛选策略就是要确定一个连续范围[start, end]内的storefile参与compact。
compact的目的是减少文件数量和删除无用的数据,优化读性能,hbase的compact实现基本上是将原文件的内容重写一份到新的文件,如果文件过大意味着compact的时间长,compact过程中产生的io放大越明显,因此文件筛选的准则是用最小的IO代价去减少最多的文件数。
compaction有两个先决条件:
1、所有storeFile按照顺序进行排序(此顺序为:老文件在前,新文件在后。此外BulkLoad进来的文件总是排在hbase内部生成的文件之前);
2、参与compaction的文件必须是连续的;
(一)RatioBasedCompactionPolicy
该方法是默认的compaction算法(pre 0.98),基本思想就是选择在固定end为最后一个文件的前提下(一般情况),从队列头开始滑动寻找start,直到start满足下面的公式:
f[start].size <= ratio * (f[start+1].size +.......+ f[end-1].size)
该算法又称为滑动窗算法,算法过程的图示如下:

算法流程如下:
1、从StoreFile列表中,从老到新(即队列中从头到尾),挑选起始的那个StoreFile,挑选依据是:文件大小不能超过配置中的max size(默认是2G),并且文件大小不能超过后面文件大小的sum*ratio(默认为1.2);
2、决定终止的storeFile,一般就是列表中的最后一个文件,但是要求参与compaction的文件数不能超过配置的max files数目,默认为10个,如果超过了10个,那么终止的storeFile为起始位置+Max files;
hbase中的源代码如下面所示:
int start = 0;
double ratio = comConf.getCompactionRatio(); //获取ratio
if (mayUseOffPeak) {
ratio = comConf.getCompactionRatioOffPeak();
LOG.info("Running an off-peak compaction, selection ratio = " + ratio);
}
// get store file sizes for incremental compacting selection.
final int countOfFiles = candidates.size();
long[] fileSizes = new long[countOfFiles];
long[] sumSize = new long[countOfFiles];
for (int i = countOfFiles - 1; i >= 0; --i) {
StoreFile file = candidates.get(i);
fileSizes[i] = file.getReader().length();
// calculate the sum of fileSizes[i,i+maxFilesToCompact-1) for algo
int tooFar = i + comConf.getMaxFilesToCompact() - 1;
sumSize[i] = fileSizes[i]
+ ((i + 1 < countOfFiles) ? sumSize[i + 1] : 0)
- ((tooFar < countOfFiles) ? fileSizes[tooFar] : 0);
}
while (countOfFiles - start >= comConf.getMinFilesToCompact() &&
fileSizes[start] > Math.max(comConf.getMinCompactSize(),
(long) (sumSize[start + 1] * ratio))) {
++start;
}(二)ExploringCompaction算法
简而言之就是把storefile列表划分成多个子队列,从中找出一个最优子队列,参与compaction:
1、队列中的每一个文件都符合ratio准则;
2、1条件下拥有更多的文件数目;
3、1,2条件下拥有更小的文件大小;
算法流程:
1、从头到尾遍历文件,判断所有符合条件的组合;
2、选择组合内文件数>=minFiles,且<=maxFiles;
3、计算各组合文件的总大小size,选择组合size<=MaxCompactSize,且>=minCompactSize;
4、每个组合里面的每一个文件大小都必须满足FileSize(i)<=(sum(0,N,FileSize(_)) - FileSize(i))*ration,意义在于抛去很大的文件,每次compact时应该尽量合并一些尺寸较小的文件;
5、满足以上1-4条件的组合里面选择文件数最多,文件数一样多时进一步选择文件总size最小的,目的在于尽可能多地合并文件并且因compact带来的IO压力越小越好;
算法的核心代码列举在下面:
for (int start = 0; start < candidates.size(); start++) {
for (int currentEnd = start + minFiles - 1;
currentEnd < candidates.size(); currentEnd++) {
List<StoreFile> potentialMatchFiles = candidates.subList(start, currentEnd + 1);
if (potentialMatchFiles.size() < minFiles) {
continue;
}
if (potentialMatchFiles.size() > maxFiles) {
continue;
}
long size = getTotalStoreSize(potentialMatchFiles);
if (mightBeStuck && size < smallestSize) {
smallest = potentialMatchFiles;
smallestSize = size;
}
if (size > comConf.getMaxCompactSize()) {
continue;
}
++opts;
if (size >= comConf.getMinCompactSize()
&& !filesInRatio(potentialMatchFiles, currentRatio)) {
continue;
}
++optsInRatio;
if (isBetterSelection(bestSelection, bestSize, potentialMatchFiles, size, mightBeStuck)) {
bestSelection = potentialMatchFiles;
bestSize = size;
bestStart = start;
}
}
}不同于RatioBasedCompactionPolicy简单地从头到尾遍历storeFiles列表,遇到符合ratio条件的组合就执行compaction,exploringCompaction会在遍历的同时记录下当前最优的组合,最后从中选举出全局最优的storefiles组合作为compacion列表。前者对于连续写入不断flush memstore形成storeFile的场景是合适的,但是如果存在bulk-load导入的storeFile,由于bulkLoad文件的sequence id是-1,导致在ratioBased的场景下将一直无法参与compact,compact陷入局部最优。
(三)StripeCompactionPolicy算法
StripeCompactionPolicy算法是应用在StripeStoreEngine上的compact策略,上面的两种compact策略只有一个参数ratio可以调控compact,Stripe方法在exploring方法的基础上做了一定的改进,可以更细粒度地调控compact。
stripeCompaction的设计思路来源于levelDB和cassandra的level compact,如下图是cassandra中sstables的一个分层展示:

分层compact中将所有的文件分成多个层,最顶层的叫L0,其下分别是L1、L2依此类推,同一层内各个数据文件覆盖的rowkey区间不会重叠,相邻层之间的数据文件可以进行compaction,由于区间不重叠每个key处于哪个数据文件是确定的,因此compact过程中,只需部分文件参与即可,而不需要所有文件参与,有助于提高compaction执行效率。新写入的数据会首先落到L0层,从L0层向下依次执行合并。
stripe compaction方案借鉴了上述方法,但是只有两层,level 0和level 1,随着数据的写入,memstore flush形成的hfile会首先落到level 0层,一旦level 0层的文件数量超过了用户的设置值,则将这些文件写入到level 1层,level 1层的数据按照rowkey覆盖的范围划分成多个互不重叠的区间,每个区间称为stripe,level 0的数据写入时会首先读出hfile的KVs,然后根据key定位到具体的stripe并将数据插入。l0层与l1层的compact主要代码如下:
public StripeCompactionRequest selectCompaction(StripeInformationProvider si,
List<StoreFile> filesCompacting, boolean isOffpeak) throws IOException {
// 特殊情况处理&条件判断
// 处理l0层stripe
boolean canDropDeletesNoL0 = l0Files.size() == 0;
if (shouldCompactL0) {
if (!canDropDeletesNoL0) {
StripeCompactionRequest result = selectSingleStripeCompaction(
si, true, canDropDeletesNoL0, isOffpeak);
if (result != null) return result;
}
LOG.debug("Selecting L0 compaction with " + l0Files.size() + " files");
return new BoundaryStripeCompactionRequest(l0Files, si.getStripeBoundaries());
}
// 处理已经被标记为删除的stripe
StripeCompactionRequest result = selectExpiredMergeCompaction(si, canDropDeletesNoL0);
if (result != null) return result;
// 处理l1层的各个stripe
return selectSingleStripeCompaction(si, false, canDropDeletesNoL0, isOffpeak);
}(四)DateTieredCompactionPolicy
新的1.3版本HBase增加了基于时间戳的分层compact策略,该方法借鉴自Cassandra,基本思想就是将数据按时间戳分区,使得新老数据在不同的分区,compact行为在不同的分区内发生,这样相当于把compact也按时间戳进行了拆分,好处之一就是提高了按时间读取数据时候的效率,因为从指定的时间分区就可以获取数据,而不再需要遍历所有的文件进行查找。下图所示是cassandra上的流程图示,图片借鉴自Spotify:

上图所示是一个DateTieredCompaction随时间流逝所发生的compact行为示例。图中从上往下时间递增一小时,且每隔一小时会生成新的时间窗,需要注意的是这里的时间窗不同传统意义上随时间向前滑动的时间窗,而是定期产生的新的时间窗,当前时刻的数据总是写入最新形成的时间窗内。
随着新的时间窗口不断生成,老的时间窗口会被合并形成更大的时间窗口,这个值可以由用户来调配,上图中的示例是4,也就是说当某一层的时间窗口到达4的时候,如果有第五个相同尺寸的时间窗形成,那么将会触发前四个时间窗的合并,如上图中所示,最后一个1-hour时间窗形成的时候,前面4个1-hour时间窗合并形成一个4-hour时间窗。
DateTieredPolicy compaction发生时将会依据hfile的age,将age落到相同时间窗内的hfile作为一组进行合并,所有hfile中的最大timestamp始终落在最新的时间窗内。