背景
数据少的时候我们一眼就可以得出相应的结论,但是数据大量的情况下,我们可能无法快速得到想要的结论,因此可以借助数据可视化把我们想要表达的东西很直观的呈现出来。在打卡工具里面我一共写了四张图表,分别是各月的每日下班时间折线图,每月的总加班时长柱状图,加班等级柱状图,加班等级占比饼图。
技术概览
- matplotlib.pyplot
- pandas
- numpy
- datetime
具体实现
创建图表我是写在lib库里,需要处理的数据通过构造函数传递进来。
class createChart(object):
def __init__(self,df=None):
self.df = df为了创建上文提到的四种图表,原始数据还不够,因此我们要先处理一下,我们需要加班等级和加班时长这两个新列。
self.df['timeDelta'] = ''#新增加班时长一列
self.df['level'] = ''#新增加班等级一列
加班等级简单,只需要在for循环里if...elif...就可以实现。这里各加班时间等级的分类没有考虑早上8点到18点之间的,因为这种情况太特殊了,我这里比较少见,希望有这种情况的兄弟姐妹珍重。。。
time = int(self.df['work_time'][index].split(':')[0])
if int(self.df['week'][index]) == 6 or int(self.df['week'][index]) == 0:
self.df['level'][index] = 'weekend'
elif 18 <= time <= 19:
self.df['level'][index] = 'normal'
elif 19 < time <= 21:
self.df['level'][index] = 'overtime'
elif 21 < time <= 23:
self.df['level'][index] = 'hard'
elif 0 <= time <= 2:
self.df['level'][index] = 'terrible'
elif 2 < time <= 8:
self.df['level'][index] = 'hell'
加班时长的话用到datetime计算两个时间段的间隔秒数,这里要考虑三种情况,分别是正常当天下班的,还有周末加班的,以及次日下班的。新增完这两列的数据如下图。
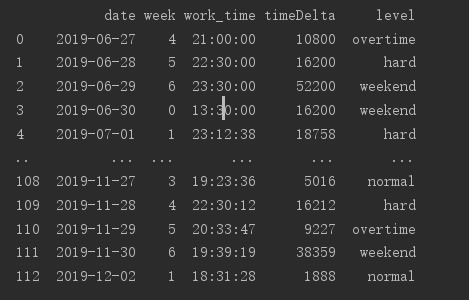
for index in range(len(self.df)):
i = self.df['work_time'][index].split(':')
#次日下班
if 0 <= int(i[0]) <= 8 and 0<int(self.df['week'][index])<6:
t = datetime.datetime(1900, 1, 2, int(i[0]), int(i[1]), int(i[2]))
start = datetime.datetime(1900, 1, 1, 18, 0, 0)
#周末加班
elif int(self.df['week'][index]) == 6 or int(self.df['week'][index]) == 0:
t = datetime.datetime(1900, 1, 1, int(i[0]), int(i[1]), int(i[2]))
start = datetime.datetime(1900, 1, 1, 9, 0, 0)
#正常当天下班
else:
t = datetime.datetime(1900, 1, 1, int(i[0]), int(i[1]), int(i[2]))
start = datetime.datetime(1900, 1, 1, 18, 0, 0)
delta = (t - start).total_seconds()
self.df['timeDelta'][index] = delta
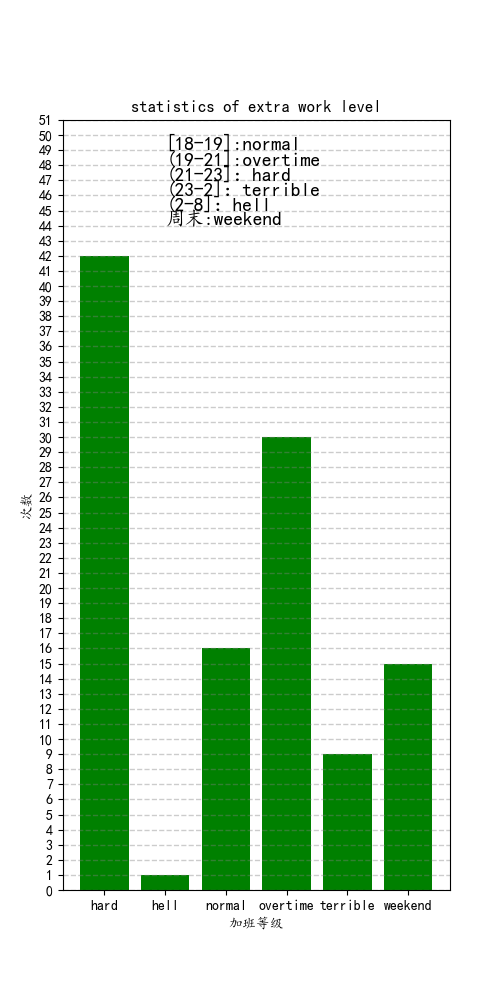
柱状图(bar)和饼图(pie)都只需要用到pandas的分组运算——groupby,这个方法就是把上图的数据按照等级进行分组,再进行count()计算出各分组的个数,该数据如下图。
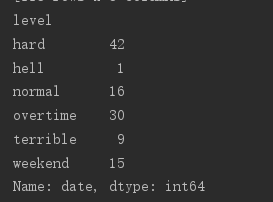
freq = self.df['date'].groupby(self.df['level']).count()
#列表解析式,生成图表纵坐标数据列表
y = [i for i in freq]
#新建一张宽5英寸,高10英寸的图片
plt.figure(figsize=[5, 10])
#freq的索引值作为横坐标,数据作为纵坐标,颜色为绿色
plt.bar(freq.index,y,color='g')
#获取纵坐标最高值,纵坐标标签向上增加10英寸,留出空白填写注释
max_level = freq.max()
plt.yticks(range(max_level+10))
#图表标题
plt.title('statistics of extra work level')
#横纵坐标名称
plt.xlabel('加班等级')
plt.ylabel('次数')
#图表里新增纵坐标的网格虚线,虚线间隔为1,颜色灰色,透明度0.4
plt.grid(axis='y',linestyle='--', linewidth=1, color='gray', alpha=0.4)
#注释,介绍加班等级范围
plt.text(1, max_level+7, '[18-19]:normal',fontsize=14)
plt.text(1, max_level+6, '(19-21]:overtime',fontsize=14)
plt.text(1, max_level+5, '(21-23]:hard',fontsize=14)
plt.text(1, max_level+4, '(23-2]:terrible',fontsize=14)
plt.text(1, max_level+3, '(2-8]:hell',fontsize=14)
plt.text(1, max_level+2, '周末:weekend',fontsize=14)
#保存
plt.savefig('level_bar.png')
#调试时候可以直接显示
plt.show()
饼图的explode参数指的是突出一块扇形的位置,因此有可能出现5种情况(有可能某个等级不存在)
plt.figure(figsize=[5,5])
if len(y)==5:
global explode
explode = (0, 0, 0, 0, 0.1)
elif len(y)==4:
explode = (0, 0, 0, 0.1)
elif len(y)==3:
explode = (0, 0, 0.1)
elif len(y)==2:
explode = (0, 0.1)
if len(y)==6:
explode = (0, 0, 0, 0, 0, 0.1)
#startangle :起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起;有阴影;(每一块)离开中心距离;'%1.1f'指小数点前后位数(没有用空格补齐)
plt.pie(y, labels=freq.index,startangle=90,shadow= True,explode = explode,autopct='%1.1f%%')
plt.title('frequency of extra work level')
plt.savefig('level_pie.png')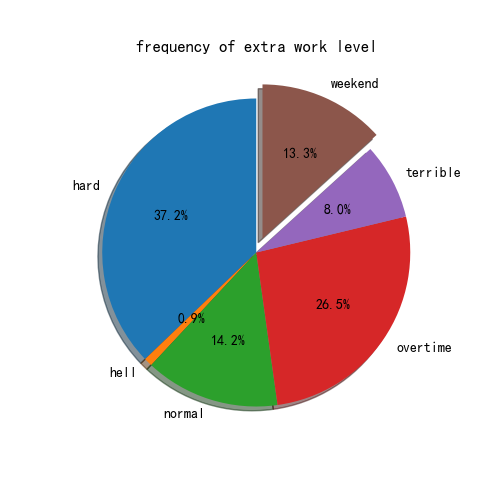
折线图(plot)我用到了匿名函数,字面意思就是不需要函数名的函数。有时候内置函数不够我们用,可以另外写个函数配合groupby使用,达到想要的分组效果。这里就是想要按照date列里的datetime对象的年来分组,因为这个函数很简单,只需要获取datetime对象的年,所以匿名函数派上用场了(简单)。遍历各分组的年生成不同图表,遍历各分组的月份,画不同的折线。
#各年各月每日加班情况折线图
#列表解析式生成因为ui导致的date列字符串类型的数据转成datetime类型的列表
self.df['date'] = [pd.to_datetime(date) for date in self.df['date']]
#数据按照日期中的年份分组
groupedByYear = self.df.groupby(self.df['date'].apply(lambda x: x.year))
#获取分组的索引
year_array = groupedByYear.size().index
#按照年份生成不同的各月每日加班情况折线图
for y in year_array:
plt.figure(figsize=[10, 8])
#groupedByYear是对象,需要get_group()获取真实数据
groupedByYear_df = groupedByYear.get_group(y)
#同理获取按照月份分组后的对象,获取索引,再遍历
grouped = groupedByYear_df.groupby(groupedByYear_df['date'].apply(lambda x:x.month))
month_array = grouped.size().index
for month in month_array:
grouped_df = grouped.get_group(month)
#生成年月日的列表,日作为横坐标
date_list = [date.day for date in grouped_df['date']]
month_list = [date.month for date in grouped_df['date']]
year_list = [date.year for date in grouped_df['date']]
year = year_list[0]
mon = month_list[0]
#创建图例名称
label = str(year) + '-' + str(mon)
time_list = []
#遍历下班时间创建打卡时间的datetime的列表作为纵坐标
for i in grouped_df['work_time'].str.split(':'):
if 0 <= int(i[0]) <= 8:
t = datetime.datetime(1900, 1, 2, int(i[0]), int(i[1]), int(i[2]))
else:
t = datetime.datetime(1900, 1, 1, int(i[0]), int(i[1]), int(i[2]))
time_list.append(t)
plt.plot(date_list, time_list, label=label)
#横坐标标签从1到31,纵坐标按照我们下班的时间早晚顺序。这里另外建横纵坐标标签的原因是假如数据分布不均匀的情况下,图表某些坐标不显示,不是我想要的,所以强制标签显示,并且按照我期望的顺序
plt.xticks(range(1,32),range(1,32))
plt.yticks((datetime.datetime(1900, 1, 1, 12, 00, 00), datetime.datetime(1900, 1, 1, 13, 00, 00),
datetime.datetime(1900, 1, 1, 14, 00, 00),
datetime.datetime(1900, 1, 1, 15, 00, 00), datetime.datetime(1900, 1, 1, 16, 00, 00),
datetime.datetime(1900, 1, 1, 17, 00, 00),
datetime.datetime(1900, 1, 1, 18, 00, 00), datetime.datetime(1900, 1, 1, 19, 00, 00),
datetime.datetime(1900, 1, 1, 20, 00, 00),
datetime.datetime(1900, 1, 1, 21, 00, 00), datetime.datetime(1900, 1, 1, 22, 00, 00),
datetime.datetime(1900, 1, 1, 23, 00, 00),
datetime.datetime(1900, 1, 2, 00, 00, 00), datetime.datetime(1900, 1, 2, 1, 00, 00),
datetime.datetime(1900, 1, 2, 2, 00, 00),
datetime.datetime(1900, 1, 2, 3, 00, 00), datetime.datetime(1900, 1, 2, 4, 00, 00),
datetime.datetime(1900, 1, 2, 5, 00, 00),
datetime.datetime(1900, 1, 2, 6, 00, 00), datetime.datetime(1900, 1, 2, 7, 00, 00),
datetime.datetime(1900, 1, 2, 8, 00, 00),),
('中午12点', '下午1点', '下午2点', '下午3点', '下午4点', '下午5点', '晚上6点', '晚上7点', '晚上8点', '晚上9点', '晚上10点',
'晚上11点', '晚上12点', '次日1点', '次日2点', '次日3点',
'次日4点', '次日5点', '次日6点', '次日7点', '次日8点'))
plt.title('加班情况')
plt.xlabel('日期')
plt.ylabel('下班时间')
plt.grid(axis='y')
#显示图例
plt.legend()
#图片名称跟年份相关,保存为不同文件
picture = str(y)+'level_plot.png'
plt.savefig(picture)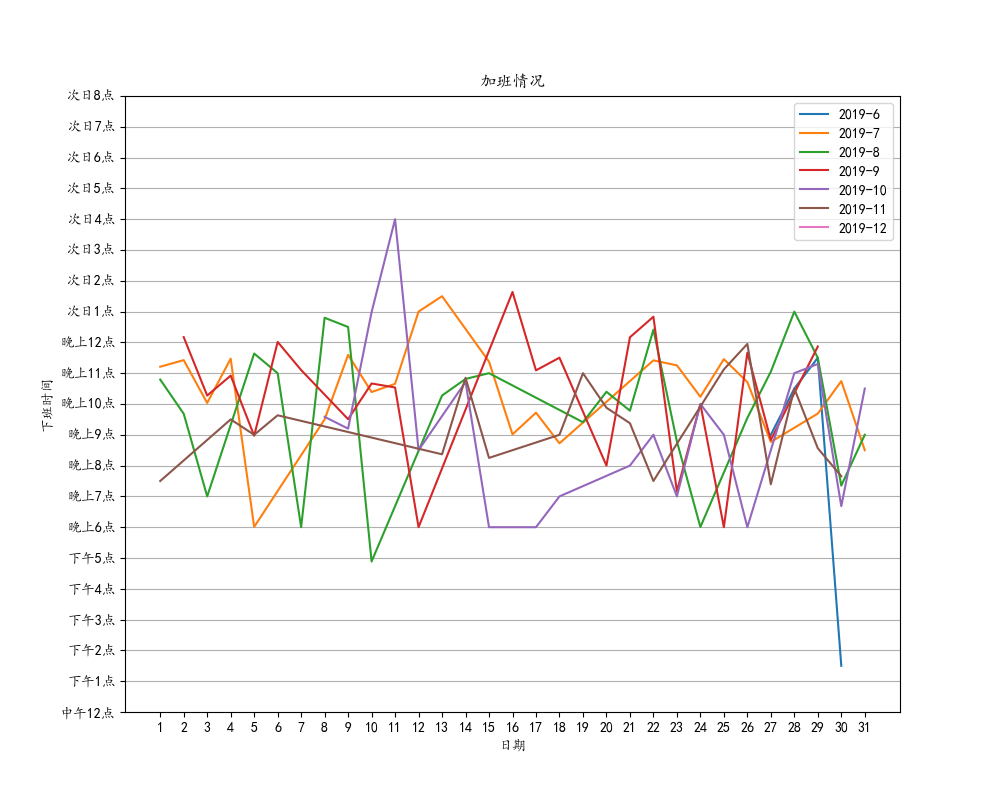
这里用到DataFrame的分组再聚合的概念,把数据先按照年份、月份分组后,再用agg()聚合函数计算时长总和。
#各年每月总加班时长柱状图
plt.figure(figsize=[10, 8])
#count是索引,y是年份
for count,y in enumerate(year_array):
groupedByYear_df = groupedByYear.get_group(y)
grouped = groupedByYear_df.groupby(groupedByYear_df['date'].apply(lambda x: x.month))
month_array = grouped.size().index
#新建字典存放各月加班总时长
delta_dict = {}
for month in month_array:
#分组
grouped_df = grouped.get_group(month)
#聚合
sumbymonth = grouped_df['timeDelta'].agg(np.sum)
delta_dict[month] = sumbymonth
year_list = [date.year for date in grouped_df['date']]
year = year_list[0]
label = str(year)
#字典的key作为横坐标,value是纵坐标,label是图例
plt.bar(delta_dict.keys(),delta_dict.values(),label = label)
#把秒换算成大概的天数,并且在图表的合适的位置显示(经调试)
for k, v in zip(delta_dict.keys(),delta_dict.values()):
hours = v // 3600
plt.text(k - 0.4, v + 1000, "约%dh" % hours,fontsize=14)
plt.xticks(range(13))
plt.title('每月加班总时长统计图')
plt.xlabel('月份')
plt.ylabel('时长')
plt.legend()
plt.grid(axis='y',linestyle='--', linewidth=1, color='gray', alpha=0.4)
plt.savefig('delta_bar.png')
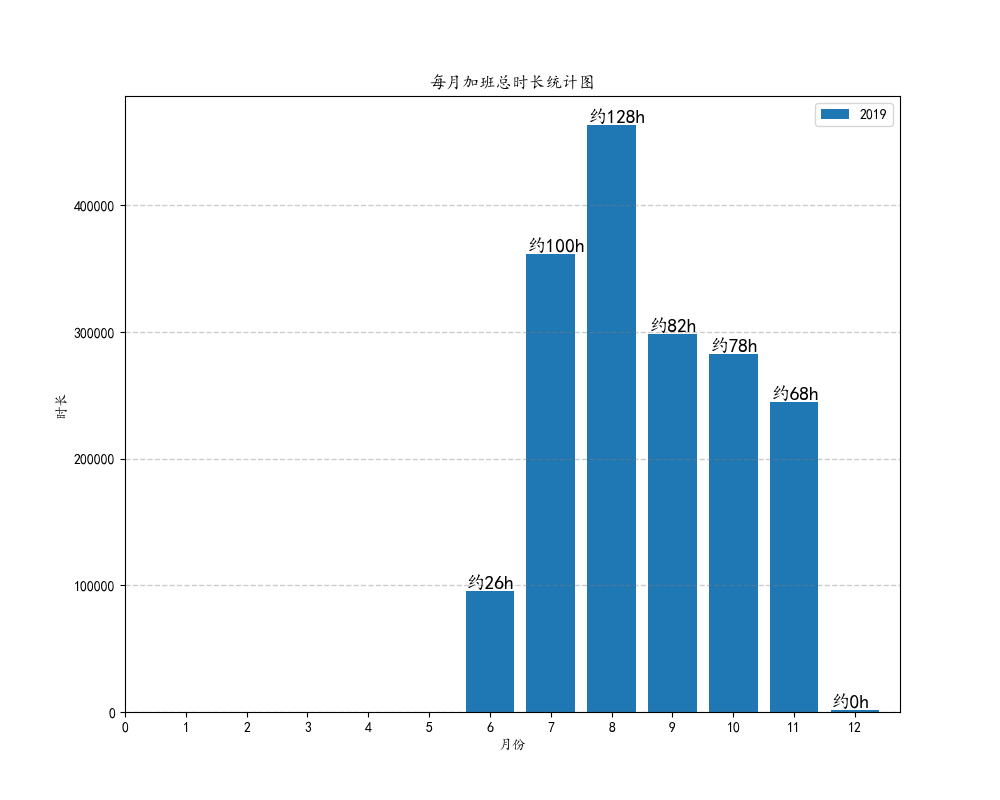
总结
其实数据可视化这部分让我困扰的更多是不知道要怎么去用图表呈现我想表达的结论,可能因为我毕竟不是这个专业的,对数据统计不是很有想法。但是当我规划好之后,后面的代码就水到渠成了,因为网上也确实有很多优秀的资料。然后因为数据是我自己一开始就规划好的,所以也不需要过多的清洗与规整,不过也就是个练手小工具啦哈哈,希望今天的自己比昨天的更加优秀!