本文是《手把手教你用Pytorch-Transformers》的第二篇,主要讲实战
手把手教你用Pytorch-Transformers——部分源码解读及相关说明(一)
一、情感分类任务
这里使用 BertForSequenceClassification 进行情感分类任务,还是用 苏剑林 整理的情感二分类数据集
可以结合之前发的那篇一起看
数据集:https://github.com/bojone/bert4keras/tree/master/examples/datasets
1.用Dataset表示数据集
先放上一些参数设置
# 超参数 hidden_dropout_prob = 0.3 num_labels = 2 learning_rate = 1e-5 weight_decay = 1e-2 epochs = 2 batch_size = 16
继承 PyTorch 的 Dataset ,编写一个类表示数据集,这里我们用字典返回一个样本和它的标签
from torch.utils.data import Dataset import pandas as pd class SentimentDataset(Dataset): def __init__(self, path_to_file): self.dataset = pd.read_csv(path_to_file, sep="\t", names=["text", "label"]) def __len__(self): return len(self.dataset) def __getitem__(self, idx): text = self.dataset.loc[idx, "text"] label = self.dataset.loc[idx, "label"] sample = {"text": text, "label": label} return sample
2.编写模型
Transformers 已经实现好了用来分类的模型,我们这里就不自己编写了,直接使用 BertForSequenceClassification 调用预训练模型
一些自定义的配置可以通过 BertConfig 传递给 BertForSequenceClassification
from transformers import BertConfig, BertForSequenceClassification # 使用GPU # 通过model.to(device)的方式使用 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") config = BertConfig.from_pretrained("bert-base-uncased", num_labels=num_labels, hidden_dropout_prob=hidden_dropout_prob) model = BertForSequenceClassification.from_pretrained("bert-base-uncased", config=config) model.to(device)
想自定义的话可以参考这个类实现,这个BertConfig可以添加自定义的属性,比如添加一个作者啥的
config = BertConfig.from_pretrained("bert-base-uncased", author="DogeCheng")
3.读取数据集
用 DataLoader 得到一个迭代器,每次得到一个 batch_size 的数据

from torch.utils.data import DataLoader data_path = "/data/sentiment/" # 加载数据集 sentiment_train_set = SentimentDataset(data_path + "sentiment.train.data") sentiment_train_loader = DataLoader(sentiment_train_set, batch_size=batch_size, shuffle=True, num_workers=2) sentiment_valid_set = SentimentDataset(data_path + "sentiment.train.data") sentiment_valid_loader = DataLoader(sentiment_valid_set, batch_size=batch_size, shuffle=False, num_workers=2)
4.数据处理
主要实现对文本进行 tokenization 和 padding 的函数
vocab_file = "PyTorch_Pretrained_Model/chinese_wwm_pytorch/vocab.txt" tokenizer = BertTokenizer(vocab_file) def convert_text_to_ids(tokenizer, text, max_len=100): if isinstance(text, str): tokenized_text = tokenizer.encode_plus(text, max_length=max_len, add_special_tokens=True) input_ids = tokenized_text["input_ids"] token_type_ids = tokenized_text["token_type_ids"] elif isinstance(text, list): input_ids = [] token_type_ids = [] for t in text: tokenized_text = tokenizer.encode_plus(t, max_length=max_len, add_special_tokens=True) input_ids.append(tokenized_text["input_ids"]) token_type_ids.append(tokenized_text["token_type_ids"]) else: print("Unexpected input") return input_ids, token_type_ids def seq_padding(tokenizer, X): pad_id = tokenizer.convert_tokens_to_ids("[PAD]") if len(X) <= 1: return X L = [len(x) for x in X] ML = max(L) X = torch.Tensor([x + [pad_id] * (ML - len(x)) if len(x) < ML else x for x in X])return X
5.定义优化器和损失函数
其实 BertForSequenceClassification 已经有了损失函数,可以不用实现,这里展示一个更通用的例子
import torch import torch.nn as nn from transformers import AdamW # 定义优化器和损失函数 # Prepare optimizer and schedule (linear warmup and decay) no_decay = ['bias', 'LayerNorm.weight'] optimizer_grouped_parameters = [ {'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': weight_decay}, {'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0} ] #optimizer = AdamW(model.parameters(), lr=learning_rate) optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate) criterion = nn.CrossEntropyLoss()
6.定义训练和验证函数
PyTorch 不像 Keras 那样调用 fit 就可以了,大多都需要自己实现,为了复用性,这里用函数实现了简单的训练和测试函数
因为 BertForSequenceClassification 里面已经有了一个 CrossEntropyLoss() ,实际可以不用我们刚刚的 criterion,见 train() 函数 中的注释
def train(model, iterator, optimizer, criterion, device): model.train() epoch_loss = 0 epoch_acc = 0 for i, batch in enumerate(iterator): label = batch["label"] text = batch["text"] input_ids, token_type_ids = convert_text_to_ids(tokenizer, text) input_ids = seq_padding(tokenizer, input_ids) token_type_ids = seq_padding(tokenizer, token_type_ids) # 标签形状为 (batch_size, 1) label = label.unsqueeze(1) # 需要 LongTensor input_ids, token_type_ids, label = input_ids.long(), token_type_ids.long(), label.long() # 梯度清零 optimizer.zero_grad() # 迁移到GPU input_ids, token_type_ids, label = input_ids.to(device), token_type_ids.to(device), label.to(device) output = model(input_ids=input_ids, token_type_ids=token_type_ids, labels=label) y_pred_prob = output[1] y_pred_label = y_pred_prob.argmax(dim=1) # 计算loss # 这个 loss 和 output[0] 是一样的 loss = criterion(y_pred_prob.view(-1, 2), label.view(-1)) #loss = output[0] # 计算acc acc = ((y_pred_label == label.view(-1)).sum()).item() # 反向传播 loss.backward() optimizer.step() # epoch 中的 loss 和 acc 累加 epoch_loss += loss.item() epoch_acc += acc if i % 200 == 0: print("current loss:", epoch_loss / (i+1), "\t", "current acc:", epoch_acc / ((i+1)*len(label))) return epoch_loss / len(iterator), epoch_acc / (len(iterator) * iterator.batch_size) def evaluate(model, iterator, criterion, device): model.eval() epoch_loss = 0 epoch_acc = 0 with torch.no_grad(): for _, batch in enumerate(iterator): label = batch["label"] text = batch["text"] input_ids, token_type_ids = convert_text_to_ids(tokenizer, text) input_ids = seq_padding(tokenizer, input_ids) token_type_ids = seq_padding(tokenizer, token_type_ids) label = label.unsqueeze(1) input_ids, token_type_ids, label = input_ids.long(), token_type_ids.long(), label.long() input_ids, token_type_ids, label = input_ids.to(device), token_type_ids.to(device), label.to(device) output = model(input_ids=input_ids, token_type_ids=token_type_ids, labels=label) y_pred_label = output[1].argmax(dim=1) loss = output[0] acc = ((y_pred_label == label.view(-1)).sum()).item() epoch_loss += loss.item() epoch_acc += acc return epoch_loss / len(iterator), epoch_acc / (len(iterator) * iterator.batch_size)
7.开始训练
这里只跑了 2 个 epoch,在验证集上的效果达到了 92 的准确率
# 再测试 for i in range(epochs): train_loss, train_acc = train(model, sentiment_train_loader, optimizer, criterion, device) print("train loss: ", train_loss, "\t", "train acc:", train_acc) valid_loss, valid_acc = evaluate(model, sentiment_valid_loader, criterion, device) print("valid loss: ", valid_loss, "\t", "valid acc:", valid_acc)
第一个 epoch

第二个 epoch
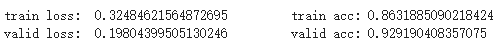
二、TBD
休闲养老了,还有QA任务啥的,看心情填了
