在上一篇文章中(python 内存管理机制—引用计数)中,我们介绍了python内存管理机制中的引用计数,python正是通过它来有效的管理内存。今天来介绍python的垃圾回收,其主要策略是引用计数为主,标记-清除和分代回收为辅助的策略(熟悉java的同学回回忆下,其实这和JVM的策略是有类似之处的)。
引用计数垃圾回收
我们还接着上一篇文章来接着介绍引用计数的相关场景,方便我们来理解python如何通过引用计数来进行垃圾回收。其实通过字面意思,我们应该也不难理解,当一个对象的引用计数变为0时,表示没有对象再使用这个对象,相当于这个对象变成了无用的"垃圾",当python解释器扫描到这个对象时就可以将其回收掉。
我们通过一些例子来看下,可以使python对象的引用计数增加或减少的场景:
# coding=utf-8
"""
~~~~~~~~~~~~~~~~~
@Author:xuanke
@contact: [email protected]
@date: 2019-11-29 19:52
@function: 验证引用计数增加和减少的场景
"""
import sys
def ref_method(str):
print(sys.getrefcount(str))
print("我调用了{}".format(str))
print('方法执行完了')
def ref_count():
# 引用计数增加的场景
print('测试引用计数增加')
a = 'ABC'
print(sys.getrefcount(a))
b = a
print(sys.getrefcount(a))
ref_method(a)
print(sys.getrefcount(a))
c = [1, a, 'abc']
print(sys.getrefcount(a))
# 引用计数减少的场景
print('测试引用计数减少')
del b
print(sys.getrefcount(a))
c.remove(a)
print(sys.getrefcount(a))
del c
print(sys.getrefcount(a))
a = 783
print(sys.getrefcount(a))
if __name__ == '__main__':
ref_count()
运行结果如下:
测试引用计数增加
7
8
10
我调用了ABC
方法执行完了
8
9
测试引用计数减少
8
7
7
4从上面的结果我们得出以下结论:
引用计数增加的场景:
- 对象被创建并赋值给某个变量,比如: a = 'ABC'
- 变量间的相互引用(相当于变量指向了同一个对象),比如:b=a
- 变量作为参数传到函数中。比如:ref_method(a),其实上一篇文章,我们也提过调用getrefcount会使引用计数增加。
- 将对象放到某个容器对象中(列表、元组、字典)。比如:c = [1, a, 'abc']
引用计数减少的场景:
- 当一个变量离开了作用域,比如:函数执行完成时,上面的运行结果中,不知道大家发现没,执行方法前后的引用计数保持不变,这就是因为方法执行完后,对象的引用计数也会减少,如果在方法内打印,则能看到引用计数增加的效果。
- 对象的引用变量被销毁时,比如del a 或者 del b。注意如果del a,再去获取a的引用计数会直接报错。
- 对象被从容器对象中移除,比如:c.remove(a)
- 直接将整个容器销毁,比如: del c
- 对象的引用被赋值给其他对象,相当于变量不指向之前的对象,而是指向了一个新的对象,这种情况,引用计数肯定会发生改变。(排除两个对象默认引用计一致的场景)。
引用计数虽然可以实时的知道某个对象是否可以被回收,但是也有两个缺点:
- 需要额外的空间维护引用计数。
- 遇到有循环引用的对象,无法有效处理。所谓循环引用就是比如:对象A引用了对象B,而对象B又引用了对象A,造成它们两个引用计数都不能减少到0 ,因此不能被回收。
标记-回收垃圾回收
为了解决引用计数法无法解决的循环引用问题,python采用了标记-回收垃圾回收算法,它的整个过程分为两步:
- 标记: 遍历所有的对象,如果是可达的(reachable),也就是还有对象正引用它,那么就标记该对象为可达;
- 清除: 再次遍历所有的对象,如果某个对象没有被标记为可达,则将其回收掉。
需要注意的是在python中可以产生循环引用问题的可能是:列表、字典、用户自定义类的对象、元组等对象,而对于数字字符串这种简单的数据类型,并不会产生循环引用,因此后者并不在标记清除算法的考虑之列。
针对标记-回收垃圾回收的过程,我从网上找了几张图片,方便大家来了解整个过程:
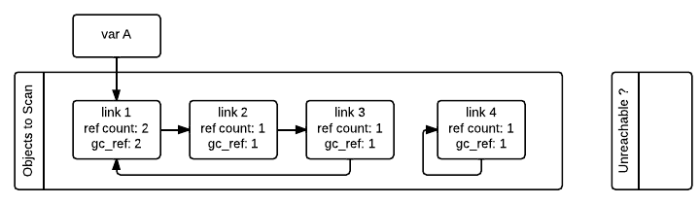
第一张图是初始状态,图片上不仅有ref_count,还有一个gc_ref的值,这个gc_ref其实就是为了来解决引用计数问题的,它是ref_count的一个副本,所以它的初始值和ref_count保持一致。当开始遍历所有对象时,当发现link1引用了link2对象时,会将link2的gc_ref值减少1,如此类推,就得到下图的结果。
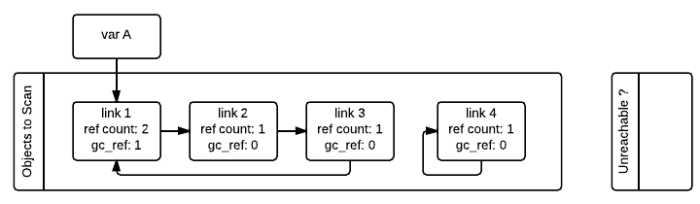
第二张图中我们看到link2、link3、link4的gc_ref都已经为0,当python垃圾回收器再次扫描所有对象时,那么它们就会被标记为GC_TENTATIVELY_UNREACHABLE,同时被移到Unreachable列表中。有同学可能会疑惑为啥link2没有被移到Unreachable列表中,其实它理论上也应该被移到Unreachable列表中,如第三张图所示:
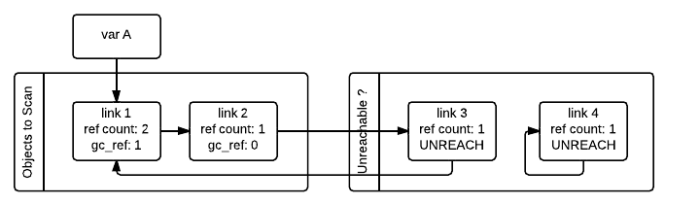
如果python垃圾回收器再次扫描对象时,发现某个对象的ref_count不为0,那么就会将其标记为GC_REACHABLE,表示还正在被引用着,如下图所示的link1就是这种情况。
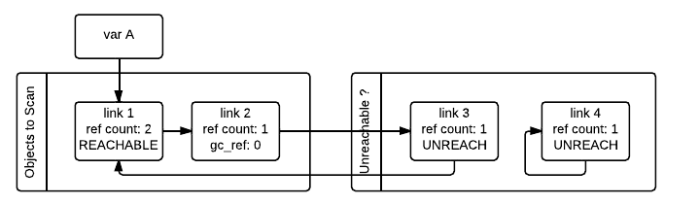
除了将link1标记为可达的之外,python垃圾回收器,还会从当前可达节点依次遍历所有可达的节点,比如从link1可以到达link2和link3,但link3已经被放到Unreachable列表中,因此还需要将link3再移回到Object to Scan列表中,表示对象还是可以触达的。最终的结果如下图所示,只有link4会被回收掉:
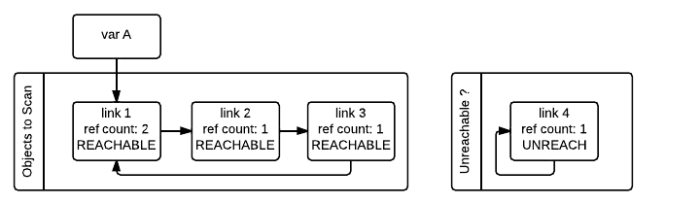
标记-清除法虽然可以解决循环引用的问题,但是缺点也比较明显,就是需要python垃圾回收器对python对象执行两遍扫描,而每次扫描,python解释器就会暂停处理其他事情,等到扫描结束后才能恢复正常。这个过程就好比:图书管理员要对图书馆进行清洁整理,那么将会关闭图书馆,直到收拾干净后才能重新打开图书馆,供同学们使用。
分代垃圾回收
那既然在python垃圾回收过程中,会暂停整个应用程序,有没有更好的优化方案呢?答案是肯定的。在python解释器中,对象的存活时间是不一样的:
- 长时间存活(或一直存活)的对象,它们是内存垃圾的可能性低,可以减少对它们扫描的次数。
- 临时或短时间存活的对象,这种对象比较容易成为内存垃圾,所以得频繁扫描。
- 位于前两种情况的之间的对象。可根据情况进行内存扫描。
这样区分对象后,就可以节省每次扫描的时间(不需要所有对象都扫描),重而能提升垃圾回收的速度。
python中结合着上面列出的三种类型的对象分了三个对象代(0,1,2),它们其实对应了3个链表:每一个新生对象在generation zero中,如果它在一轮gc扫描中活了下来,那么它将被移至generation one,在这一个对象代扫描次数将会减少;如果它又活过了一轮gc,它又将被移至generation two,在这一个对象代对象扫描次数将会更少。
python触发垃圾回收扫码的时机
python解释器只会在触发某个条件时,才会去执行垃圾回收。这个条件就是当python分配对象的次数和取消分配对象的次数(引用计数变为0)做差值高于某个阈值,我们可以通过python提供的方法来查看这个阈值。
def threshold_gc():
# 获取阈值
print(gc.get_threshold())
# 可设置阈值
gc.set_threshold(800, 10, 10)
print(gc.get_threshold())
# 运行结果
(700, 10, 10)
(800, 10, 10)上面程序运行结果中值的含义如下:
- 700是垃圾回收启动的阈值。
- 后面两个10与分代回收有关(上面介绍过python分了三个对象代:0、1、2),第一个10表示每进行10次0代对象扫描,则进行1次1代对象扫描。
- 最后一个10表示每进行10次1代对象扫描,则执行1次2代对象扫描。
此外可以自己根据情况,调用set_threshold()方法来调整垃圾回收的频率。比如:set_threshold(700,10,5),相当于增加了对2代对象的扫描频率。
gc这个库中还有一些很好玩的函数,大家可以了解下(更多方法可以参考官方文档):
def gc_method():
# 启动垃圾回收
gc.enable()
# 停用垃圾回收
gc.disable()
# 手动指定垃圾回收,参数可以指定垃圾回收的代数,不填写参数就是完全的垃圾回收
gc.collect()
# 设置垃圾回收的标志,多用于内存泄漏的检测
gc.set_debug(gc.DEBUG_LEAK)
# 返回一个对象的引用列表
gc.get_referrers()额外补充-python内存分层结构
在python中,内存管理机制被抽象成分层次的结构,从python解释器Cpython的源码obmallic.c的注释中抓取了对内存分层的描述:
/*
Object-specific allocators
_____ ______ ______ ________
[ int ] [ dict ] [ list ] ... [ string ] Python core |
+3 | <----- Object-specific memory -----> | <-- Non-object memory --> |
_______________________________ | |
[ Python's object allocator ] | |
+2 | ####### Object memory ####### | <------ Internal buffers ------> |
______________________________________________________________ |
[ Python's raw memory allocator (PyMem_ API) ] |
+1 | <----- Python memory (under PyMem manager's control) ------> | |
__________________________________________________________________
[ Underlying general-purpose allocator (ex: C library malloc) ]
0 | <------ Virtual memory allocated for the python process -------> |
=========================================================================
_______________________________________________________________________
[ OS-specific Virtual Memory Manager (VMM) ]
-1 | <--- Kernel dynamic storage allocation & management (page-based) ---> |
__________________________________ __________________________________
[ ] [ ]
-2 | <-- Physical memory: ROM/RAM --> | | <-- Secondary storage (swap) --> |
*/- 第-2层是物理内存层。
- 第-1层是操作系统虚拟的内存管理器。
- 第0层是C中的malloc、free等内存分配和释放相关的层。当申请的内存大于256K时,会调用第0层的malloc分配内存。
- 第1层和第2层是python级别的内存分配器(内存池),当申请的内存小于256K时,会由这两层来进行处理。这两层存在3个级别的内存结构:arena>pool>block,其中arena大小固定是256K,pool的固定大小是4K,而block的大小是8的整数倍,用来满足最小分配需求。
- 第3层是python对象内存分配器,也就是我们通常所用的python对象,比如:列表和字典、元组等。
python的内存这么分层设计,最根本的目的还是为了提高python的执行性能,因为如果不分层,频繁的调用malloc和free,非常的耗费系统资源,会产生性能问题。而分层之后,第1层和第2层充当了内存池的作用,根据分配的内存大小不同,交给不同的层去处理,减少了频繁的调用malloc。
总结
本文介绍了python中垃圾回收的三种方式,以及python内存的分层管理方式,属于比较深层次的python知识,不过相信也可以帮助你了解python的内存管理方式。如果在之后找工作过程中再被面试官问道"python垃圾回收机制"这样的问题,假如你能将文中的内容讲出来绝对是加分项。
