1.内存分析和处理
程序的运行离不开对内存的操作,一个软件要运行,需要将数据加载到内存中,通过CPU进行内存数据的读写,完成数据的运算。
1.1不可变数据类型VS可变数据类型
python中根据数据是否可以进行修改提供了两种不同的数据类型
⚫ 不可变数据类型:一般基本数据类型都是不可变数据类型
⚫ 可变数据类型:一般组合数据类型或者自定义数据类都是可变数据类型
怎么区分可变和不可变?为什么要有这样的规则?
PYTHON 中的一切都是对象,可以通过 id()函数查询对象在内存中的地址数据
可变数据类型是在定义了数据之后,修改变量的数据,内存地址不会发生变化
不可变数据类型是在定义了数据之后,修改变量的数据,变量不会修改原来内存地址的数据 而是会指向新的地址,原有的数据保留,这样更加方便程序中基本数据的利用率。
def chg_data_1(x):
x = 12
print("method: {}".format(x))
def chg_data_2(y):
y.append("hello")
print("method: {}".format(y))
if __name__ == '__main__':
a = 10
chg_data_1(a)
print(a)
b = [1, 2, 3]
chg_data_2(b) # 实际参数传递可变类型
print(b) # 这里的 b是多少 ?
1.2代码和代码块
PYTHON 中的最小运行单元是代码块,代码块的最小单元是一行代码
如 print(‘hello,world’)
在实际开发中python中有两种操作模式
- 交互模式
在交互模式下,每行命令是一个独立运行的代码块,每个代码块运行会独立申请一次内存,在操作过程中交互模式没有退出的情况下遵循python官方操作标准
如:对基本数据类型进行了基本优化操作,将一定范围内的数据存储在常量区以提升性能
- IDE开发模式
在 IDE 开发模式下,代码封装在模块中,通过python 命令运行模块时,模块整体作为一个代码块向系统申请内存并执行程序,执行过程中对于基本数据类型进行缓存优化操 作,通过 pycharm 工具执行上述代码测试:


1.3程序内存代码检测
python中对于内存的操作,社区开发一款比较强大的专门用于检测代码内存使用率,用于项目代码调优的模块memory_profile是一个使用较为简单,并且可视化比较直观的工具模块 通过pip install memory_profile安装即可使用
from memory_profiler import profile
@profile
def chg_data_1(x):
x = 12
print("method: {}".format(x))
@profile
def chg_data_2(y):
y.append("hello")
print("method: {}".format(y))
if __name__ == '__main__':
a = 10
chg_data_1(a)
print(a)
b = [1, 2, 3]
chg_data_2(b)
print(b)
1.4操作符号:is和==的使用
PYTHON 提供了对象操作符号 is 和内容操作符号==,用于判断对 象和对象中的值的情况。
A is B:判断对象 A 和对象 B 是否同一个内存地址,即是否同一个对象 。
A == B:判断 A 中的内容是否和 B 中的内容一致 。
不论是基本类型的数据,还是内容复杂的对象,都可以通过对象判断符号 is 和内容判断操 作符号==来进行确定
不可变数据类型的数据判断
组合数据类型的数据判断
创建的每个组合数据类型的对象都是独立的,如下面的代码中的 a 和 b 变量中分别存放了 两个不同的列表类型的对象,所以 is 判断是 False,但是值又是相同的所以 == 判断 True


引用数据类型的操作:
自定义数据类型,变量中存放的是对象在内存中的地址自定义类型的对象,每次创建同样也是在堆内存中单独创建的对象,所以 is 判断 False 但是为什么我们创建的两个 name 属性都为 tom 的对象,通过== 判断还是 Flase 呢?哪是 因为创建的对象在通过 == 判断时,会自动调用父类的__eq__()函数进行判断,默认情况下 创建的对象内部变量,使用的是对象自己的内存空间,所以==判断是 False 。

1.5引用、浅拷贝、深拷贝
对象的创建,依赖与申请的内存空间数据的加载,对象在内存中创建的过程依赖于三部分内存处理:
- 对象分配内存地址
- 引用变量分配内存地址
- 对象和引用变量之间的关联
from memory_profiler import profile
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
@profile(precision=10)
def main():
p1 = Person('lkk', 20, '男')
print(p1)
p2 = Person('lkk', 20, '男')
print(p2)
if __name__ == '__main__':
main()
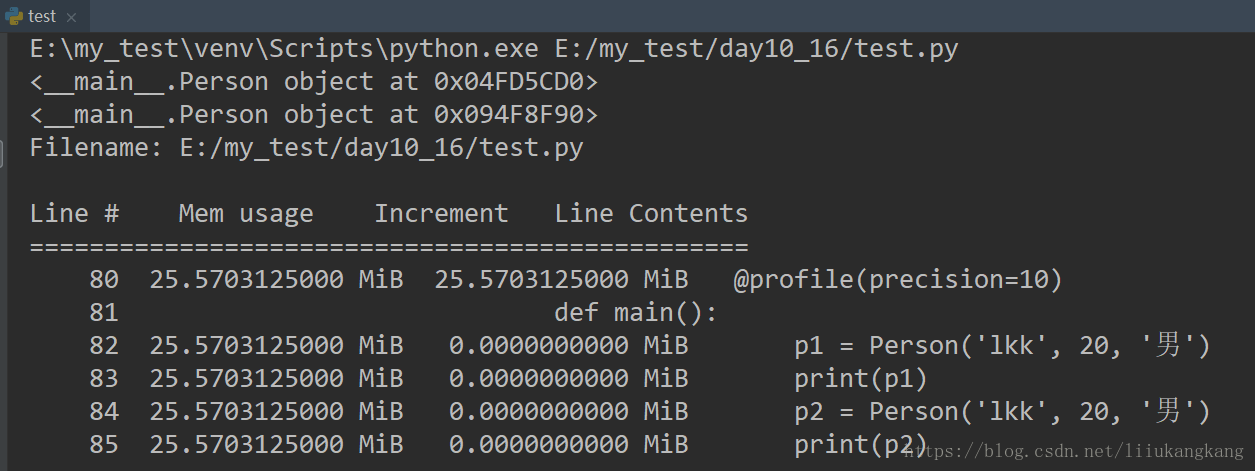
运行结果截图:
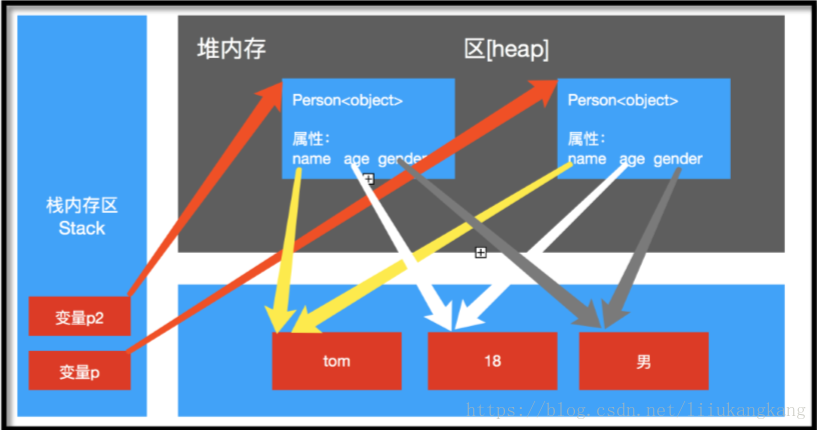
内存分配图解
由于对象的创建,是将堆内存中创建的对象的地址临时存储在栈内存中的变量中,那么在程序中如果要在多个地方使用一个对象数据时应该怎么办呢?一般想到的都是将对象像文件一样复制一份不就好了。
PYTHON 中对于这样的情况,有三种不同的操作方式
⚫ 如果程序中多个不同的地方都要使用同一个对象,通过对象的引用赋值,将同一个对象赋值给多个变量。
⚫ 如果程序中多个不同的地方都要使用相同的对象数据,通过对象的拷贝完成数据的浅拷贝即可,对象中的包含的数据要求必须统一 。
⚫ 如果程序中多个不同的地方使用相同的而且独立的对象数据,通过对象的深拷贝将对象的数据完整复制成独立的另一份即可 。
1.5.1对象的引用赋值
对象的引用赋值,可以将 对象的内存地址同时赋值给多个变量,这多个变量中存放的都是同一个对象的引用地址,如果通过一个变量修改了对象的内容,那么其他变量指向的对象内容也会同步发生改变。
对象引用变量的赋值,并不是对象的复制或者备份,而仅仅是将对象的地址存储在多个变量中方便程序操作。
注意:PYTHON 中所谓对象的引用赋值,针对的是可变类型,不论是组合数据类型或者自定 义Class类型,都具备引用赋值的操作;但是不适合不可变类型,不可变类型的引用赋值操作有只读不写的特征,一旦通过变量重新赋值就会重新指向新的引用对象。

1.5.2对象的浅拷贝
对于程序中对象的拷贝操作,除了引用赋值操作可以完成同一个人对象在程序不同位置的操作,这里的浅拷贝更是一种对象的临时备份,浅拷贝的核心机制主要是赋值对象内部数据的引用。
python内建模块copy提供了一个人copy函数可以完成。

1.5.3对象的深拷贝
和对象的浅拷贝不同,对象的深拷贝,是对象数据的直接拷贝,而不是简单的引用拷贝,主要是通过 PYTHON 内建标准模块 copy 提供的 deepcopy 函数可以完成对象深拷贝。

2.垃圾回收机制(GC/gc)
Garbage collection ----->垃圾回收机制
在 PYTHON 中的垃圾回收机制
主要是以引用计数为主要手段
以标记清除和隔代回收机制作为辅助操作手段 完成对内存中无效数据的自动管理操作的。
2.1垃圾回收机制的意义
垃圾回收机制(Garbage Collection:GC)基本是所有高级语言的标准配置之一了 在一定程度上,能优化编程语言的数据处理效率和提高编程软件开发软件的安全性能。
###2.1.1引用计数
引用计数[Reference Counting:RC]是 PYTHON 中的垃圾回收机制的核心操作算法 该算法最早是 George E.Collins 在 1960 年首次提出的,并在大部分高级语言中沿用 至今,是很多高级语言的垃圾回收核心算法之一。
(1) 什么是引用计数
引用计数算法的核心思想是:当一个对象被创建或者拷贝时,引用计数就会+1,当这个对象的多个引用变量,被销毁一个时该对象的引用计数就会-1,如果一个对象的引用计数为0则表示该对象已经不被引用,就可以让垃圾回收机制进行清除并释放该对象占有的内存空间了。
引用计数算法的优点是:操作简单,实时性能优秀,能在最短的时间获得并运算对象引用数
引用计数算法的缺点是:为了维护每个对象的引用计数操作算法,PYTHON 必须提供和对象对等的内存消耗来维护引用计数,这样就在无形中增加了内存负担;同时引用计数对于循环 应用/对象之间的互相引用,是无法进行引用计数操作的,所以就会造成常驻内存的情况。
PYTHON 是一个面向对象的弱类型语言,所有的对象都是直接或者间接继承自 object 类 型,object 类型的核心其实就是一个结构体对象
在这个结构体中,ob_refcnt 就是对象的引用计数,当对象被创建或者拷贝时该计数就会 增加+1,当对象的引用变量被删除时,该计数就会减少-1,当引用计数为 0 时,对象数据 就会被回收释放了。在 python 中,可以通过 sys.getrefcount()来获取一个对象的引 用计数

2.1.2标记清除
python中的标记—清除机制主要是针对可能产生循环引用的对象进行的检测机制。
在python中的基本不可变类型如PyIntObject,PyStringObject等对象的内部不会内聚其他对象的引用,所以不会产生循环引用,一般情况下循环引用总是发生在其他可变对象的内部属性中,如list dict
class 等等 的使得该方法消耗的资源和程序中的可变对象的数量息息相关
标记清除算法核心思想 :首先找到python中的一批根节点对象,如object对象,通过根节点对象可以找到他们指向的子节点对象,如果搜索过程中有这个指向是从上往下的指向,表示这个对象是可达的,否则该对象是不可达的,可达部分的对象在程序中需要保留下来,不可达部分的对象在程序中是不需要保留的。
2…2.3分代回收
PYTHON 中的分代回收机制,是一种通过空间换取时间效率的做法,PYTHON 内部处理机制 定义了三个不同的链表数据结构[第零代(年轻代),第 1 代(中年代),第 2 代(老年代)] PYTHON 为了提高程序执行效率,将垃圾回收机制进行了阈值限定,0 代链表中的垃圾回收 机制执行最为密集,其次是 1 代,最后是 2 代;
PYTHON 定义的这三个链表,主要是针对我们在程序中创建的对象,首先会添加到 0 代链表
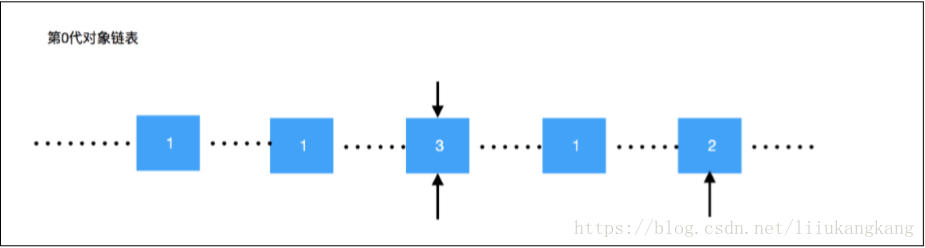
最终,触发 GC 机制将已经没有引用指向的对象进行回收,并将有引用继续
指向的对象移动到第 1 代对象链表中;第 1 代对象链表的对象,就是比第 0
代对象链表中的对象可能存活更久的对象,GC 阈值更大检测频率更慢,以提
高程序执行效率。
以此类推直到一部分对象存活在第 2 代对象链表中,对象周期较长的可能跟程序的生命周 期一样了。

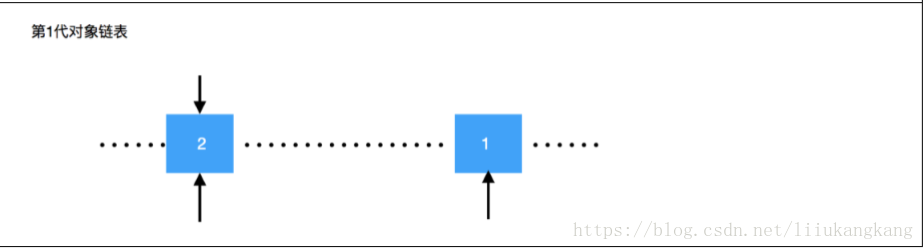
备注:弱代假说:程序中年轻的对象往往死的更快,年老的对象往往存活更久
2.3垃圾回收处理
PYTHON 中的垃圾回收机制有了一定的了解之后,我们针对垃圾回收机制的操作通过代码进 行测试 PYTHON 中的 gc 模块提供了垃圾回收处理的各项功能机制,必须 import gc 才能使用
gc.set_debug(flags):设置 gc 的 debug 日志,一般为 gc.DEBUG_LEAK gc.collect([generation]):显式进行垃圾回收处理,可以输入参数~参数表示回收的 对象代数,0 表示只检查第 0 代对象,1 表示检查第 0、1 代对象,2 表示检查 0、1、2 代 独对象,如果不传递参数,执行 FULL COLLECT,也就是默认传递 2 gc.set_threshold(threshold0 [, threshold2 [, threshold3]]):设置执行 垃圾回收机制的频率 gc.get_count():获取程序对象引用的计数器 gc.get_threshold():获取程序自动执行 GC 的引用计数阈值
以上是 PYTHON 中垃圾回收机制的基本操作,在程序开发过程中需要注意:
⚫ 项目代码中尽量避免循环引用
⚫ 引入 gc 模块,启用 gc 模块自动清理循环引用对象的机制
⚫ 将需要长期使用的对象集中管理,减少 GC 资源消耗
⚫ gc 模块处理不了重写__del__方法导致的循环引用,如果一定要添加该方法,需要显 式调用 gc 模块的 garbage 中对象的__del__方法进行处理