记忆思路:SQL的DQL语言select查询命令。
from从哪个表中where以什么条件select查询哪些列,order by是否基于某字段排序,limit # 输出多少行。
一、单表查询
1. 常用查询语法:
- SELECT 输出显示字段 FROM 表名
- 无条件查询语法:SELECT 指定输出的列 FROM 表名 ;
- 限制输出语法:SELECT 指定输出的列 FROM 表名 LIMIT 显示记录数 ;
- 条件查询语法:SELECT 指定输出的列 FROM 表名 WHRER 查询条件 ;
- 条件查询再排序:SELECT 指定输出的列 FROM 表名 WHRER 查询条件 order by 指定排序字段 [desc|asc];
- 条件查询并限制输出语法:SELECT 显示输出的列 FROM 表名 WHRER 查询条件 LIMIT 显示记录数 ;
2. SELECT过滤输出列:
- 实例一:输出显示表所有行与列,【代表所有列】
SELECT FROM students; 查询students表的所有内容- 实例二:输出显示字段以别名输出:【字段名 as 别名】注意as可以省略
SELECT name as 姓名,age as 年龄 FROM vmlab;
SELECT name 姓名,age 年龄 FROM vmlab;
3. WHERE过滤输出行:通过where限定过滤条件
- 算术操作符:+, -, *, /, %
- 逻辑操作符:NOT,AND,OR,XOR
比较操作符:=,<=>(相等或都为空), <>, !=(非标准SQL), >, >=, <, <=
select from vmlab where age >=30;
SELECT FROM students WHERE gender='m';查询所有男生
SELECT FROM students WHERE id < 3; 查询students表中id字段值小于3的所有行的所有字段
SELECT * FROM students WHERE id >=2 and id <=4;查询id大于等2小于等4的记录;- 区间取值:BETWEEN minnum AND maxnum
SELECT FROM students WHERE BETWEEN 2 AND 4;查询id大于等2小于等4的记录;- in 明确指定值:
select * from vmlab where classid in (1,3,6);- 匹配空值与非空值 :is null、is not null
select from vmlab where classid is null 匹配classid为空值的行
select from vmlab where classid is not null 匹配classid为非空值的行模糊匹配 like
% 任意长度的任意字符 ,_ 任意单个字符
SELECT * FROM students WHERE name LIKE 't%'; 基于模糊匹配查询name字段以字母t开头的所有记录- 正则表达式匹配
rlike:
SELECT FROM students WHERE name RLIKE '.[lo].';基于正则匹配查询name字段包含字母l或o的记录
REGEXP:
SELECT FROM vmlab WHERE name REGEXP '^h';
4. 分组统计:
GROUP BY根据指定的条件对查询结果进行“分组”以用于做“聚合”运算,输出字段一般为:聚合计算的字段和计算结果。
- 常用的聚合函数:count()计数、avg() 平均值、max() 最大值 、min() 最小值、sum() 求和
- HAVING: 对分组聚合运算后的结果指定过滤条件。
- 例:
select classid,gender,avg(age) from students group by classid,gender;
select classid,gender,avg(age) from students group by classid,gender having classid is not null;
5. 数据整形操作
ORDER BY: 根据指定的字段对查询结果进行排序- 升序:ASC(默认为升序)
select distinct classid from students order by classid;
select distinct classid from students order by classid asc;- 降序:DESC
select distinct classid from students order by classid desc;- 过滤显示空值
select distinct classid from students where classid is null;- 过滤不显示空值;
select distinct classid from students where classid is not null;- 去除重复列 DISTINCT
select distinct classid from students;
select from t1 union select from t1;- 为输出列定义别名
SELECT id stuid,name as stuname FROM students 查询students表中stuid、stuname字段,并将name字段以别名stuname显示输出。
6. 限制输出:
- LIMIT [[offset,]row_count]:对查询的结果进行输出行数数量限制
SELECT FROM students ORDER BY name DESC LIMIT 2; 按name字段做降序排列,并出输前2条记录
SELECT FROM students ORDER BY name DESC LIMIT 3,5; 按name字段做降序排列,并从第3记录开始输出5条记录
7. 操作实例:
1. 实例一:计算students表中男女生平均年龄,思路:用group by对性别字段进行分组,然后用avg()函数对年龄字段求平均数,最后输出性别、年龄字段计算的平均数。
select gender,avg(age) from students group by gender;
2. 实例二:计算students表中每个班级的男女生平均年龄,思路:用group by先对班级字段进行分组,再对同班级的性别做分组,然后对年龄字段求平均烽,最后输出字段为班级、性别、年龄字段计算的平均数。select classid,gender,avg(age) from students group by classid,gender;
select classid,gender,avg(age) from students group by classid,gender having classid is not null; having过滤班级为空的学生不统计。过滤条件having一定要用在group by之后,先做分组统计计算然后再做过滤。
select classid,gender,avg(age) from students where classid is not null group by classid,gender; where过滤班级为空的学生不统计。过滤条件where一定要用在group by之前,先做过滤,然后再做分组统计。
3. 实例三:分组统计完成后,用order by对指输出字段做排序,asc升序排列,desc降序排列。select classid,gender,avg(age) from students where classid is not null group by classid,gender order by avg(age) asc; asc升序排列
select classid,gender,avg(age) from students where classid is not null group by classid,gender order by avg(age) desc; desc降序排列
4. 实例四:做完分组统计、升降序排列后,做限制输出,如仅输出前100条记录,即TOP100。select classid,gender,avg(age) from students where classid is not null group by classid,gender order by avg(age) asc limit 5; 升序限制输出
select classid,gender,avg(age) from students where classid is not null group by classid,gender order by avg(age) desc limit 5; 降序限制输出
5. 实例五:利用输出字段别名定制输出表头select classid as 班级,gender as 性别,avg(age) as 平均年龄 from students where classid is not null group by classid,gender order by avg(age) asc limit 5;
6.实列六:以班级为分组计算平均年龄,并显示平均年龄大于30,且班级ID大于3select classid,avg(age) from students group by classid having avg(age) >30 and classid >3;
二、多表查询
- 子查询:查询语句中嵌入另一个查询语句,将子查询语句的结果做为父语句过滤条件或输入结果。
select name,age from students where age >(select avg(age)from students);- 纵向合并:利用union联合查询实现多表纵向合并,默认有去重功能,如果不想去重则可以用union all。
必要条件:多个表之间的合并字段数据类型必须相同,在select后的输出字段书写顺序必须都一致。
select * from teachers union select Stuid,name,age,Gender from students;- 横向合并:思路先确定哪个是主表。
a. 字段数是两个表选取字段之和
b. 记录数是两个表记录做笛卡尔乘积,即两表记录相乘,所有记录字段交叉合并,主表的每条记录与副表的每条记录分别合并。
select from students cross join teachers;
select from students,teachers;
select students.name,teachers.name,students.classid from students,teachers limit 10;输出指定字列,必须指定要指定输出哪个表的列。
select students.name as 姓名,teachers.name as 老师,students.classid 班级 from students,teachers limit 10;用字段别名定制输出表头。
select st.name as 姓名,te.name as 老师,st.classid 班级 from students as st,teachers as te limit 10;为表指定别名,然后再输写输出字段会更简洁,表一旦指定别名就必须使用。- 内连接:inner join 取两个表的交集
逻辑:基于两个表的某个或某些共有特性为依据横向合并两表,使两表内的记录基于某条件建立关联。如果不加合并条件就是做笛卡尔乘积合并。
实例:
select from students inner join teachers on students.teacherid=teachers.tid; 新式输写
select from students as s,teachers as t where s.teacherid=t.tid order by stuid;旧式输写
select s.Stuid,s.name,t.name,s.classid from students as s inner join teachers as t on s.teacherid=t.tid order by stuid; 基于表的别名定制输出字段。
select s.Stuid as 学号,s.name as 姓名,t.name as 老师,s.classid as 班级 from students as s inner join teachers as t on s.teacherid=t.tid order by stuid;为输出字段定义别名达到定制输出表头的目录。
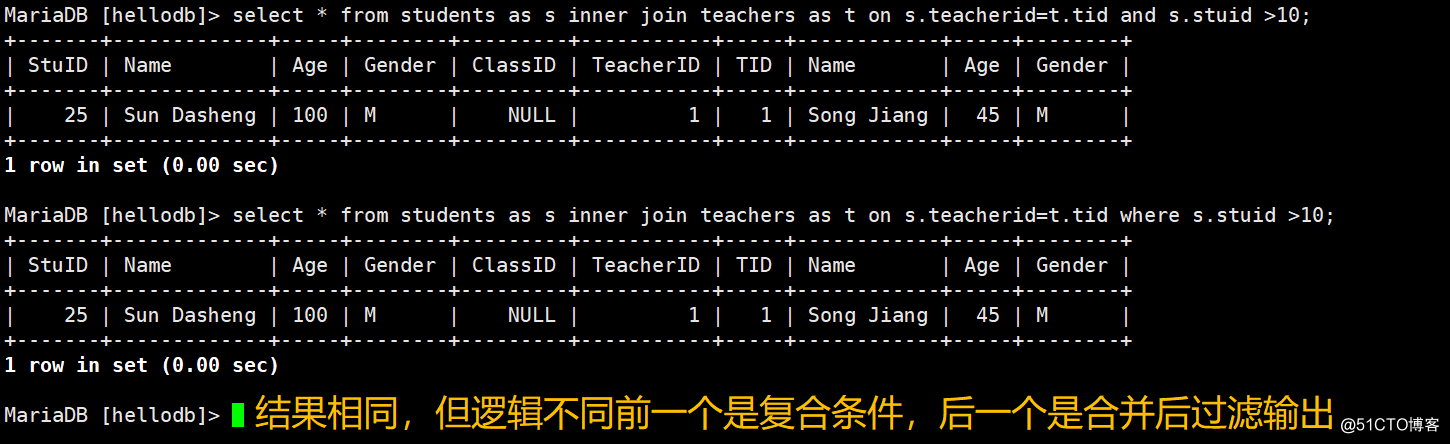
复合条件合并:
select from students as s inner join teachers as t on s.teacherid=t.tid and s.stuid >10;
select from students as s inner join teachers as t on s.teacherid=t.tid where s.stuid >10;- 外连接:
逻辑:左右是相对概念,因此在合并前先确定哪个表为主表,主表所有记录将全部输出,被吞并的表为副 表,副表的记录会被横向合并到主表中。
左外连接:设左侧为主表,所有记录将全部输出,右为副表,两表进行横向合并,将副表(右侧表)中符合合并条件的记录填写在主表(左侧表)的对应记录内,主表中其余记录不符合条件的副表,并根据需求定制输出显示字段。
select from students as s left outer join teachers as t on s.teacherid=t.tid;
左外连接特例:用where设置过滤条件,排除左右表具有某共同特性的记录,横向合并输出主表(左侧)不具有共同某特性的记录。
select from students as s left outer join teachers as t on s.teacherid=t.tid where t.tid is null;
右外连接:设右侧为主表,所有记录将全部输出,左为副表,两表进行横向合并,将左侧
select from students as s right outer join teachers as t on s.teacherid=t.tid;
右外连接特例:用where设置过滤条件,排除左右表具有某共同特性的记录,横向合并输出主表(右侧)不具有共同某特性的记录。
select from students as s right outer join teachers as t on s.teacherid=t.tid where s.teacherid is null;
完全外连接:两个表没有主副之分,两个表的记录全部输出,两表字段合并,左侧表某条记录右侧表没有值来填写时则对应字段为空,右侧表的记录左则表没有值来填充时则对应字段也为空,从而将两个表合并的同时也将两个表的记录全部输出,相当于两表互补全并,构成矩形。
完全外连接特例:排除两表的交集,保留剩余部分,即交集取反