分片(sharding)是MongoDB用来将大型数据集合分到散不同服务器使用的方法, 这样不需要功能强大的服务器就能够存储更多的数据和处理更大的负载. 基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移. 通过一个名为mongos的路由进程进行操作,mongos知道数据和片的对应关系(通过配置服务器).
基本架构

- mongos: 访问集群的入口, 其本身不持久化数据, 读写操作建议都通过该组件进行, 保证cluster多个组件处于一致的状态. 一般有多个mongos节点
- config server: 存储集群的元数据, 即各分片包含了哪些数据的信息(是一种映射, 并不保存真实的数据), 需要空间很小
- shard: 存储用户的业务数据, 可以是一个副本集也可以是单台机器, 以chunk为单位存数据
什么时候需要使用分片?
- 单台机器存储不足
- 单台机器不能满足写入数据的性能要求, 通过分片让写压力分散到各个分片上面, 使用分片服务器自身的资源
chunk是什么?
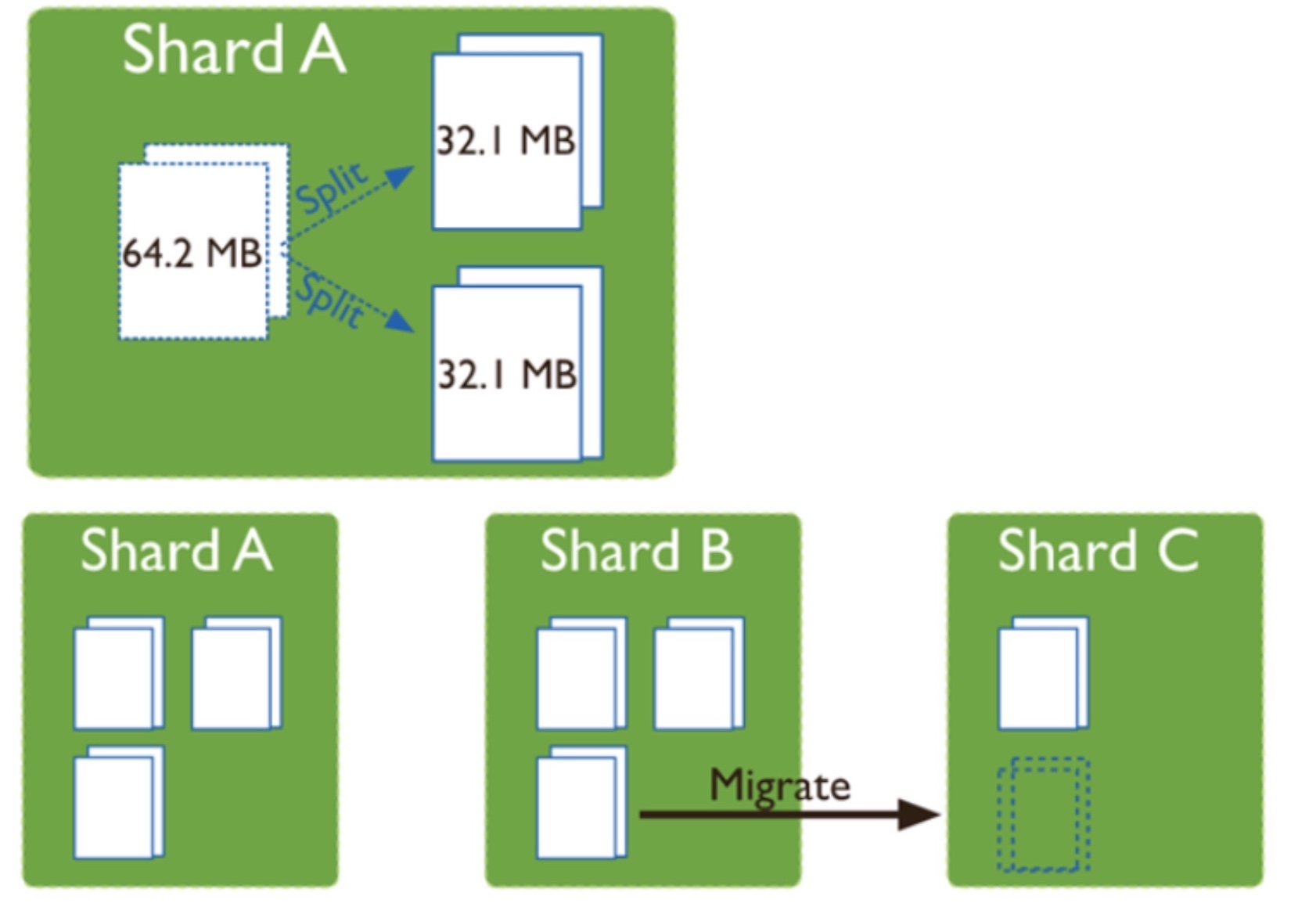
使用sharding功能后, 数据会根据shard key来把数据分割成不同的chunk放到shard服务器上. chunk(默认64M)主要有以下功能
- spliting(分裂)
写入数据时,当 chunk 上写入的数据量,超过chunk size(64M)时,mongodb后台进程就会触发 chunk 的分裂, 分割成更小的chunk, 防止单个chunk过大 - balancing(平衡)
当各个shard上chunk分布不均衡时,就会触发chunk迁移. chunk的分裂和迁移非常消耗IO资源.
chunk在写入数据时会分裂, 在读取时不会. chunksize会影响数据的迁移速度, 如果chunksize很大, 数据分裂少, 但是迁移会很慢, 还可能出现chunk内文档数过多无法迁移(chunk 内文档数不能超过 250000)
jumbo chunk
MongoDB 默认的 chunk size 为64MB,如果 chunk 超过64MB 并且不能分裂(比如所有文档 的 shard key 都相同),则会被标记为jumbo chunk ,balancer 不会迁移这样的 chunk,从而可能导致负载不均衡
数据分布
范围分片(Range based)和hash分片(Hash based)
- 范围分片
优点: 能很好满足范围查询的需求, 因为连续的数据大概率在一个shard上, 也可能在一个chunk上.
缺点: 如果分片键是连续递增的话, 新插入数据会落到一个chunk上, 如果这部分数据特别活跃, 则不能充分利用集群的性能优势. 注意: mongodb的_id高位是时间戳递增的 - hash分片
优点: 可以更好的利用集群性能
缺点: 不能快速进行范围查询
分片键
分片键决定了数据会以怎样的策略进行分布, 主要有
- 递增型
- 随机性
- 混合型
可以结合业务特点来选择合适的分片键, 同时要注意以下
- 分片键一旦设置不能取消
- 分片键必须有索引. 如果集合是非空, 必须先设置该field为索引, 才能指定为分片键
- 分片键用于路由查询
- 分片键大小限制512bytes
# 启用数据库分片:
sh.enableSharding("<database>")
# 使用hash分片键
sh.shardCollection('db.collection', {'field':'hashed'})
# 使用递增分片键
sh.shardCollection('db.collection', { field: 1})
# 查看分片是否成功
db.collection.stats().sharded
# 查看数据分布
db.collection.getShardDistribution()参考资料
