一开始没有看书没有查,自己写了一个,花了好久才调试成功:
1 bool BST::Add_Node(TreeNode* temp) { 2 if (!root) { 3 root = temp; 4 return true; 5 } 6 TreeNode* current = root; 7 while (!current->childLess()) { 8 if (temp->getData() >= current->getData()) { 9 if (current->getRightChild()) 10 current = current->getRightChild(); 11 else 12 break; 13 } 14 else if (temp->getData() < current->getData()) { 15 if (current->getLeftChild()) 16 current = current->getLeftChild(); 17 else 18 break; 19 } 20 else if (current == root) 21 break; 22 else return false; 23 } 24 if (temp->getData() < current->getData()) 25 current->setLeftChild(temp); 26 else 27 current->setRightChild(temp); 28 temp->setParent(current); 29 return true;
结点数据:
![]()
构造成功后数据结构应该如图所示:
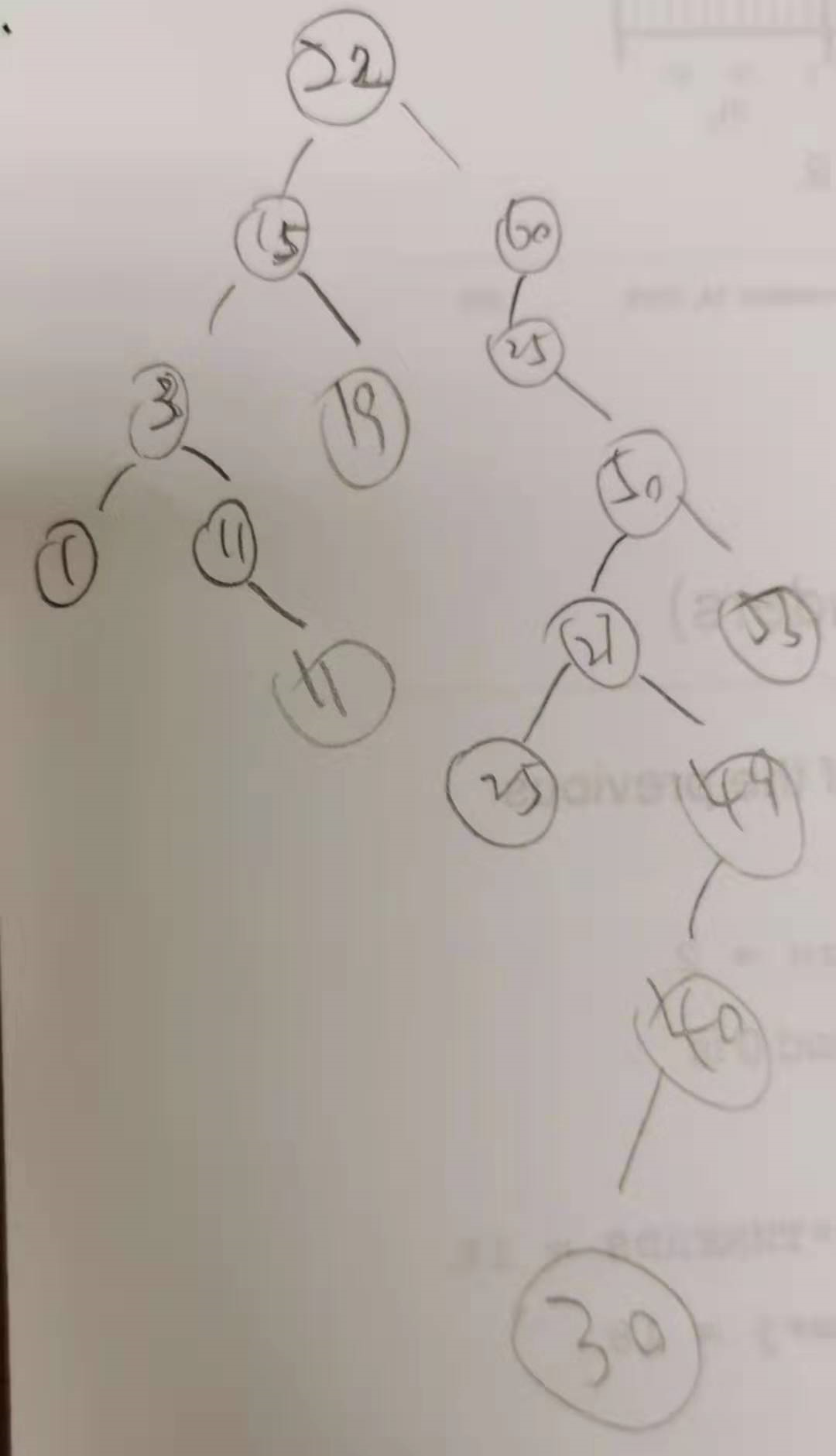
这里对于有重复键值的结点的加入是这样的:(见8-12行)允许重复值的加入,如碰到相同值的结点,则将当前指针指向这个结点的右孩子。
其实这里对二叉搜索树的定义参考的是《算法导论》,其中是允许重复值的:
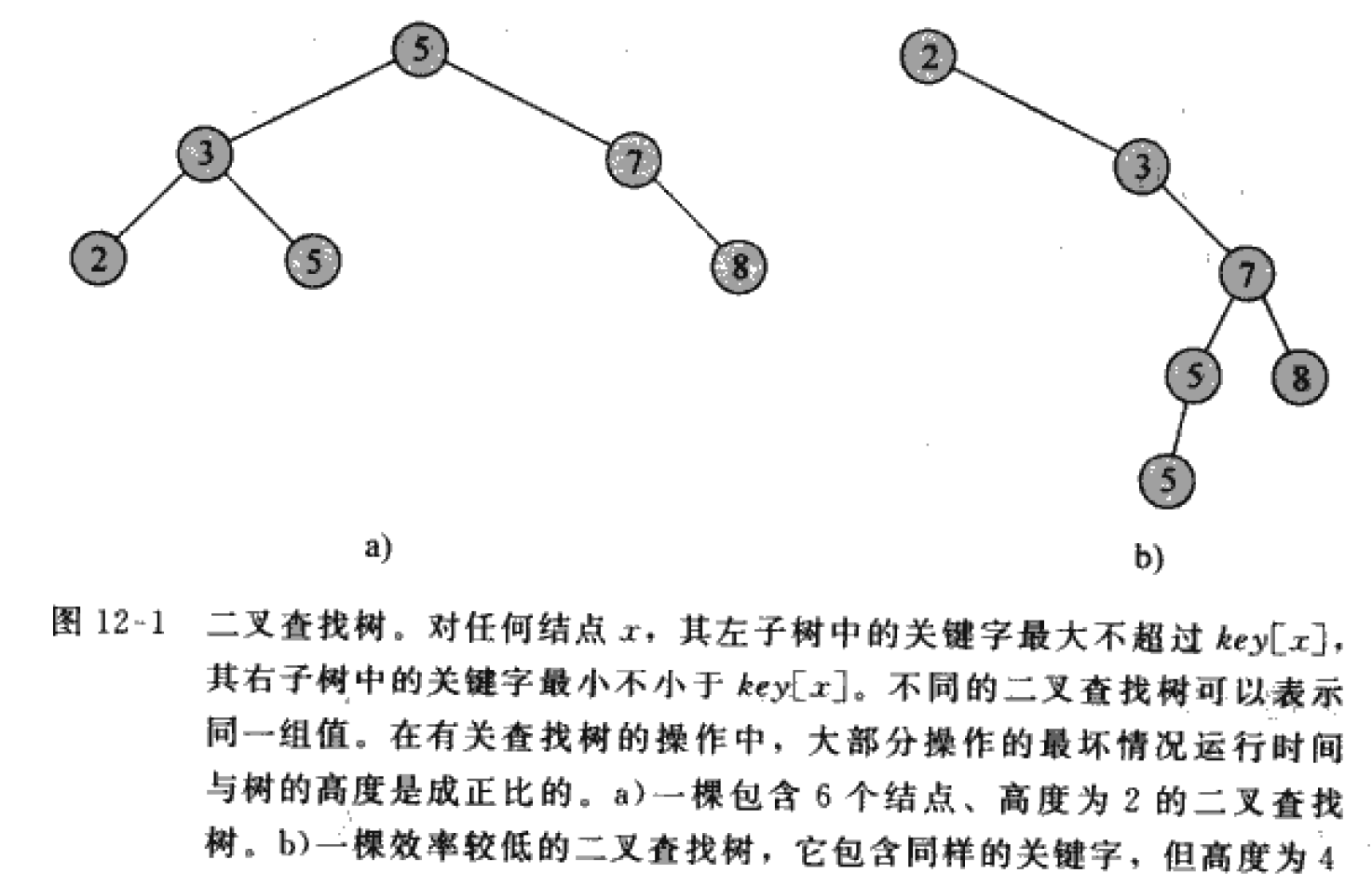
如果想排除重复值,略微修改代码即可,很容易,不再叙述。
以上算法通过先序遍历验证,成功:
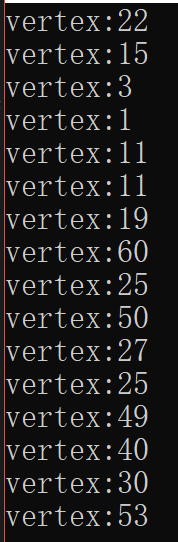
再看《算法导论》中对于结点添加算法的描述:

它用了一个辅助值y,代码要比我自己写的稍微简洁些。我们来按照这个伪代码修改一下自己的代码:
1 bool BST::Add_Node(TreeNode* temp) { 2 if (!root) { 3 root = temp; 4 return true; 5 } 6 TreeNode* assist = NULL; 7 TreeNode* current = root; 8 while (current) { 9 assist = current; 10 if (temp->getData() >= current->getData()) { 11 if (current->getRightChild()) 12 current = current->getRightChild(); 13 else 14 break; 15 } 16 else if (temp->getData() < current->getData()) { 17 if (current->getLeftChild()) 18 current = current->getLeftChild(); 19 else 20 break; 21 } 22 else return false; 23 } 24 temp->setParent(assist); 25 if (temp->getData() < current->getData()) 26 current->setLeftChild(temp); 27 else 28 current->setRightChild(temp); 29 return true; 30 }
呃,其实没什么区别···算法思路是一样的,如果当前结点值大于新的值,就走左边;如果新的值大于当前结点值,就走右边。走到底,然后把新结点加上去。
先序遍历验证以上代码,成功:
