BOOM! 一天100万条数据,5G种子文件,EpicScrapy1024轻松拿下小草网站全部种子,哈哈哈哈。
大家好,我是铲屎官,继上一篇「Python实战:用代码来访问1024网站」之后,铲屎官利用铲屎的休息时间,专门为大家做了这期Scrapy超级爬虫实战! 专门爬取小草网站的各个板块的帖子,并下载种子文件保存在本地。哎呦,真的刁到起飞哦。废话不多说,赶紧来看吧。
我们这次主要使用的核心技术,是Scrapy爬虫框架。这是一款Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。框架的结构,相信很多同学都看过这张图:
那这里就简单的说几句:
-
引擎(Scrapy):用来处理整个系统的数据流, 触发事务(框架核心)。
-
调度器(Scheduler):用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回 。
-
下载器(Downloader):用于下载网页内容, 并将网页内容返回给爬虫。
-
爬虫(Spiders):用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。
-
项目管道(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。
-
下载器中间件(Downloader Middlewares):主要是处理Scrapy引擎与下载器之间的请求及响应。
-
爬虫中间件(Spider Middlewares):主要工作是处理蜘蛛的响应输入和请求输出。
-
调度中间件(Scheduler Middewares):从Scrapy引擎发送到调度的请求和响应。
那这个东西这么牛逼,还不赶紧拿来快快用。
EpicScrapy1024开发实战
在爬取东西之前,我们需要简单分析一下小草网站的结构。爬虫,是依照URL来爬取的,那么我们首先来分析一下小草的URL吧。
1# 不骑马的日本人板块
2http://bc.ghuws.men/thread0806.php?fid=2&search=&page=2
3# 骑马的日本人板块
4http://bc.ghuws.men/thread0806.php?fid=15&search=&page=2
5# 英语老师板块
6http://bc.ghuws.men/thread0806.php?fid=4&search=&page=2
这是挑选了几个不同的板块之间的URL,我们发现,他们就是fid=XX这个数字不同啊。传入不同的page参数,应该就是第几页。这样,我们就能连续的爬取不同page之间的信息了。
爬到页面了,我们接下来就是要找每个页面的post了,这就要涉及到html的知识了。由于这些页面长的都一样,他们的结构也都是差不多的,所以,我们随便选取一个页面,来看看他post的html长什么样子。
1<td class="tal" style="padding-left:8px" id="">
2 <h3><a href="htm_data/15/1805/3140529.html" target="_blank" id="">[MP4/ 1.53G] SDMU-742 和歌山から来たリアルマゾ女子 [vip1136]</a></h3>
3</td>
找到,关键信息在这里,这个 <a> 标签里。我们看到href="htm_data/15/1805/3140529.html"这个应该就是每一个帖子的后半段URL,前半段应该是域名。最后的那个数字,应该是帖子的ID,每一个帖子都有唯一的ID与之对应。标签中包裹的文字是帖子的标题,那么好,我们就拿到这个URL来拼接出每一个帖子的地址,然后在Scrapy的Spider里面yeild出来。
1http://bc.ghuws.men/htm_data/15/1805/3140529.html
因为我们的目的是要拿到:每个帖子的标题,帖子的预览图,还有帖子的种子文件。
既然我们已经拿到了帖子的URL,那么我们就接着来爬第二层:帖子。
在每个帖子的html文件中,我们需要找到两个东西:一是缩略图,二是种子的下载地址。经过简单的点击右键,检查,发现这两个东西的html代码长这个样子:
1<!--图片-->
2<br>
3 <img src='https://imagizer.imageshack.com/v2/XXX/XXX/XXX.jpg' onclick="XXXXXX" style='cursor:pointer'>
4<br>
5<!--种子文件-->
6<a target="_blank" onmouseover="this.style.background='#DEF5CD';" onmouseout="this.style.background='none';" style="cursor:pointer;color:#008000;" href="http://www.viidii.info/?http://www______rmdown______com/link______php?hash=XXXXXX&z">http://www.rmdown.com/link.php?hash=XXXXXX</a>
这样,就可以找了图片的标签<img>和种子文件的下载地址的标签<a>,但是,这里就有个问题,每一个post的html里面,如果找<img>标签的话,会找到很多图片,好多图片都不是我们想要的,这里就得根据src里面的值来区分,我这里只是找了文件格式是非gif图片,并且只挑选了前三个作为image_url来存储起来。而种子文件的下载地址,这就是<a>标签包裹的内容就可以。
在这一层,我们拿到了post的标题,图片,还有种子文件的下载URL。那么我们下一步就是,去爬取下载种子文件的URL。这就到了爬虫的第三层。
在第三层里面,这里只有一个download按钮,所以,我们只需要看每个种子的下载地址的url就可以了。
1http://www.rmdown.com/download.php?reff=495894&ref=182a4da555f6935e11ff2ba0300733c9769a104d51c
这个URL很有意思,里面最关键的信息,就是reff和ref,然而,这两个值的位置,在网页的html文件中是可以找到的:
1<INPUT TYPE="hidden" NAME="reff" value="495894">
2<INPUT TYPE="hidden" name="ref" value="182a4da555f6935e11ff2ba0300733c9769a104d51c">
在这个文件里面,name的值为reff和ref是唯一的两个标签,这样就炒鸡好找,然后拿到他们的value值,拼凑一下,就成了电影种子文件的的下载地址。
拿到下载地址,我们就只需要用python进行网络请求,然后,将返回数据保存成torrent文件就可以了。这里有个小插曲:本来我尝试着用urllib3来做的,但是发现urllib3在网络请求的时候,会卡顿,这样很不爽,我google,发现这个问题还是很普遍的,有一个人就建议用“人类最伟大的库”requests来做请求。果然,名头不是盖的,requests轻松解决了我的烦恼,以后就粉requests了,太强大了。
OK,走到这里,我们就算是爬完了一个post,那么将爬取的信息,yield出来一个Scrapy的Item,再在pipeline中,我们将item存储到MongoDB中,就完成啦。当这一步做完,爬虫会接着爬取下一个post或者page,直到爬取结束。
过程就是这么简单,光说不练是不行滴,尤其是咱们 程序员,既得会纸上谈兵,又得会实战操练。那么我们就看一下运行时的效果,绝对震撼:

EpicScrapy1024运行效果
就看到一条一条的item在产生,一个一个的torrent文件在本地磁盘保存,console里面一行一行的打印log。内心那个,酸爽。果真是,有了爬虫,简直就是有了天下。哈哈哈哈哈
好了,下面是运行了30分钟,爬取小草网站5个板块的战果:


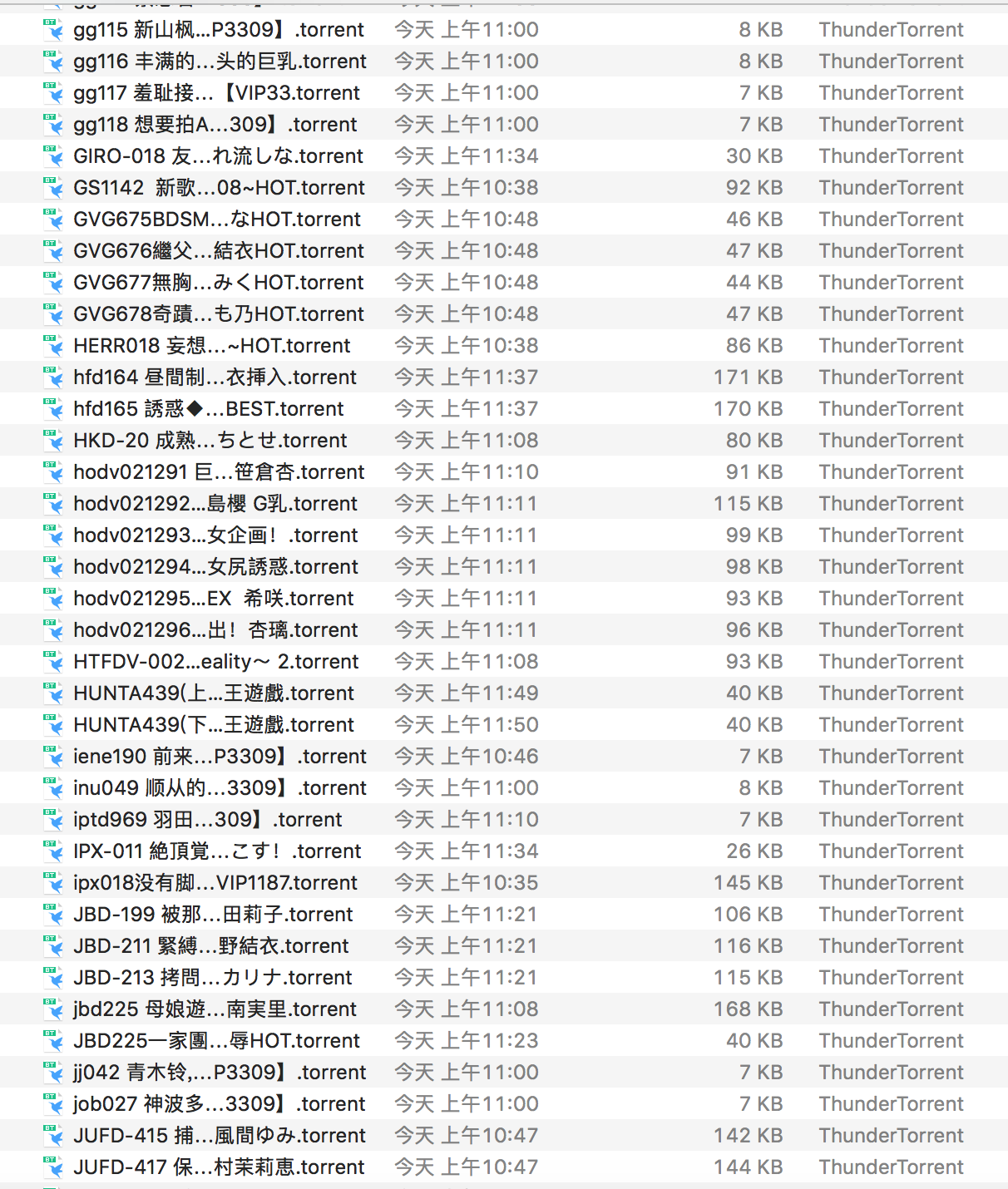

看到这里是不是心动了啊?想不想看代码啊?我认为学习一门编程语言,最简洁的方式就是去看别人写的好的源码,这样进步最快。想要获取EpicScrapy1024的源码,只需要关注公众号“皮克啪的铲屎官”,回复“1024爬虫”就可以获得惊喜!源码 + 使用说明。而且,多试几次,公众号里面有彩蛋,可能有意外惊喜哦~
至于下载的速度,这个根据你个人网络状况来定。网络如果好的话,可以多开一些请求进程。这样下载速度更疯狂。最后来扯一点这个项目中用到的关键技术吧。
技术要点
-
Python 3.6
-
Scrapy
-
在Scrapy发起网络请求的时候,为了避免被网站封杀,我们这在request里添加了Cookie和User-Agent。
-
用BeautifulSoup4来做html的解析,因为我发现,Scrapy提供的selector不是很好用,不如bs4强大。
-
settings.py中的
DOWNLOAD_DELAY需要设置一下。 -
存入MongoDB的时候,按照不同的板块存到不同的表里。
-
在本地建一个txt文件,将结果按照csv格式写入,这样做是为了将爬取结果实时的记录下来,而不是等待爬虫运行完之后,再将结果写成csv文件。方便为其他程序提供数据。
-
torrent文件的名字需要做处理,因为帖子的标题里面有些非法字符是不能做文件路径的,所以要对名字做一下处理。
-
大概就是这些了。。。
个人感觉,Python的意义就是简单,方便,好玩。而且,要拿Python来干能够提升自己效率的事儿。比如下载种子,整合网站信息,为的都是节约自己宝贵的时间。现在这个年代,时间就是成本,时间就是金钱,做程序员的,就要发挥出程序员的优势,用程序,代码,来为自己节省时间,赚钱。
最后来一波福利:喜欢文章的朋友,铲屎官想请您帮忙分享一下,让更多的人来了解Python,学习Python,体会Python带来的乐趣。您也可以留言评论,分享您学习Python的感受。您的分享,就是对我最大的支持。
关注公众号“皮克啪的铲屎官”,回复“1024爬虫”就可以获得惊喜!也可以试一试回复“1024”哦~
Python并没有结束,随之而来的,是一大波Pyton项目,关注公众号,尽请期待。
